Essential Tools: Git
This course focuses on developing practical skills in working with data and providing students with a hands-on understanding of classical data analysis techniques.
This will be a coding-intensive course.
Instruction in this course uses Python, since it allows for fast prototyping and is supported by a great variety of scientific (and, specifically, data related) libraries. See the Introduction to Python lecture for a Python refresher.
The course notes can be found under this GitHub account. Rendered versions of the course notes can be found here.
The lecture notes of this course are rendered from Quarto markdown files. The homeworks of this course are Jupyter notebooks.
Today’s Agenda is a review of the essential tools you will need for this course.
We are not providing a comprehensive introduction to these tools.
They are all extensively documented online and you will need to familiarize with online resources to learn what you need.
Stack overflow, etc, is also your friend – but as a reference, not as a way to solve homework problems!
The key tools you will need are:
- Git
- Pandas
- Scikit-Learn
Git
One of the goals of this course is make you familiar with the modern workflow of code-versioning and collaboration.
If you don’t have it already, download git from here.
If you don’t already have one, you must also create an account on GitHub.
You can find extensive documentation on how to use git on the Git home page, the Help Pages of Github, on Atlassian, and many other sites.
Importance of using Git
In software development, the use of Git is crucial for several reasons.
- Version Control: Git allows you to track changes in your codebase over time. This means you can revert to previous versions if something goes wrong, compare changes, and understand the history of your project.
- Collaboration: Multiple developers can work on the same project simultaneously without interfering with each other’s work. Git manages and merges changes efficiently.
- Backup: Your code is stored in a repository, which can be hosted on platforms like GitHub, GitLab, or Bitbucket. This provides a backup in case your local files are lost or corrupted.
- Branching: Git’s branching model allows you to create separate branches for new features, bug fixes, or experiments. This keeps the main codebase stable and clean.
- Integration: Git integrates well with various CI/CD (continuous integration/continuous development) tools, enhancing automated testing, deployment, and overall DevOps practices.
Working with Git
We will now introduce the following topics:
- Git configuration
- Repository creation
- Staging and committing files
- Modifying files
- Recovering old versions
- Branching
- Pull requests
Configuration
The first time we use git on a new machine, we need to configure our name and email
$ git config --global user.name "Taylor Swift"
$ git config --global user.mail "tswift@bu.edu"Use the email that you used for your GitHub account.
Creating a Repository
After installing Git, we can configure our first repository. First, let’s create a new directory.
$ mkdir thoughts
$ cd thoughtsNow, we can create a git repository in this directory.
$ git initWe can check that everything is set up correctly by asking git to tell us the status of our project.
$ git status
On branch main
No commits yet
nothing to commit (create/copy files and use "git add" to track)Staging
Now, create a file named science.txt, edit it with your favorite text editor and add the following lines.
Starting to think about dataIf we check the status of our repository again, git tells us that there is a new file.
$ git status
On branch main
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
science.txt
nothing added to commit but untracked files present (use "git add" to track)To give you precise control about what changes are included in each revision, git has a special staging area.
In the staging area it keeps track of things that you have added to the current change set but not yet committed.
git add puts things in this area.
The “untracked files” message means that there’s a file in the directory that git isn’t keeping track of. We can tell git that it should do so using git add
$ git add science.txtand then check that the file is now being tracked
$ git status
On branch main
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: science.txt
git now knows that it’s supposed to keep track of science.txt, but it hasn’t yet recorded any changes.
Committing
The command git commit copies the staged changes to long-term storage (as a commit). The graphic below illustrates this process.
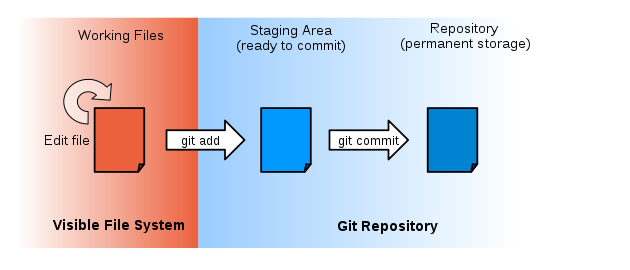
To commit our file, we run the command.
$ git commit -m "Added initial science text file"
[main (root-commit) f516d22] Added initial science text file
1 file changed, 1 insertion(+)
create mode 100644 science.txtWhen we run git commit, git takes everything we have told it to save by using git add and stores a copy permanently inside the special .git directory.
This permanent copy is called a revision and its short identifier is f516d22. (Your revision will have another identifier.)
We use the -m flag (for “message”) to record a comment that will help us remember later on what we did and why.
If we just run git commit without the -m option, git will launch an editor such as vim (or whatever other editor we configured at the start) so that we can write a longer message.
