We know that a model that overfits does not generalize well. In other words, the model does not perform well on data it was not trained on.
We observe overfitting when the training accuracy of the model is high, while the accuracy on the validation set (or held out test set) stagnates.
In this lecture we will discuss regularization. A technique to help prevent overfitting. We will see how to apply regularization to regression problems.
However, regularization is a general technique to ensure models learn broad patterns and is applicable in neural networks.
What is regularization?
We know regularization is a way to prevent overfitting, but how does this actually work?
The idea behind regularization is to penalize a model’s loss function during training. The added penalty will discourage the model from becoming too complex (i.e., overfitting).
In regression, our training process was to compute coefficients \(\boldsymbol{\beta}\) by minimizing
\[
\min_{\boldsymbol{\beta}} \Vert X \boldsymbol{\beta} - \mathbf{y}\Vert_{2}^{2},
\]
where \(X\in\mathbb{R}^{m\times n}\) is the design matrix and \(\mathbf{y}\in\mathbb{R}^{m}\) are the dependent variables.
Regularization adds a function \(R(\boldsymbol{\beta})\) to the minimization problem. A regularized minimization problem is then: compute \(\boldsymbol{\beta}\) such that
\[
\min_{\boldsymbol{\beta}} \Vert X \boldsymbol{\beta} - \mathbf{y}\Vert_{2}^{2} + cR(\boldsymbol{\beta}).
\]
The regularization coefficient \(c\) is a hyperparameter that controls the importance of the regularization term \(R(\boldsymbol{\beta})\).
We will consider two common forms of \(R(\boldsymbol{\beta})\):
\(R(\boldsymbol{\beta}) = \Vert \boldsymbol{\beta}\Vert_{2}^{2}\), called ridge regression, and
\(R(\boldsymbol{\beta}) = \Vert \boldsymbol{\beta}\Vert_1\), called LASSO regression.
Overview
In this lecture we will cover:
situations where regression is needed to help
when to use the different types of regression
importance of the hyperparameter \(c\)
Multicollinearity
In statistics, multicollinearity (also collinearity) is a phenomenon in which two or more predictor variables in a multiple regression model are highly correlated, meaning that one can be linearly predicted from the others with a substantial degree of accuracy.
We will see that multicollinearity can be problematic in our regression models.
To address these issues, we will consider
What are the potential sources for multicollinearity?
What does multicollinearity tell us about our data?
Understanding these questions will inform us how regularization can be used to mitigate the issue of multicollinearity.
Sources of Multicollinearity
We will be working with our design matrix \(X\in\mathbb{R}^{m\times n}\), where each row corresponds to an instance of data and the \(n\) columns are the \(n\) features of the data points.
We will see that multicollinearity arises when the columns of \(X\) are linearly dependent (or nearly linearly dependent).
As a consequence, the matrix \(X^{T}X\) is no longer invertible. However, as we saw in our Linear Regression lecture, the least squares solution still exists. It is just not unique.
What are the situations where this can happen?
One clear case is when \(m < n\), which means \(X\) has more columns than rows. That is, there are more features than there are observations in the data.
However, we can still observe multicollinearity when \(m > n\).
This can happen when the columns of \(X\) happen to be linearly dependent because of the nature of the data itself. In particular, this happens when one column is a linear function of the other columns. This means that one independent variable is a linear function of one or more of the others.
Unfortunately, in practice we will run into trouble even if variables are almost linearly dependent.
To illustrate the multcollinearity problem, we’ll load a standard dataset.
The Longley dataset contains various US macroeconomic variables from 1947–1962.
OLS Regression Results
==============================================================================
Dep. Variable: TOTEMP R-squared: 0.987
Model: OLS Adj. R-squared: 0.981
Method: Least Squares F-statistic: 156.4
Date: Tue, 29 Oct 2024 Prob (F-statistic): 3.70e-09
Time: 07:51:28 Log-Likelihood: -117.83
No. Observations: 16 AIC: 247.7
Df Residuals: 10 BIC: 252.3
Df Model: 5
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
GNPDEFL -48.4628 132.248 -0.366 0.722 -343.129 246.204
GNP 0.0720 0.032 2.269 0.047 0.001 0.143
UNEMP -0.4039 0.439 -0.921 0.379 -1.381 0.573
ARMED -0.5605 0.284 -1.975 0.077 -1.193 0.072
POP -0.4035 0.330 -1.222 0.250 -1.139 0.332
const 9.246e+04 3.52e+04 2.629 0.025 1.41e+04 1.71e+05
==============================================================================
Omnibus: 1.572 Durbin-Watson: 1.248
Prob(Omnibus): 0.456 Jarque-Bera (JB): 0.642
Skew: 0.489 Prob(JB): 0.725
Kurtosis: 3.079 Cond. No. 1.21e+08
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.21e+08. This might indicate that there are
strong multicollinearity or other numerical problems.
