NN III – Stochastic Gradient Descent, Batches and Convolutional Neural Networks
Recap
![]()
We have covered the following topics
- Gradients, gradient descent, and back propagation
- Fully connected neural networks (Multi-Layer Perceptron)
- Training of MLPs using back propagation
Now we cover
- Stochastic gradient descent (SGD)
- Convolutional Neural Networks (CNNs)
- Training a CNN with SGD
Stochastic Gradient Descent
Batches and Stochastic Gradient Descent
- Compute the gradient (e.g., forward pass and backward pass) with only a random subset of the input data.
This subset is called a batch.
- Work through the dataset by randomly sampling without replacement. This is the stochastic part.
- One forward and backward pass through all the batches of data is called an epoch.
The squared error loss for (full-batch) gradient descent for \(N\) input samples is
\[ L = \sum_{i=1}^{N} \ell_i = \sum_{i=1}^{N} \left( y_i - \hat{y}_i \right)^2. \]
In Stochastic Gradient Descent, the loss is calculated for a single batch of data, i.e.,
\[ L_t = \sum_{i \in \mathcal{B}_t} \ell_i = \sum_{i \in \mathcal{B}_t} \left( y_i - \hat{y}_i \right)^2, \]
where \(\mathcal{B}_t\) is the \(t\)-th batch.
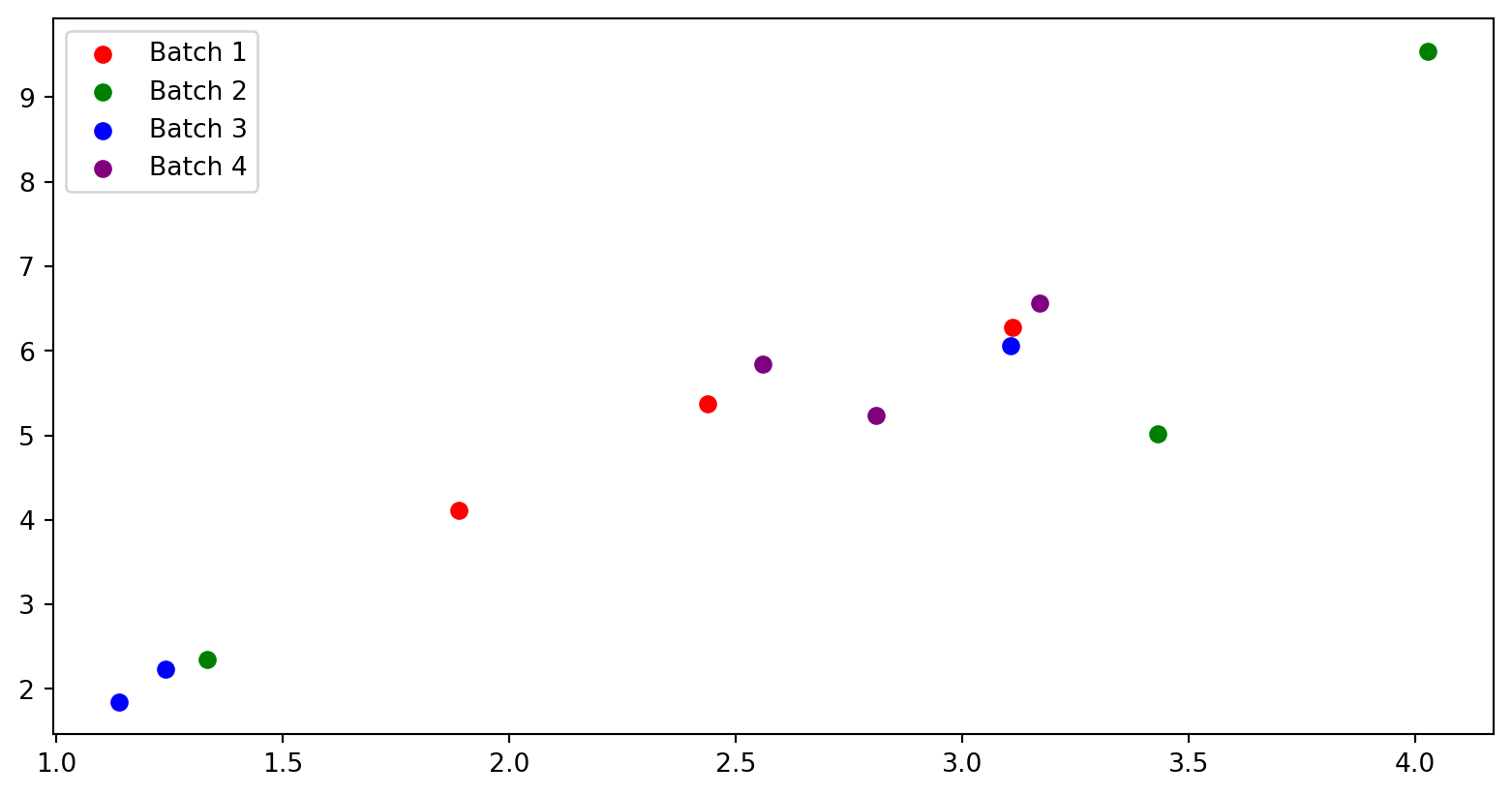
Here is an example.
Given a training data set of 12 points and we want to use a batch size of 3.
The 12 points are divided into batches of 3 by randomly selecting points without replacement.
The points can be resampled again to create a different set of batches.