If we run git status now
$ git status
On branch main
nothing to commit, working tree cleanit tells us everything is up to date. If we want to know what we’ve done recently, we can ask git to show us the project’s history using git log.
$ git log
Author: Taylor Swift <tswift@bu.edu>
Date: Sun Jan 25 12:48:44 2015 -0500
Added initial science text fileCommit messages
When working on software engineering projects you will need to write good committ messages. Good commit messages are essential for maintaining a clear project history. A good commit message provides context for the changes in the code. The changes themselves can be seend in the committ.
Here are some tips that are detailed further in this blog post.
- Be Descriptive: Clearly explain what changes were made and why. This helps others (and your future self) understand the purpose of the commit.
- Use the Imperative Mood: Start with a verb, like “Add,” “Fix,” “Update,” etc. For example, “Fix login bug” or “Add user authentication.”
- Keep It Concise: The first line should be a brief summary (50 characters or less). If more detail is needed, add a blank line followed by a more detailed explanation.
- Reference Issues or Tickets: If your commit addresses a specific issue or ticket, reference it in the message. For example, “Fix login bug (#123).”
Changing a file
Now, suppose that we edit the file.
Starting to think about data
I need to attend ds701Now if we run git status, git will tell us that a file that it is tracking has been modified:
$ git status
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: science.txt
no changes added to commit (use "git add" and/or "git commit -a")The last line is the key phrase: “no changes added to commit”.
We have changed this file, but we haven’t told git we will want to save those changes (which we do with git add) much less actually saved them.
Let’s double-check our work using git diff, which shows us the differences between the current state of the file and the most recently saved version.
$ git diff
diff --git a/science.txt b/science.txt
index 0ac4b7b..c5b1b05 100644
--- a/science.txt
+++ b/science.txt
@@ -1 +1,2 @@
Starting to think about data
+I need to attend ds701OK, we are happy with that, so let’s commit our change.
$ git commit -m "Added line about related course"
On branch main
Changes not staged for commit:
modified: science.txt
no changes added to commitWhoops! Git won’t commit the file because we didn’t use git add first. Let’s fix that.
$ git add science.txt
$ git commit -m "Added line about related course"
[main 1bd7277] Added line about related course
1 file changed, 1 insertion(+)Git insists that we add files to the set we want to commit before actually committing anything because we may not want to commit everything at once.
For example, suppose we’re adding a few citations to our project. We might want to commit those additions, and the corresponding addition to the bibliography, but not commit the work we’re doing on the analysis (which we haven’t finished yet).
Recovering old versions
We can save changes to files and see what we have changed. How can we restore older versions however? Let’s suppose we accidentally overwrite the file but didn’t stage the changes.
$ echo "Despair! Nothing works" > science.txt
$ cat science.txt
Despair! Nothing worksNow, git status tells us that the file has been changed, but those changes haven’t been staged.
$ git status
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: science.txt
no changes added to commit (use "git add" and/or "git commit -a")We can put things back the way they were by using git checkout.
$ git checkout -- science.txt
$ cat science.txt
Starting to think about data
I need to attend ds701Recovering old versions, continued
What if we changed it and checked it in?
$ echo "Despair! Nothing works" > science.txt
$ cat science.txt
Despair! Nothing works
$ git add science.txt
$ git commit -m "Added exclamation"We have a new commit, but we want to go back to the previous version.
We have two options:
Option 1: Undo the commit and unstage the changes
$ git reset --soft HEAD~1Now do git status.
$ git status
On branch main
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: science.txtOption 2: Throw away the changes we have made and go back to the last commit
Let’s commit the changes.
$ git commit -m "oops again"But now we want to throw away the commit.
$ git reset --hard HEAD~1
$ cat science.txt
Starting to think about data
I need to attend ds549
$ git status
On branch main
nothing to commit, working tree cleanGitHub
Systems like git allow us to move work between any two repositories.
In practice, though, it’s easiest to use one copy as a central hub (origin), and to keep it on the web rather than on someone’s laptop. Most programmers use hosting services like GitHub to hold those master copies.
For the purpose of our course, we will be using GitHub to host the course material.
You will also submit your homeworks through this platform.
Next, we will cover how you can clone the course’s repository and how to submit your solutions to the homework.
For more information on how to create your own repository on GitHub and upload code to it, please see Start your journey – Learn the basics of GitHub.