Condition Number
The notion of conditioning pertains to the perturbation behavior of a mathematical problem. A well-conditioned problem is one where small changes to the inputs produce small changes to the output. An ill-conditioned problem is one where small changes in the input can produce very large changes in the output.
The condition number of a matrix provides an indication of how accurately you can compute with it.
A large condition number tells us that our problem is ill conditioned, i.e., small changes to the input can produce very large changes in the output.
A small condition number tells us that our problem is well-conditioned.
The condition number is derived using matrix norms, which is beyond the scope of this course. However, we will use the following definition for the condition number of our matrix
This means that if we have a poorly conditioned data matrix \(X\), then \(X^TX\) is even more poorly conditioned.
This is why you should never work directly with \(X^TX\) as it can be numerically unstable.
Normal Equations
To solve the least-squares problem we solve the normal equations
\[
X^TX\boldsymbol{\beta} = X^Ty.
\]
These equations always have at least one solution. However, the at least one part is problematic.
If there are multiple solutions, they are in a sense all equivalent in that they yield the same value of \(\Vert X\boldsymbol{\beta} - y\Vert_2\).
However, the actual values of \(\boldsymbol{\beta}\) can vary tremendously and so it is not clear how best to interpret which solution is actually the best.
When does this problem occur?
Linear Dependence
It occurs when \(X^TX\) is not invertible.
This happens when the columns of \(X\) are linearly dependent – that is, one column can be expressed as a linear combination of the other columns.
In that case, it is not possible to solve the normal equations by computing \(\hat{\boldsymbol{\beta}} \neq (X^TX)^{-1}X^Ty.\)
This is the simplest kind of multicollinearity.
What are the implications of a matrix not being invertible on the condition number?
If a matrix \(Z = X^{T}X\) is not invertible, there is a zero singular value. This implies
\[
\kappa(Z) = \infty.
\]
In other words, the problem of solving an equation with a non-invertible matrix is completely ill-conditioned. In fact, it’s a problem that is impossible to solve.
Near Linear Dependence
Near linear dependence causes problems as well. This can happen, for example, due to measurement errors. Or when two or more columns are strongly correlated.
In such a situation, we have some column of our design matrix that is close to being a linear combination of the other columns.
When these situations occur we will have problems with linear regression.
As a result of near linear dependence, the smallest singular value of the design matrix \(X\) will be close to zero. This means that \(\kappa(X)\) will be very large.
The condition number tells us that a small change in the input to our problem can result in large changes to the output.
This means that for a design matrix \(X\) with near linearly dependent columns, the values we compute for \(\boldsymbol{\beta}\) in our linear regression can vary significantly.
This is why we see the addition of a regularization (penalty) term involving \(\boldsymbol{\beta}\) in the least squares minimization problem. This process regularizes the solution \(\boldsymbol{\beta}\).
Longley Dataset
Recall that the condition number of our data is around \(10^8\).
A large condition number is evidence of a problem.
As a general rule of thumb:
If the condition number is less than 100, there is no serious problem with multicollinearity.
Condition numbers between 100 and 1000 imply moderate to strong multicollinearity.
Condition numbers bigger than 1000 indicate severe multicollinearity.