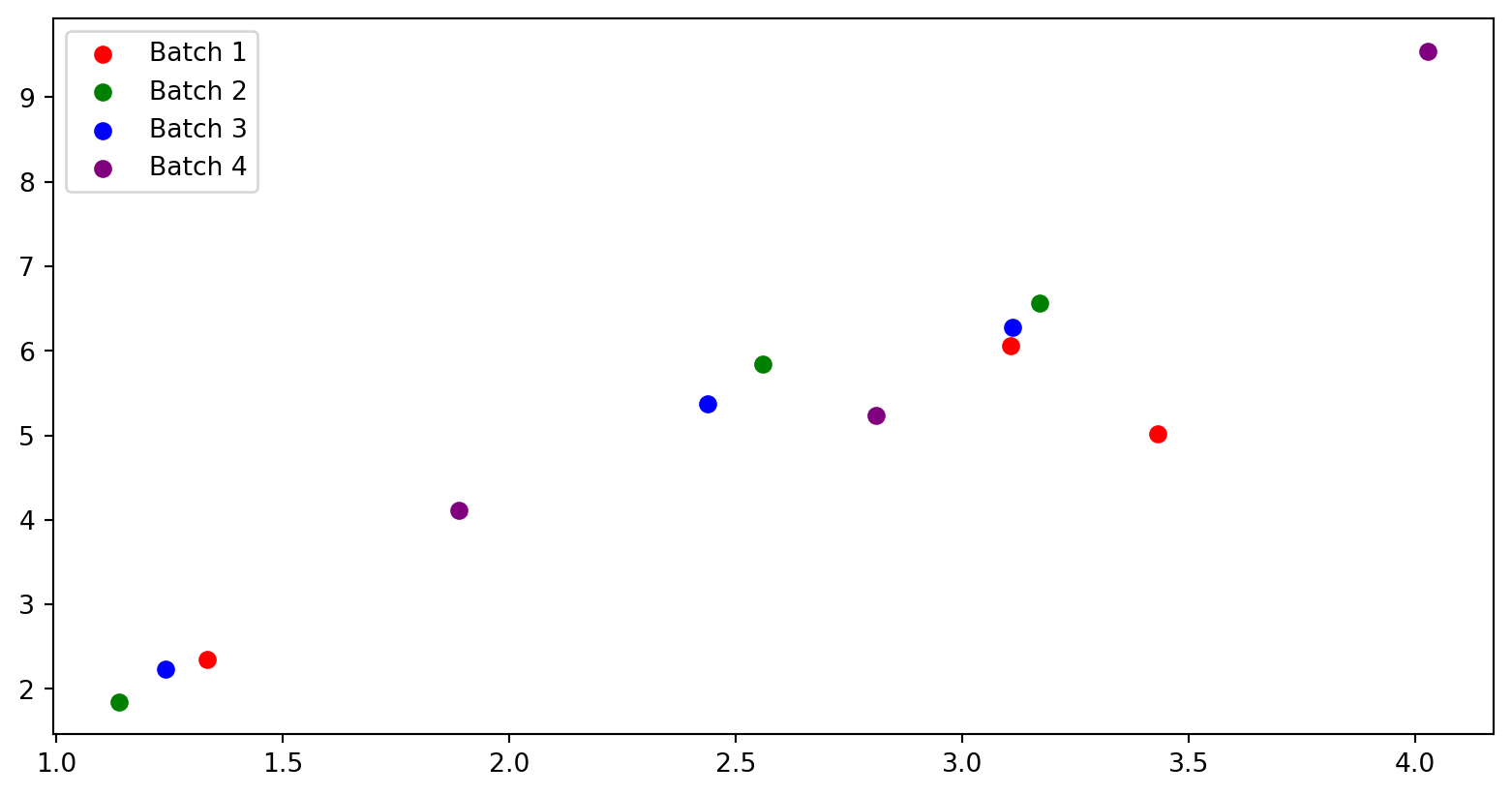
For every training iteration, you calculate the loss after a forward and backward pass with the data from a single batch.
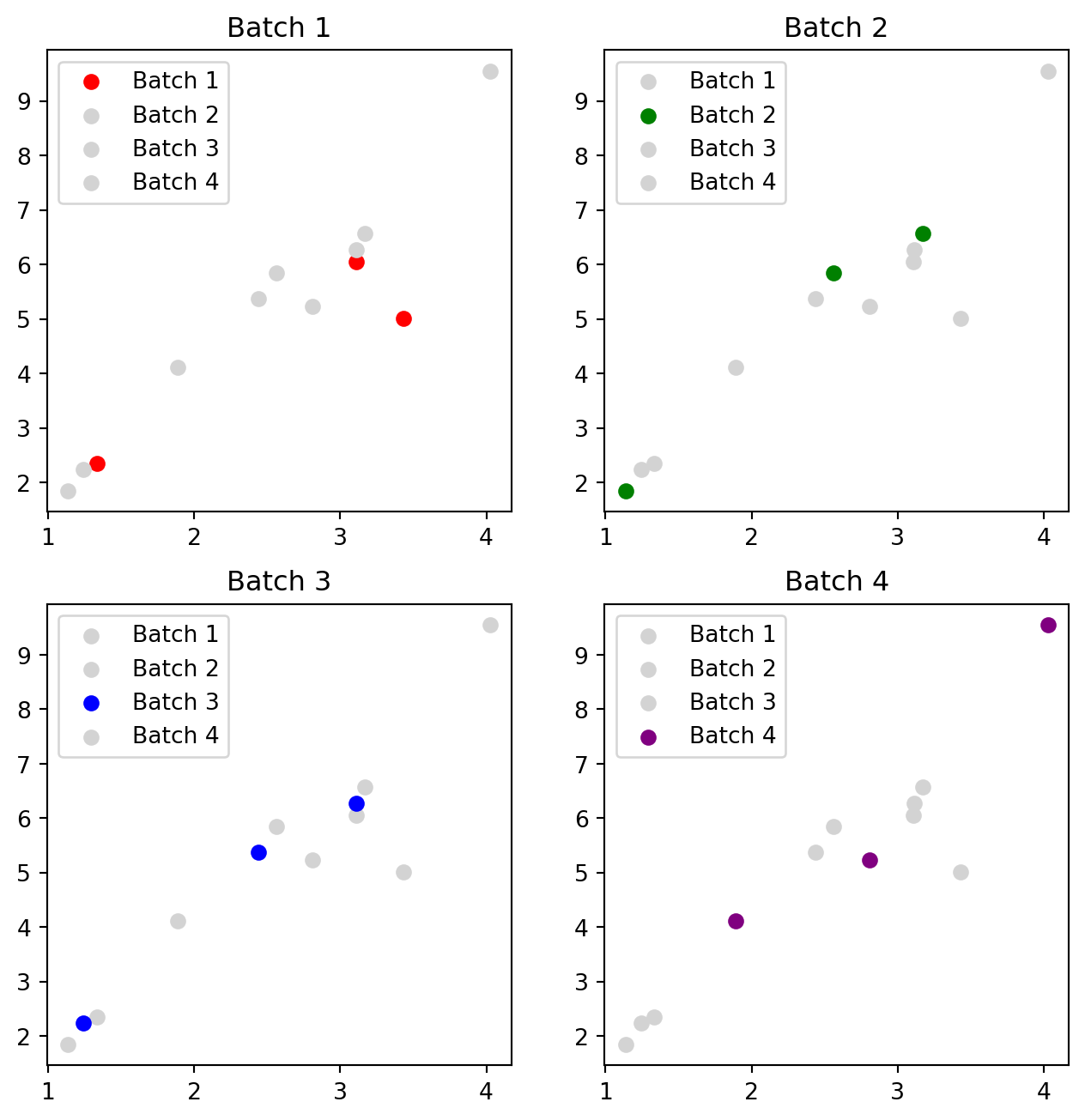
Vocabulary Summary
We have introduced the following terms:
- batch - a subset of the full training data
- batch size - the number of data points in the batch
- iteration - a forward and backward pass with a single batch of data
- epoch - a forward and backward pass over all the batches of data.