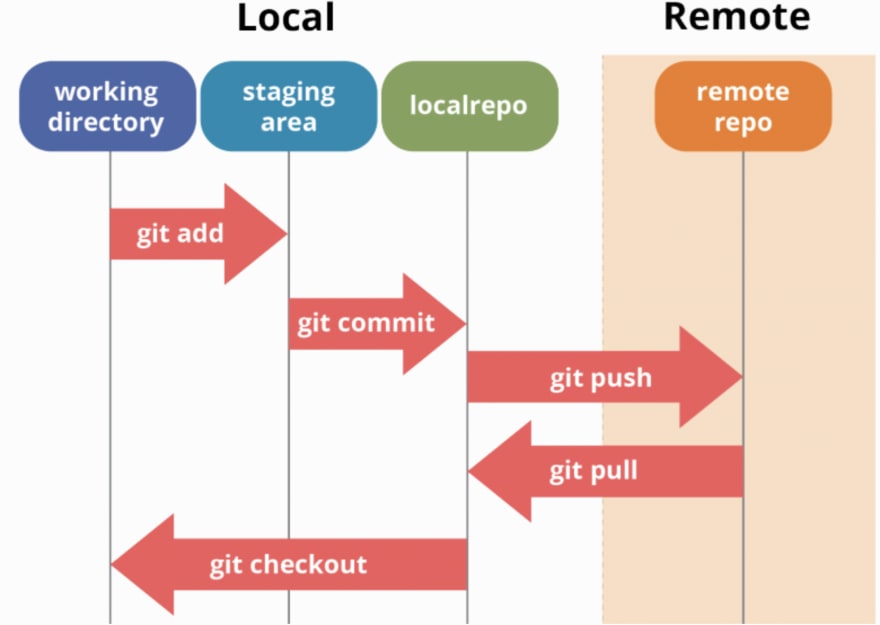
To be more accurate, the figure should indicate another lollipop which is the local copy of the remote repository.
This workflow shows you the essential new commands:
git pullgit push
And when you first copy a remote repository, you will use:
git clone
Git pull
The git pull command is used in Git to update your local repository with changes from a remote repository. Essentially, it combines two other commands: git fetch and git merge.
Here’s a breakdown of what happens when you run git pull:
- Fetch Changes: It first fetches the changes from the remote repository, updating your local copy of the remote branches.
- Merge Changes: It then merges these changes into your current local branch. This means that git pull will bring your local branch up to date with the remote branch, incorporating any new commits that have been made.
Git push
The git push command is used to upload the content of your local repository to a remote repository. This is how you transfer commits from your local repository to a remote one, making your changes available to others.
Here’s a breakdown of what happens when you run git push:
- Specify Remote and Branch: You typically specify the remote repository (e.g.,
origin) and the branch you want to push (e.g.,main). - Upload Commits: It uploads your local commits to the remote repository, updating the remote branch with your changes.
- Synchronize Repositories: This ensures that the remote repository has the latest changes from your local repository.
For example, the command git push origin main pushes your local main branch to the main branch on the remote repository named origin.
Git clone
The git clone command is used to create a copy of an existing Git repository. This repository can be hosted on platforms like GitHub, GitLab, or Bitbucket, or it can reside on a local or remote server.
Here’s what happens when you run git clone:
- Copy Repository: It copies all the data from the specified repository to your local machine, including the entire history and all branches.
- Create Directory: It creates a new directory named after the repository (unless you specify a different name).
- Set Up Remote Tracking: It sets up remote-tracking branches for each branch in the cloned repository, allowing you to fetch and pull updates from the original repository.
For example, the command git clone https://github.com/user/repo.git will clone the repository located at that URL into a directory named repo.
Branching
Branches in Git are like parallel universes for your code. They allow you to:
- Develop Features Independently: You can create a new branch for each feature or bug fix. This isolates your work from the main codebase until it’s ready to be merged.
- Experiment Safely: You can try out new ideas without affecting the main project. If the experiment fails, you can simply delete the branch.
- Collaborate Efficiently: Team members can work on different branches simultaneously. Once their work is complete, branches can be merged back into the main branch (often called main or master).
It is a best practice when working on large software engineering projects to adopt a branching convention. A very well-used and widely adopted branching model is described in this fantastic blog post by Vincent Driessen.
To create a branch called develop that branches off of main, you run the command
$ git checkout -b develop main
Switched to a new branch "branch"If you are already on the main branch you can also run the command
$ git checkout -b develop
Switched to a new branch "branch"Don’t forget to add the “-b” flag when you create the branch.
The main idea behind a branching model is to collaborate efficiently and avoid merge conflicts. You will in general have the following branches:
- Main branch: Contains production ready code. This branch is only ever modified through pull requests from the develop branch.
- Develop branch: Branches off from main and contains code that reflects latest delivered development changes. This branch is only ever modified through pull requests from feature branches.
- Feature branches: Branch off from develop and contain code that develop new features. These branches are eventually merged back into the develop branch.
Pull requests
A pull request (PR) is a way to propose changes to a codebase. When you create a pull request, you’re asking the repository maintainers to review and merge your changes into the main branch. It’s a formal way to submit your work for consideration.