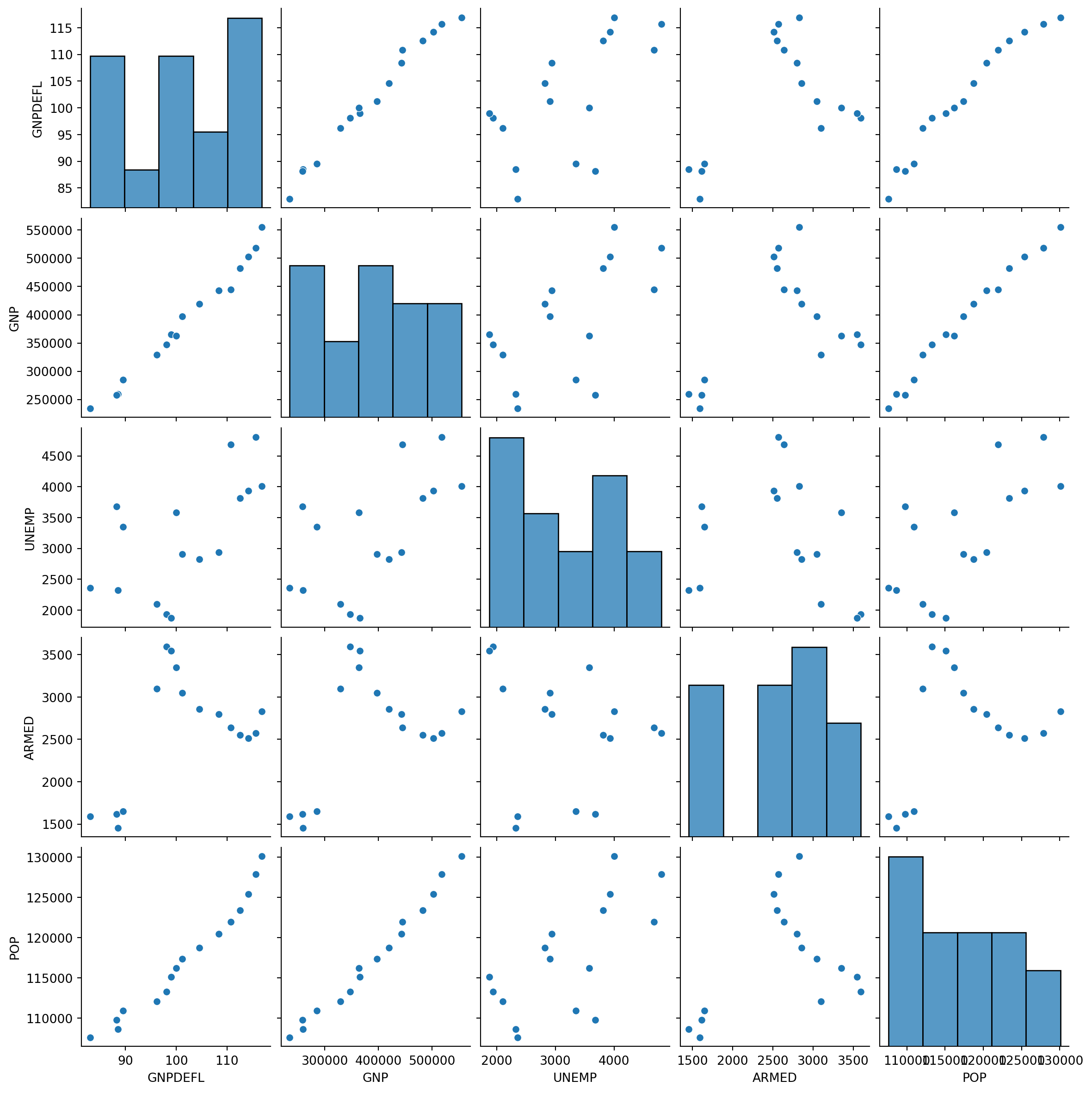
Let’s look at pairwise scatter plots of the Longley data.
We can see very strong linear relationships between, e.g., GNP Deflator, GNP, and Population.
Addressing Multicollinearity
Here are two strategies we can employ to address multicollinearity:
Ridge Regression
Model Selection via LASSO
PCA also addresses multicollinearity by transforming the correlated features into uncorrelated features. However in this approach you lose the original features, which is less explainable.
Ridge Regression
The first thing to note is that when columns of \(X\) are nearly dependent, the components of \(\hat{\boldsymbol{\beta}}\) tend to be large in magnitude.