With 12 instances of data split into 4 batches, the batch size is 3, and it takes 4 iterations for a single epoch.
Advantages of SGD
There are two main advantages to Stochastic Gradient Descent.
- Avoid reading and computing on every input data sample for every training iteration.
- Speeds up the iterations while still making optimization progress.
- Works better with limited GPU memory and CPU cache. Avoid slow downs by thrashing limited memory.
- Improve training convergence by adding noise to the weight updates.
- Possibly avoid getting stuck in a local minima.
Consider the following example.
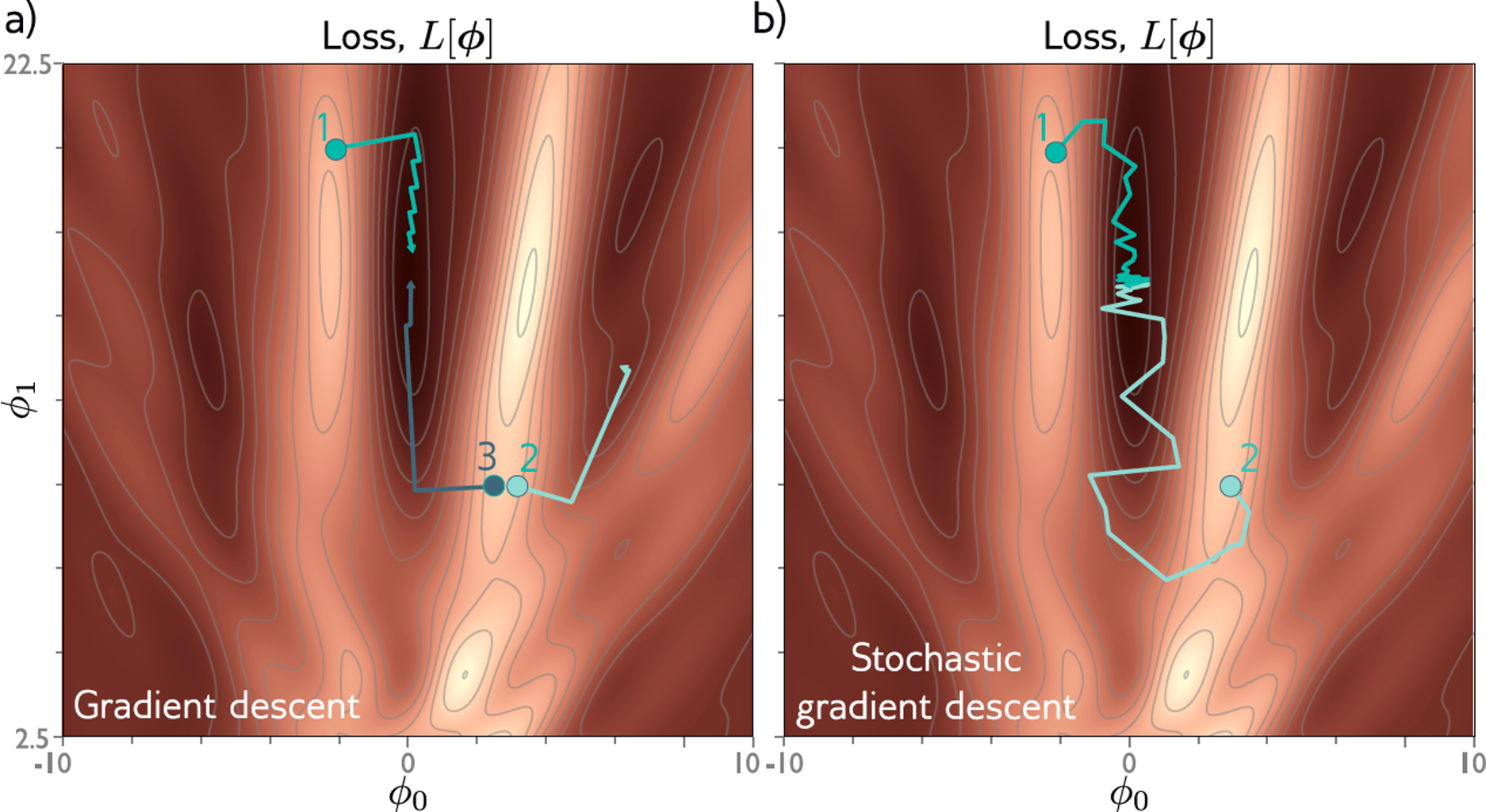
This contour plot shows a loss surface for a model with only 2 parameters.
With full-batch gradient descent, starting points 1 and 3 converge to the global minimum, but starting point 2 gets stuck in a local minimum.
With SGD, starting point 1 converges to the global minimum. However, starting point 2 now avoids the local minimum and converges to the global minimum.