Key Components of a Pull Request
- Title and Description: Clearly describe what the pull request does. This helps reviewers understand the purpose and scope of the changes.
- Commits: A pull request includes one or more commits that contain the actual changes. Each commit should have a meaningful message.
- Diff: This shows the differences between the source branch (where the changes were made) and the target branch (where the changes will be merged). Reviewers can see exactly what lines of code were added, modified, or deleted.
- Reviewers: You can request specific team members to review your pull request. They can leave comments, suggest changes, and approve or reject the PR.
- Checks and Statuses: Automated tests and other checks can be run on the pull request to ensure the changes don’t break anything. The status of these checks is visible in the PR.
Why Pull Requests are Important
- Code Review: Pull requests facilitate code reviews, which are essential for maintaining code quality. Reviewers can catch bugs, suggest improvements, and ensure that the code adheres to the project’s standards.
- Collaboration: They provide a structured way for team members to collaborate on code. Discussions can happen directly in the pull request, making it easier to track feedback and changes.
- Documentation: Pull requests serve as a historical record of changes. They document why certain changes were made and who approved them, which is valuable for future reference.
- Integration: Pull requests can be integrated with CI/CD pipelines to automatically run tests and deploy code, ensuring that only high-quality code is merged into the main branch.
Creating a Pull Request
- Branching: First, create a new branch for your changes.
- Commit Changes: Make your changes and commit them to your branch.
- Open a PR: Go to the repository on GitHub, navigate to the “Pull requests” tab, and click “New pull request.” Select your branch and the branch you want to merge into, then fill out the title and description.
- Request Review: Add reviewers and any necessary labels or milestones.
- Address Feedback: Reviewers will leave comments and request changes if needed. Make the necessary updates and push them to your branch.
- Merge: Once the PR is approved and all checks pass, you can merge it into the main branch.
Course repositories
The material of the course is hosted on GitHub, under this account.
In order to download a copy of the lectures and run them locally on your computer, you need to clone the lecture repository. To do that:
- Create a new folder for the course.
$ mkdir ds701
$ cd ds701- Copy the clone url from the repository’s website.
- Clone the repository from git.
$ git clone https://github.com/tools4ds/DS701-Course-Notes.gitYou should now have a directory with the course material.
To update the repository and download the new material, type
$ git pullGit Merge
How it works: Combines the changes from one branch into another by creating a new “merge commit” that has two parent commits:
- one from the current branch and
- one from the branch being merged.
Pros:
- Preserves history: Keeps the history of both branches intact, making it easy to trace back through the commit history.
- Contextual clarity: The merge commit provides a clear indication that branches have been combined.
Cons:
- Messy history: Can create a cluttered commit history with many merge commits, especially if the main branch is very active.
Git Rebase
How it works: Moves or combines a sequence of commits to a new base commit. It re-applies the changes from one branch on top of another branch, effectively rewriting the project history.
Pros:
- Cleaner history: Creates a linear commit history, making it easier to read and understand.
- Simplifies debugging: A linear history simplifies the use of tools like git bisect for debugging.
Cons:
- Rewrites history: Can be dangerous if not used carefully, especially on shared branches, as it rewrites commit history.
Merge vs. Rebase
Use git merge:
- When you want to preserve the complete history of changes.
- When working in a collaborative environment where multiple developers are working on the same branch.
- When you need to resolve conflicts between branches.
Use git rebase:
- When you want a cleaner, linear commit history.
- When working on a feature branch that hasn’t been shared with others yet.
- When you need to incorporate upstream changes into your feature branch before merging it back into the main branch.
Exercise
Here’s an exercise to get you started with GitHub and practice the concepts we have covered so far.
Go to your page on GitHub, e.g. https://github.com/your-github-username.
Click on the + on the upper right corner of the page and select New repository.
Call it “learn-github”.
Leave the repository public.
Select the checkbox Add a README file.
Click on Create repository.
Because we created this repository with a README file, GitHub automatically added it to the repository and so the repository is not empty.
To clone the repository, click on <> Code and copy the URL.
Then, clone the repository from git.
$ git clone https://github.com/your-github-username/learn-github.git
$ cd learn-githubNow you can start working on the repository.
Try:
- Create a new branch
- Add a new file text file to the repository and add some text to it.
- Add and commit the changes.
- Push the changes to the repository.
- Create a pull request.
- Merge the pull request and delete the branch on GitHub.
- Pull the changes to your local repository.
- Delete the branch from your local repository.
Recap
In this lecture, we covered the following topics:
- Configuring git
- Creating a repository
- Staging and committing files
- Modifying files
- Recovering old versions
- Branching
- Pull requests
- Merge vs. Rebase