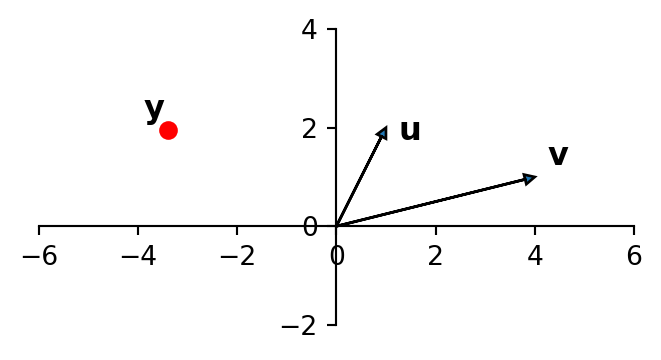
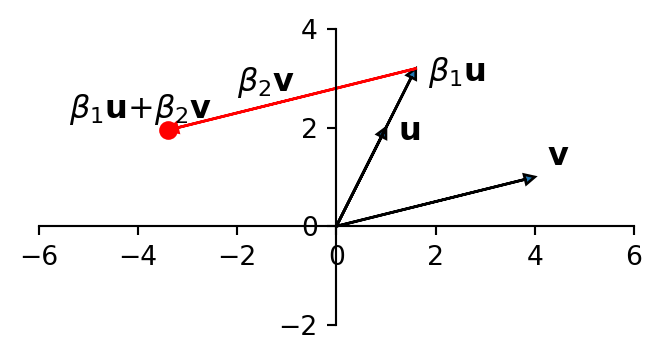
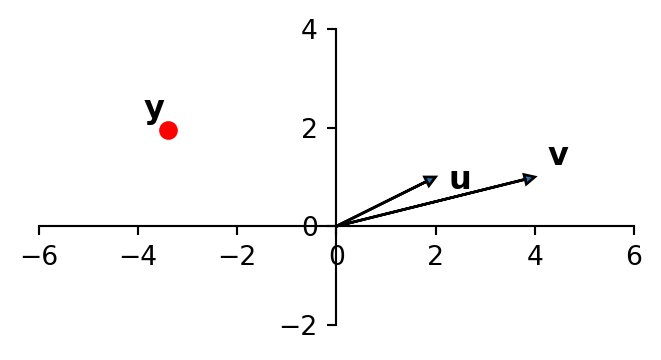
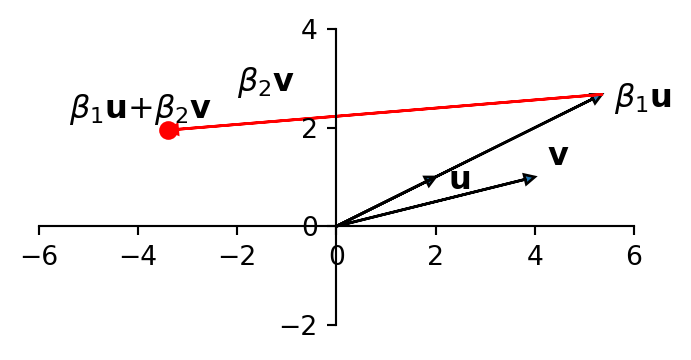
Consider a regression in which we are predicting the point \(\mathbf{y}\) as a linear function of two \(X\) columns, which we’ll denote \(\mathbf{u}\) and \(\mathbf{v}\).
If you imagine the values of \(\beta_1\) and \(\beta_2\) necessary to create \(\mathbf{y} = \beta_1{\bf u}\)+\(\beta_2{\bf v}\), you can see that \(\beta_1\) and \(\beta_2\) will be very large in magnitude.
This geometric argument illustrates why the regression coefficients will be very large under multicollinearity.
As a result, the value of \(\Vert\boldsymbol{\beta}\Vert_2\) will be very large.
Ridge Regression
Ridge regression adjusts the least squares regression by shrinking the estimated coefficients towards zero.
The purpose is to fix the magnitude inflation of \(\Vert\boldsymbol{\beta}\Vert_2\).
To do this, Ridge regression assumes that the model has no intercept term – both the response and the predictors have been centered so that \(\beta_0 = 0\).
Ridge regression then consists of adding a penalty term to the regression:
For any given \(c\) this has a closed-form solution in which \(\hat{\boldsymbol{\beta}} = (X^TX +cI)^{−1}X^T\mathbf{y}.\)
The solution to the Ridge regression problem always exists and is unique, even when the data contains multicollinearity.
Here, \(c \geq 0\) is a tradeoff parameter and controls the strength of the penalty term:
When \(c = 0\), we get the least squares estimator: \(\hat{\boldsymbol{\beta}} = (X^TX)^{−1}X^T\mathbf{y}\)
When \(c \rightarrow \infty\), we get \(\hat{\boldsymbol{\beta}} \rightarrow 0.\)
Increasing the value of \(c\) forces the norm of \(\hat{\boldsymbol{\beta}}\) to decrease, yielding smaller coefficient estimates in magnitude.
For a finite, positive value of \(c\), we are balancing two tasks: fitting a linear model and shrinking the coefficients.
The coefficient \(c\) is a hyperparameter that controls the model complexity. We typically set \(c\) by holding out data, i.e., cross-validation.
Scaling
Note that the penalty term \(\Vert\boldsymbol{\beta}\Vert_2^2\) would be unfair to the different predictors if they are not on the same scale.