Load an Image Dataset in Batches in PyTorch
DataSet and DataLoader
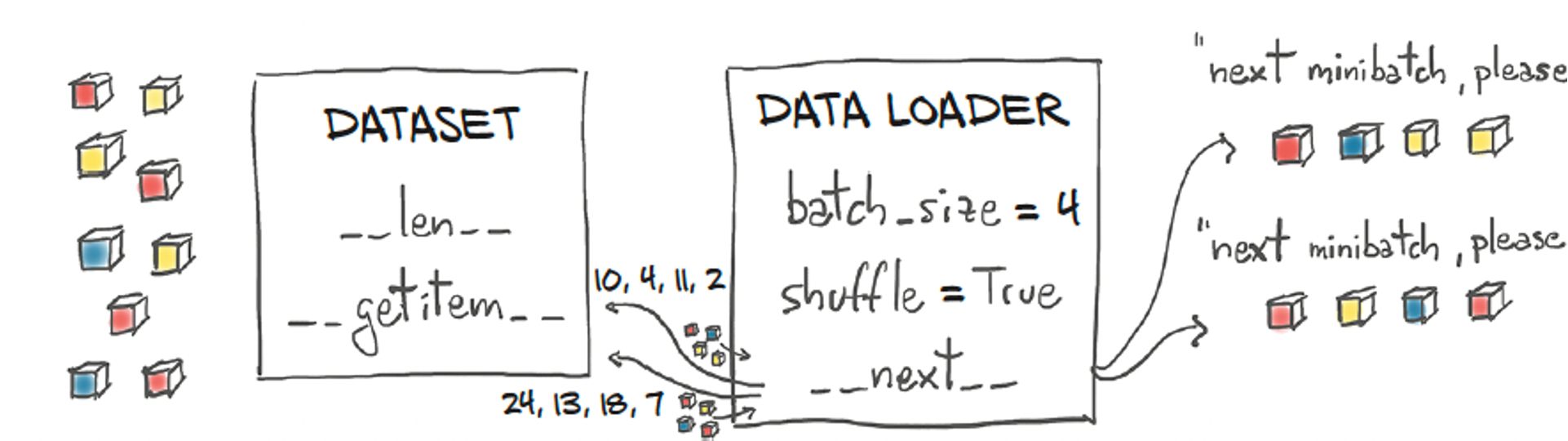
DatasetObject:Abstract class representing a dataset.
Custom datasets are created by subclassing
Datasetand implementing__len__and__getitem__.DataLoaderObject:Provides an iterable over a dataset.
Handles batching, shuffling, and loading data in parallel.
Key Features:
- Batching: Efficiently groups data samples into batches.
- Shuffling: Randomizes the order of data samples.
- Parallel Loading: Uses multiple workers to load data in parallel, improving performance.
1. Load and Scale MNIST
Load MNIST handwritten digit dataset with 60K training samples and 10K test samples.
# Define a transform to scale the pixel values from [0, 255] to [-1, 1]
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
batch_size = 64
# Download and load the training data
trainset = torchvision.datasets.MNIST('./data/MNIST_data/', download=True,
train=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True)
# Download and load the test data
testset = torchvision.datasets.MNIST('./data/MNIST_data/', download=True,
train=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=True)torchvision.dataset.MNISTis a convenience class which inherits fromtorch.utils.data.Dataset(see doc) that wraps a particular dataset and overwrites a__getitem__()method which retrieves a data sample given an index or a key.If we give the argument
train=True, it returns the training set, while the argumenttrain=Falsereturns the test set.torch.utils.data.DataLoader()takes a dataset as in the previous line and returns a python iterable which lets you loop through the data.We give
DataLoaderthe batch size, and it will return a batch of data samples on each iteration.By passing
shuffle=True, we are telling the data loader to shuffle the batches after every epoch.
Code
print(f"No. of training images: {len(trainset)}")
print(f"No. of test images: {len(testset)}")
print("The dataset classes are:")
print(trainset.classes)No. of training images: 60000
No. of test images: 10000
The dataset classes are:
['0 - zero', '1 - one', '2 - two', '3 - three', '4 - four', '5 - five', '6 - six', '7 - seven', '8 - eight', '9 - nine']We can see the data loader, trainloader in action in the code below to get a batch and visualize it along with the labels.
Everytime we rerun the cell we will get a different batch.
Code
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = next(dataiter)
# show images
imshow(torchvision.utils.make_grid(images))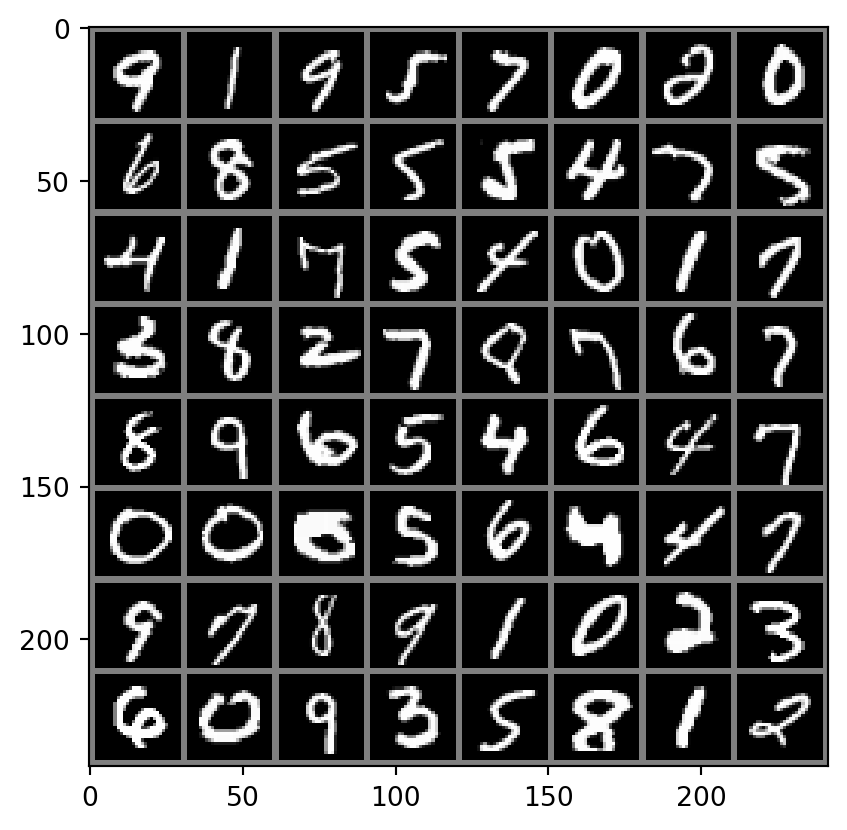
Code
from IPython.display import display, HTML
# Assuming batch_size is 64 and images are displayed in an 8x8 grid
labels_grid = [trainset.classes[labels[j]] for j in range(64)]
labels_grid = np.array(labels_grid).reshape(8, 8)
df = pd.DataFrame(labels_grid)
# Generate HTML representation of DataFrame with border
html = df.to_html(border=1)
# Add CSS to shrink the size of the table
html = f"""
<style>
table {{
font-size: 14px;
}}
</style>
{html}
"""
# Display the DataFrame
display(HTML(html))| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 9 - nine | 1 - one | 9 - nine | 5 - five | 7 - seven | 0 - zero | 2 - two | 0 - zero |
| 1 | 6 - six | 8 - eight | 5 - five | 5 - five | 5 - five | 4 - four | 7 - seven | 5 - five |