Therefore, if we know that the variables are not measured in the same units, we typically first perform unit normal scaling on the columns of \(X\) and on \(\mathbf{y}\) (to standardize the predictors), and then perform ridge regression.
Note that by scaling \(\mathbf{y}\) to have zero-mean, we do not need (or include) an intercept in the model.
Another name for ridge regression is Tikhanov regularization. You may see this terminology used in textbooks on optimization.
Normalizing is needed for this specific method. This is in contrast to the previous lecture where we allowed the coefficients to correct for the scaling differences between different units of measure.
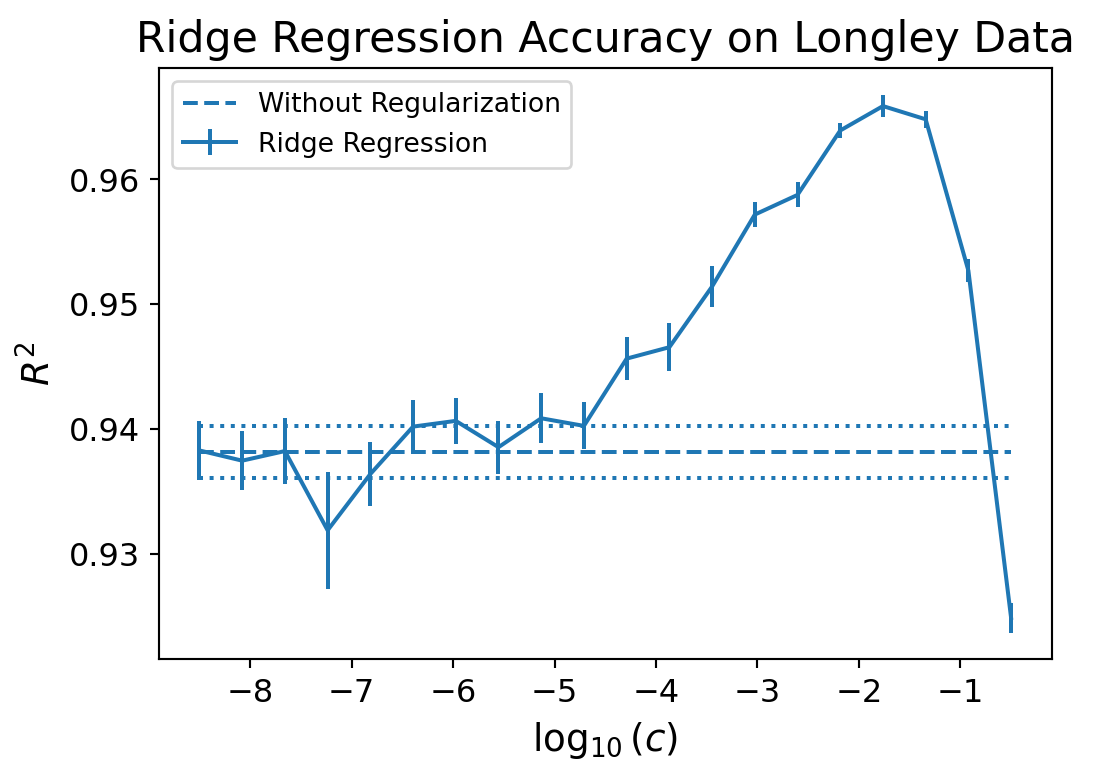
Here is the performance of Ridge regression on the Longley data.
We are training on half of the data and using the other half for testing.
There may be many \(\boldsymbol{\beta}\) values that are consistent with the equations.
Over-fit \(\boldsymbol{\beta}\) values tend to have large magnitudes.
We add the regularization term \(c \Vert \boldsymbol{\beta}\Vert_2^2\) to the least squares to avoid those solutions.
We tune \(c\) to an appropriate value via cross-validation.
Model Selection
Of course, one might attack the problem of multicollinearity as follows:
Multicollinearity occurs when variables (features) are close to linearly dependent.
These variables do not contribute anything meaningful to the quality of the model
As a result why not simply remove variables from the model that are nearly linearly dependent?
We create a new model when we remove these variables from our regression.
This strategy is called model selection.
One of the advantages of model selection is interpretability: by eliminating variables, we get a clearer picture of the relationship between truly useful features and dependent variables.
However, there is a big challenge inherent in model selection. In general, the possibilities to consider are exponential in the number of features.