| 2 | 4 - four | 1 - one | 7 - seven | 5 - five | 4 - four | 0 - zero | 1 - one | 7 - seven |
| 3 | 3 - three | 8 - eight | 2 - two | 7 - seven | 8 - eight | 7 - seven | 6 - six | 7 - seven |
| 4 | 8 - eight | 9 - nine | 6 - six | 5 - five | 4 - four | 6 - six | 4 - four | 7 - seven |
| 5 | 0 - zero | 0 - zero | 0 - zero | 5 - five | 6 - six | 4 - four | 4 - four | 7 - seven |
| 6 | 9 - nine | 7 - seven | 8 - eight | 9 - nine | 1 - one | 0 - zero | 2 - two | 3 - three |
| 7 | 6 - six | 0 - zero | 9 - nine | 3 - three | 5 - five | 8 - eight | 1 - one | 2 - two |
Convolutional Neural Networks
Problems with Fully-Connected Networks
- Size
- 224x224 RGB image = 150,528 dimensions
- Hidden layers generally larger than inputs <<<<<<< HEAD
One hidden layer = \(150,520 \times 150,528\approx 22\) billion weights
- One hidden layer = \(150,520\times 150,528\approx 22\) billion weights >>>>>>> main
- Nearby pixels statistically related
- Fully connected networks don’t exploit spatial correlation
Convolutional Neural Network (CNN)
- Definition:
- A type of deep learning model designed for processing structured grid data, such as images.
- Utilizes convolutional layers to automatically and adaptively learn spatial hierarchies of features.
- Key Components:
- Convolutional Layers: Apply filters to input data to create feature maps.
- Pooling Layers: Reduce the dimensionality of feature maps while retaining important information.
- Fully Connected Layers: Perform classification based on the features extracted by convolutional and pooling layers.
- Advantages:
- Parameter Sharing: Reduces the number of parameters, making the network more efficient.
- Translation Invariance: Recognizes patterns regardless of their position in the input.
Convolutional Network Applications

- Multi-class classification problem ( >2 possible classes)
- Convolutional network with classification output

- Localize and classify objects in an image
- Convolutional network with classification and regression output
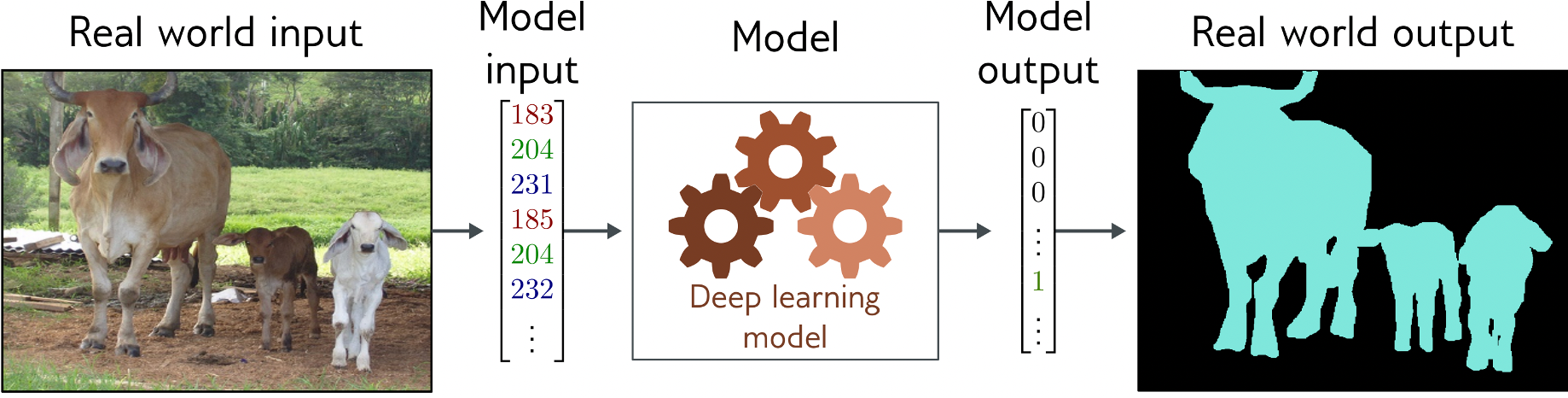
- Classify each pixel in an image to 2 or more classes
- Convolutional encoder-decoder network with a classification values for each pixel
Classification Invariant to Shift

- Let’s say we want to do classification on these two images.
- If you look carefully, one image is shifted w.r.t. the other.
- An FCN would have to learn a new set of weights for each shift.
Image Segmentation Invariant to Shift

- Same thing for image segmentation.
- An FCN would have to learn a new set of weights for each shift.
Solution: Convolutional Neural Networks
- Parameters only look at local data regions
- Shares parameters across image or signal
1-D Convolution
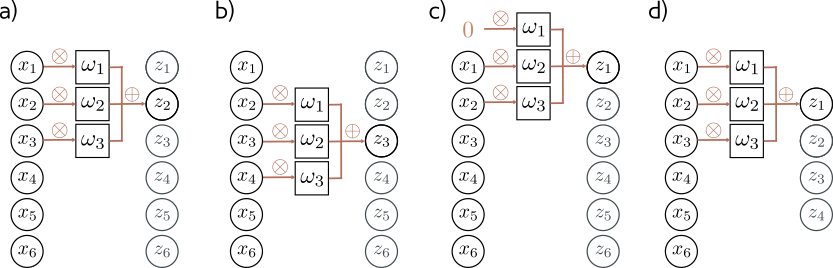
In CNNs, we define a set of weights that are moved across the input data.
Here is an example with 3 weights and input of length 6.
In Figure (a), we calculate
\[ z_2 = \omega_1 x_1 + \omega_2 x_2 + \omega_3 x_3. \]
To calculate \(z_3\), we shift the weights over 1 place (figure (b)) and then weight and sum the inputs. We can generalize the equation slightly to
\[ z_i = \omega_1 x_{i - 1} + \omega_2 x_i + \omega_3 x_{i+1}. \]
What do we do about \(z_1\)?