That is, if we have \(n\) features to consider, then there are \(2^n-1\) possible models that incorporate one or more of those features. This space is usually too big to search directly.
Can we use Ridge regression for this problem?
Ridge regression does not set any coefficients exactly to zero unless \(c\rightarrow \infty\), in which case they’re all zero.
This means Ridge regression cannot perform variable selection. Even though it performs well in terms of prediction accuracy, it does not offer a clear interpretation.
The LASSO
LASSO differs from Ridge regression only in terms of the norm used by the penalty term.
\[
\hat{\beta} = \arg \min_\beta \Vert X\beta - y \Vert_2^2 + c \Vert\beta\Vert_1.
\]
However, this small change in the norm makes a big difference in practice.
The nature of the \(\ell_1\) penalty will cause some coefficients to be shrunken to zero exactly.
This means that LASSO can perform model selection by telling us which variables to keep and which to set aside.
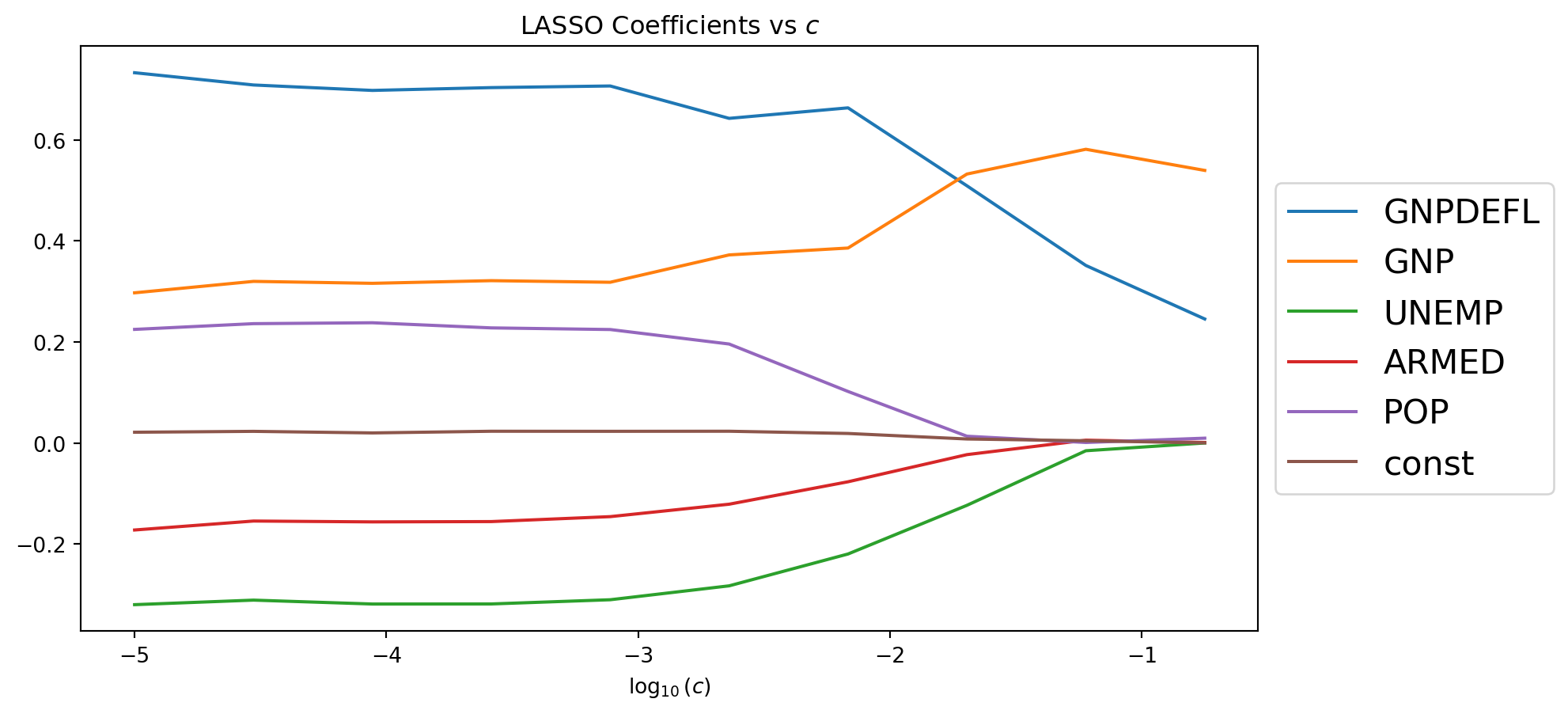
As \(c\) increases, more coefficients are set to zero, i.e., fewer variables are selected.
In terms of prediction error, LASSO performs comparably to Ridge regression but it has a big advantage with respect to interpretation.
param_df.plot()plt.legend(loc='center left', bbox_to_anchor=(1, 0.5), prop={'size': 16})plt.title('LASSO Coefficients vs $c$')plt.show()
We can use the statsmodel smf sub-module to directly type formulas and expressions in the functions of the models. This allows us to, among other things,
specify the name of the columns to be used to predict another column
remove columns
infer the type of the variable (e.g., categorical, numerical)
apply functions to columns
The smf submodule makes use of the patsy package. patsy is a Python package for describing statistical models (especially linear models, or models that have a linear component) and building design matrices. It is closely inspired by and compatible with the formula mini-language used in R and S.
In the following code cells we will see the syntax that is used to specify columns in the models and how to remove columns from our model
Here is an example where we specify the name of the columns to be used to predict another column.
Code
X['TOTEMP'] = y
Code
mod = smf.ols(formula='TOTEMP ~ GNPDEFL + GNP + UNEMP + ARMED + POP', data=X)res = mod.fit() with warnings.catch_warnings(): warnings.simplefilter('ignore')print(res.summary())
OLS Regression Results
==============================================================================
Dep. Variable: TOTEMP R-squared: 0.987
Model: OLS Adj. R-squared: 0.981
Method: Least Squares F-statistic: 156.4
Date: Tue, 29 Oct 2024 Prob (F-statistic): 3.70e-09
Time: 07:52:01 Log-Likelihood: -117.83
No. Observations: 16 AIC: 247.7
Df Residuals: 10 BIC: 252.3
Df Model: 5
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 9.246e+04 3.52e+04 2.629 0.025 1.41e+04 1.71e+05
GNPDEFL -48.4628 132.248 -0.366 0.722 -343.129 246.204
GNP 0.0720 0.032 2.269 0.047 0.001 0.143
UNEMP -0.4039 0.439 -0.921 0.379 -1.381 0.573
ARMED -0.5605 0.284 -1.975 0.077 -1.193 0.072
POP -0.4035 0.330 -1.222 0.250 -1.139 0.332
==============================================================================
Omnibus: 1.572 Durbin-Watson: 1.248
Prob(Omnibus): 0.456 Jarque-Bera (JB): 0.642
Skew: 0.489 Prob(JB): 0.725
Kurtosis: 3.079 Cond. No. 1.21e+08
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.21e+08. This might indicate that there are
strong multicollinearity or other numerical problems.
is an R-style formula string that specifies the model.
The variable TOTEMP is the dependent variable, which is Total Employment in the Longley dataset.
The syntax ~ separates the dependent variable from the independent variables.
The sytnax GNPDEFL + GNP + UNEMP + ARMED + POP are the independent variables, which are GNP Deflator, Gross National Product, Number of Unemployed, Size of the Armed Forces, and Population.
This is an example where we remove columns from the data and exclude the y-intercept.
OLS Regression Results
=======================================================================================
Dep. Variable: TOTEMP R-squared (uncentered): 1.000
Model: OLS Adj. R-squared (uncentered): 1.000
Method: Least Squares F-statistic: 1.127e+04
Date: Tue, 29 Oct 2024 Prob (F-statistic): 1.92e-22
Time: 07:52:01 Log-Likelihood: -137.20
No. Observations: 16 AIC: 280.4
Df Residuals: 13 BIC: 282.7
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
GNPDEFL 871.0961 25.984 33.525 0.000 814.961 927.231
GNP -0.0532 0.007 -8.139 0.000 -0.067 -0.039
UNEMP -0.8333 0.496 -1.679 0.117 -1.905 0.239
==============================================================================
Omnibus: 0.046 Durbin-Watson: 1.422
Prob(Omnibus): 0.977 Jarque-Bera (JB): 0.274
Skew: -0.010 Prob(JB): 0.872
Kurtosis: 2.359 Cond. No. 2.92e+04
==============================================================================
Notes:
[1] R² is computed without centering (uncentered) since the model does not contain a constant.
[2] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[3] The condition number is large, 2.92e+04. This might indicate that there are
strong multicollinearity or other numerical problems.
The formula is
formula='TOTEMP ~ GNPDEFL + GNP + UNEMP - 1'
We still have the same dependent variable TOTEMP. The independent variables are GNPDEFL + GNP + UNEMP
The syntax -1 removes the intercept from the model. By default, an intercept is included in the model, but - 1 explicitly excludes it.