We calculate \(z_1\) by padding our input data. In figure (c), we simply add (pad with) \(0\). This allows us to calculate \(z_1\).
Alternatively, we can just reduce the size of the output, by only calculating where we have valid input data, as in figure (d).
For 1-D data, this reduces the output size by 1 at the beginning and end of the data. This means that for a length-3 filter, the size of the output is reduced by 2.
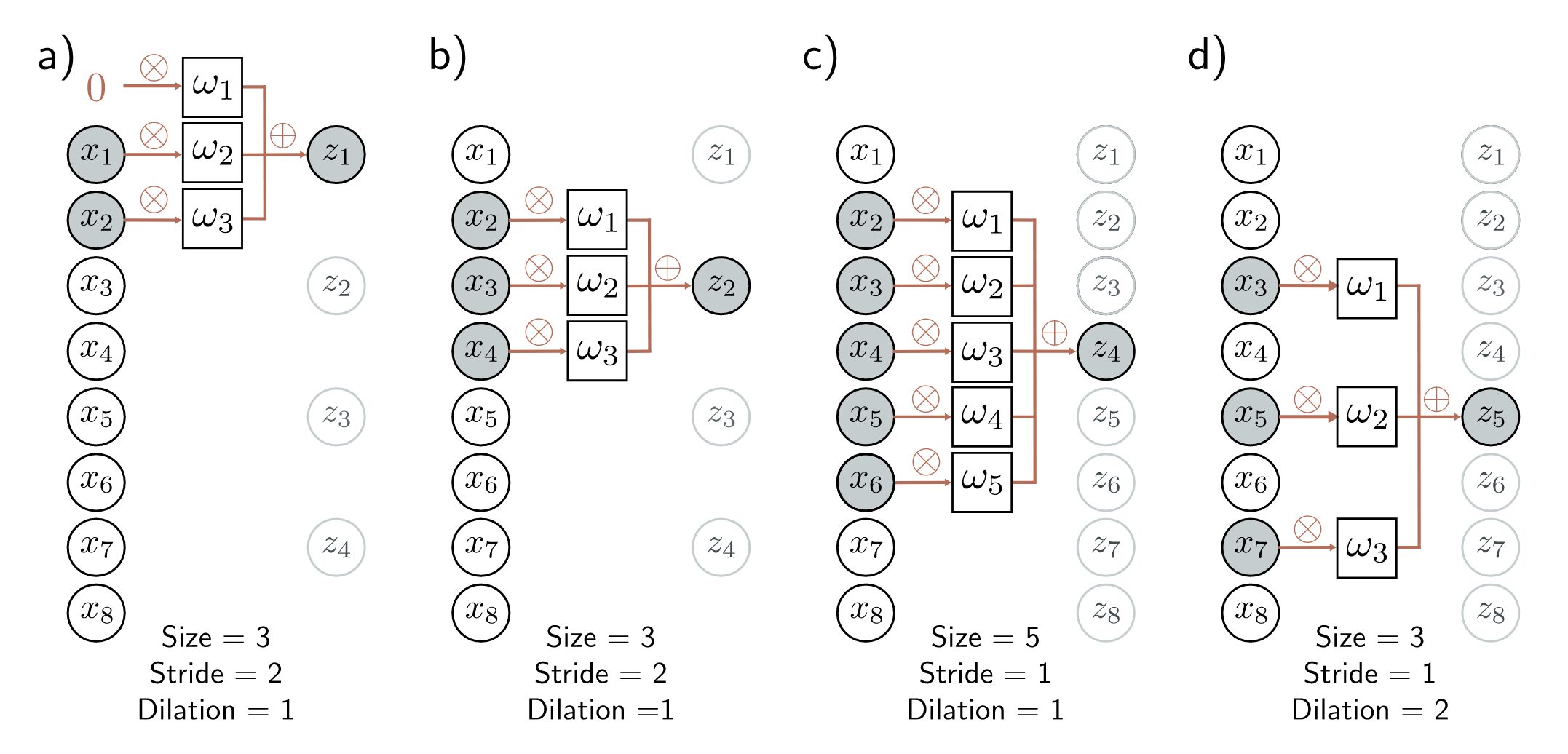
There are a few design choices one can make with convolution layers, such as:
- filter length, e.g., size 3 in figures (a) and (b) and 5 in (c).
- stride, the shift of the weights to calculate the next output. Common values are
- stride 1 as we saw in the previous examples and in figures (c) and (d),
- stride 2, which effectively halves the size of the output as in figures (a) and (b).
- dilation, the spacing between elements in the filter. There is an example of dilation=2 in the filter in figure (d)
2D Convolution
Input Image
\[ \begin{bmatrix} 1 & 2 & 3 & 0 \\ 4 & 5 & 6 & 1 \\ 7 & 8 & 9 & 2 \\ 0 & 1 & 2 & 3 \end{bmatrix} \]
Kernel
\[ \begin{bmatrix} 1 & 0 \\ 0 & -1 \end{bmatrix} \]
Convolution Operation
The convolution operation involves sliding the kernel over the input image and computing the dot product at each position.
Computing the Feature Map
\[ \begin{bmatrix} (1*1 + 5*(-1)) & (2*1 + 6*(-1)) & (3*1 + 1*(-1)) \\ (4*1 + 8*(-1)) & (5*1 + 9*(-1)) & (6*1 + 2*(-1)) \\ (7*1 + 1*(-1)) & (8*1 + 2*(-1)) & (9*1 + 3*(-1)) \end{bmatrix} \]
Feature Map
\[ \begin{bmatrix} -4 & -4 & 2 \\ -4 & -4 & 4 \\ 6 & 6 & 7 \end{bmatrix} \]
Explanation
- The kernel is applied to each 2x2 submatrix of the input image.
- The resulting values form the feature map, which can highlight patterns of the input image.
- Given an \(n\times n\) image, \(m\times m\) kernel size, and a stride of 1, the output of the convolution is an \(n-m +1 \times n-m +1\) matrix.
2D Convolution
For images and video frames we use a two-dimensional convolution (called conv2d in PyTorch) which is an extension of the 1-D convolution. From cs231n.
Let’s look at a 2D convolution layer: \(7 \times 7 \times 3 \rightarrow 3 \times 3 \times 2\)
Max Pooling
Input Image
\[ \begin{bmatrix} 1 & 3 & 2 & 4 \\ 5 & 6 & 1 & 2 \\ 7 & 8 & 3 & 0 \\ 4 & 2 & 1 & 5 \end{bmatrix} \]
Max Pooling Operation
- Filter size: \(2 \times 2\)
- Stride: 2
Steps
\[ \begin{bmatrix} {\color{cyan}1} & {\color{cyan}3} & {\color{magenta}2} & {\color{magenta}4} \\ {\color{cyan}5} & {\color{cyan}6} & {\color{magenta}1} & {\color{magenta}2} \\ {\color{orange}7} & {\color{orange}8} & {\color{teal}3} & {\color{teal}0} \\ {\color{orange}4} & {\color{orange}2} & {\color{teal}1} & {\color{teal}5} \end{bmatrix} \]
- Apply the \(2 \times 2\) filter to the top-left corner of the input image: \[ \begin{bmatrix} {\color{cyan}1} & {\color{cyan}3} \\ {\color{cyan}5} & {\color{cyan}6} \end{bmatrix} \] Max value: 6
\[ \begin{bmatrix} {\color{cyan}1} & {\color{cyan}3} & {\color{magenta}2} & {\color{magenta}4} \\ {\color{cyan}5} & {\color{cyan}6} & {\color{magenta}1} & {\color{magenta}2} \\ {\color{orange}7} & {\color{orange}8} & {\color{teal}3} & {\color{teal}0} \\ {\color{orange}4} & {\color{orange}2} & {\color{teal}1} & {\color{teal}5} \end{bmatrix} \]
- Move the filter to the next position (stride 2): \[ \begin{bmatrix} {\color{magenta}2} & {\color{magenta}4} \\ {\color{magenta}1} & {\color{magenta}2} \end{bmatrix} \] Max value: 4
\[ \begin{bmatrix} {\color{cyan}1} & {\color{cyan}3} & {\color{magenta}2} & {\color{magenta}4} \\ {\color{cyan}5} & {\color{cyan}6} & {\color{magenta}1} & {\color{magenta}2} \\ {\color{orange}7} & {\color{orange}8} & {\color{teal}3} & {\color{teal}0} \\ {\color{orange}4} & {\color{orange}2} & {\color{teal}1} & {\color{teal}5} \end{bmatrix} \]
- Move the filter down to the next row: \[ \begin{bmatrix} {\color{orange}7} & {\color{orange}8} \\ {\color{orange}4} & {\color{orange}2} \end{bmatrix} \] Max value: 8
\[ \begin{bmatrix} {\color{cyan}1} & {\color{cyan}3} & {\color{magenta}2} & {\color{magenta}4} \\ {\color{cyan}5} & {\color{cyan}6} & {\color{magenta}1} & {\color{magenta}2} \\ {\color{orange}7} & {\color{orange}8} & {\color{teal}3} & {\color{teal}0} \\ {\color{orange}4} & {\color{orange}2} & {\color{teal}1} & {\color{teal}5} \end{bmatrix} \]
- Move the filter to the next position (stride 2): \[ \begin{bmatrix} {\color{teal}3} & {\color{teal}0} \\ {\color{teal}1} & {\color{teal}5} \end{bmatrix} \] Max value: 5
Resulting Feature Map
\[ \begin{bmatrix} 6 & 4 \\ 8 & 5 \end{bmatrix} \]
Explanation
- Max pooling reduces the dimensionality of the input image by taking the maximum value from each \(2 \times 2\) region.
- This operation helps to retain the most important features while reducing the computational complexity.
Define a CNN in PyTorch
We will do the following steps in order:
- Load and scale the MNIST training and test datasets using
torchvision(already done) - Define a Convolutional Neural Network architecture
- Define a loss function
- Train the network on the training data
- Test the network on the test data
Define and instantiate a CNN for MNIST.
# network for MNIST
import torch
from torch import nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.pool = nn.MaxPool2d(2)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = nn.functional.relu(x)
x = self.conv2(x)
x = nn.functional.relu(x)
x = self.pool(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = nn.functional.relu(x)
x = self.fc2(x)
output = nn.functional.log_softmax(x, dim=1)
return output
net = Net()
print(net)Net(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=9216, out_features=128, bias=True)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)The Conv2d layer is defined as:
CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size,
stride=1, padding_mode='valid', ...)We can see the layers and shapes of the data as it passes through the network.
| Layer | Kernel Size | Stride | Input Shape | Input Channels | Output Channels | Output Shape |
|---|---|---|---|---|---|---|
| Conv2D/ReLU | (3x3) | 1 | 28x28 | 1 | 32 | 26x26 |
| Conv2D/ReLU | (3x3) | 1 | 26x26 | 32 | 64 | 24x24 |
| Max_pool2d | (2x2) | 2 | 24x24 | 64 | 64 | 12x12 |
| Flatten | 12x12 | 64 | 1 | 9216x1 | ||
| FC/ReLU | 9216x1 | 1 | 1 | 128x1 | ||
| FC Linear | 128x1 | 1 | 1 | 10x1 | ||
| Soft Max | 10x1 | 1 | 1 | 10x1 |
Here’s a common way to visualize a CNN architecture.

3. Define a Loss function and optimizer
We’ll use a Classification Cross-Entropy loss and SGD with momentum.
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)Cross Entropy Loss
- Popular loss function for multi-class classification that measures the dissimilarity between the predicted class log probability \(\log(\hat{y}_i)\) and the true class \(y_i\).
\[ - \sum_i y_i \log(\hat{y}_i). \]
See this link for more information.
Momentum
Momentum is a useful technique in optimization. It accelerates gradients vectors in the right directions, which can lead to faster convergence.
It is inspired by physical laws of motion. The optimizer uses ‘momentum’ to push over hilly terrains and valleys to find the global minimum.
In gradient descent, the weight update rule with momentum is given by:
\[ m_{t+1} = \beta m_t + \eta \nabla J(w_t), \]
\[ w_{t+1} = w_t - m_{t+1}, \]
where
- \(m_t\) is the momentum (which drives the update at iteration \(t\)),
- \(\beta \in [0, 1)\), typically 0.9, controls the degree to which the gradient is smoothed over time, and
- \(\eta\) is the learning rate.
See Understanding Deep Learning, Section 6.3 to learn more.
4. Train the network
print(f"[Epoch #, Iteration #] loss")
# loop over the dataset multiple times
# change this value to 2
for epoch in range(1):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 100 == 99: # print every 2000 mini-batches
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
print('Finished Training')[Epoch #, Iteration #] loss
[1, 100] loss: 0.111
[1, 200] loss: 0.080
[1, 300] loss: 0.031
[1, 400] loss: 0.023
[1, 500] loss: 0.020
[1, 600] loss: 0.017
[1, 700] loss: 0.017
[1, 800] loss: 0.016
[1, 900] loss: 0.015
Finished TrainingDisplay some of the images from the test set with the ground truth labels.
Code
dataiter = iter(testloader)
images, labels = next(dataiter)
# print images
imshow(torchvision.utils.make_grid(images))
Code
from IPython.display import display, HTML
# Assuming batch_size is 64 and images are displayed in an 8x8 grid
labels_grid = [testset.classes[labels[j]] for j in range(64)]
labels_grid = np.array(labels_grid).reshape(8, 8)
df = pd.DataFrame(labels_grid)
# Generate HTML representation of DataFrame with border and smaller font size
html = df.to_html(border=1)
# Add CSS to shrink the size of the table
html = f"""
<style>
table {{
font-size: 14px;
}}
</style>
{html}
"""
# Display the DataFrame
display(HTML(html))| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 7 - seven | 2 - two | 8 - eight | 5 - five | 4 - four | 8 - eight | 3 - three | 5 - five |
| 1 | 2 - two | 1 - one | 8 - eight | 1 - one | 7 - seven | 4 - four | 7 - seven | 4 - four |
| 2 | 5 - five | 9 - nine | 7 - seven | 9 - nine | 5 - five | 7 - seven | 4 - four | 4 - four |
| 3 | 9 - nine | 4 - four | 1 - one | 5 - five | 6 - six | 5 - five | 5 - five | 0 - zero |
| 4 | 6 - six | 9 - nine | 0 - zero | 4 - four | 3 - three | 9 - nine | 6 - six | 4 - four |
| 5 | 8 - eight | 6 - six | 4 - four | 6 - six | 4 - four | 2 - two | 6 - six | 1 - one |
| 6 | 7 - seven | 7 - seven | 2 - two | 1 - one | 3 - three | 7 - seven | 8 - eight | 7 - seven |
| 7 | 4 - four | 5 - five | 7 - seven | 2 - two | 4 - four | 4 - four | 8 - eight | 7 - seven |
Let’s run inference (forward pass) on the model to get numeric outputs.
outputs = net(images)Get the index of the element with highest value and print the label associated with that index.
_, predicted = torch.max(outputs, 1)We can display the predicted labels for the images.
Code
# print images
imshow(torchvision.utils.make_grid(images))
Code
# Assuming batch_size is 64 and images are displayed in an 8x8 grid
labels_grid = [testset.classes[predicted[j]] for j in range(64)]
labels_grid = np.array(labels_grid).reshape(8, 8)
df = pd.DataFrame(labels_grid)
# Generate HTML representation of DataFrame with border
html = df.to_html(border=1)
# Add CSS to shrink the size of the table
html = f"""
<style>
table {{
font-size: 14px;
}}
</style>
{html}
"""
# Display the DataFrame
display(HTML(html))| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 7 - seven | 2 - two | 8 - eight | 5 - five | 0 - zero | 8 - eight | 3 - three | 5 - five |
| 1 | 2 - two | 1 - one | 8 - eight | 1 - one | 7 - seven | 4 - four | 2 - two | 4 - four |
| 2 | 5 - five | 9 - nine | 7 - seven | 7 - seven | 5 - five | 7 - seven | 4 - four | 4 - four |
| 3 | 9 - nine | 4 - four | 1 - one | 3 - three | 6 - six | 5 - five | 5 - five | 0 - zero |
| 4 | 3 - three | 9 - nine | 0 - zero | 4 - four | 3 - three | 9 - nine | 6 - six | 4 - four |
| 5 | 8 - eight | 6 - six | 4 - four | 6 - six | 4 - four | 2 - two | 6 - six | 1 - one |
| 6 | 3 - three | 7 - seven | 2 - two | 1 - one | 3 - three | 7 - seven | 8 - eight | 7 - seven |
| 7 | 4 - four | 3 - three | 7 - seven | 2 - two | 4 - four | 4 - four | 8 - eight | 7 - seven |
Evaluate over the entire test set.
correct = 0
total = 0
# since we're not training, we don't need to calculate the gradients for our outputs
with torch.no_grad():
for data in testloader:
images, labels = data
# calculate outputs by running images through the network
outputs = net(images)
# the class with the highest energy is what we choose as prediction
# here, we throw away the max value and just keep the class index
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct // total} %')Accuracy of the network on the 10000 test images: 91 %Evaluate the performance per class.
Code
# prepare to count predictions for each class
correct_pred = {classname: 0 for classname in testset.classes}
total_pred = {classname: 0 for classname in testset.classes}
# again no gradients needed
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predictions = torch.max(outputs, 1)
# collect the correct predictions for each class
for label, prediction in zip(labels, predictions):
if label == prediction:
correct_pred[testset.classes[label]] += 1
total_pred[testset.classes[label]] += 1
# print accuracy for each class
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print(f'Accuracy for class: {classname:5s} is {accuracy:.1f} %')Accuracy for class: 0 - zero is 97.0 %
Accuracy for class: 1 - one is 98.0 %
Accuracy for class: 2 - two is 83.7 %
Accuracy for class: 3 - three is 93.8 %
Accuracy for class: 4 - four is 95.1 %
Accuracy for class: 5 - five is 89.9 %
Accuracy for class: 6 - six is 95.8 %
Accuracy for class: 7 - seven is 94.9 %
Accuracy for class: 8 - eight is 88.2 %
Accuracy for class: 9 - nine is 82.4 %To Dig Deeper
Try working with common CNN network architectures.
For example see Understanding Deep Learning section 10.5 or PyTorch models and pre-trained weights.
Recap
We covered the following topics:
- Convolutional Neural Networks
- 1-D and 2-D convolutions
- Common CNN architectures
- Training a CNN in PyTorch