The LASSO and Longley Data
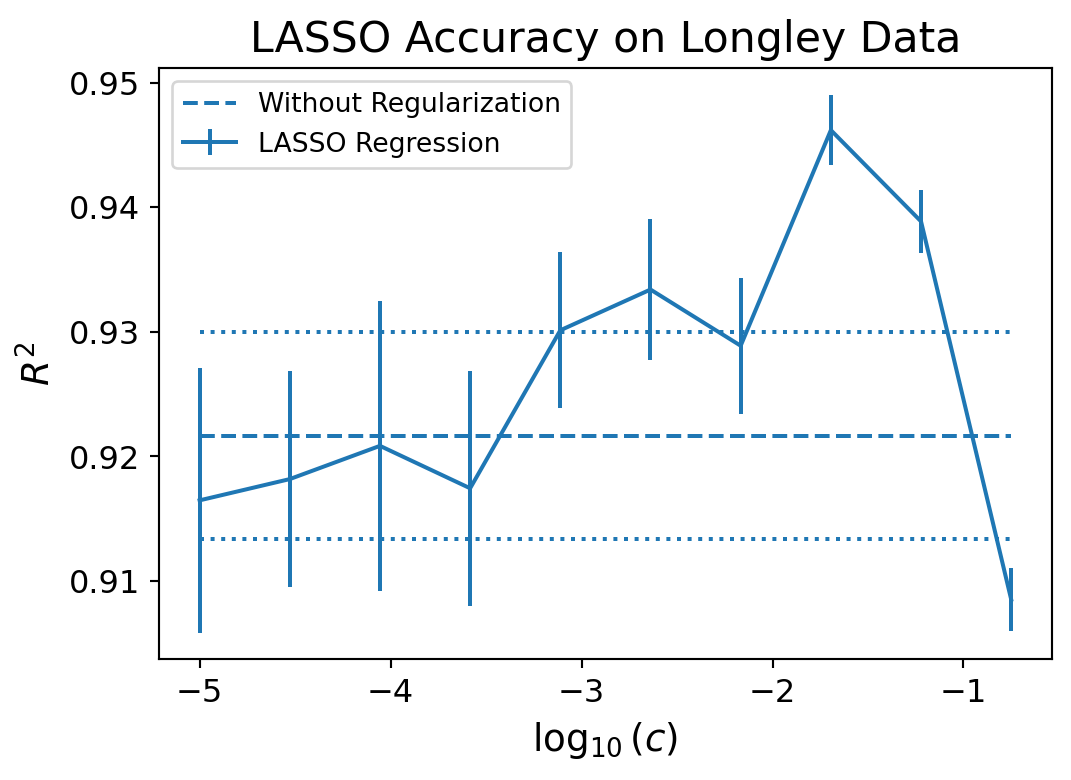
Here are some of the important observations from using LASSO regression on the Longley dataset:
We removed the near linearly dependent features from our model.
We improved the condition number of the data by 4 orders of magnitude.
There is only one variable whose condfidence interval contains 0.
Flexible Modeling
To look at model selection in practice, we will consider another famous dataset.
The Guerry dataset is a collection of historical data used in support of Andre-Michel Guerry’s 1833 “Essay on the Moral Statistics of France.”
Andre-Michel Guerry’s (1833) Essai sur la Statistique Morale de la France was one of the foundation studies of modern social science. Guerry assembled data on crimes, suicides, literacy and other “moral statistics,” and used tables and maps to analyze a variety of social issues in perhaps the first comprehensive study relating such variables.
Guerry’s results were startling for two reasons. First he showed that rates of crime and suicide remained remarkably stable over time, when broken down by age, sex, region of France and even season of the year; yet these numbers varied systematically across departements of France. This regularity of social numbers created the possibility to conceive, for the first time, that human actions in the social world were governed by social laws, just as inanimate objects were governed by laws of the physical world.
Source: “A.-M. Guerry’s Moral Statistics of France: Challenges for Multivariable Spatial Analysis”, Michael Friendly. Statistical Science 2007, Vol. 22, No. 3, 368–399.
Here is the dataset.
Code
# Lottery is per-capital wager on Royal Lotterydf = sm.datasets.get_rdataset("Guerry", "HistData").datadf = df[['Lottery', 'Literacy', 'Wealth', 'Region']].dropna()df.head()
Lottery
Literacy
Wealth
Region
0
41
37
73
E
1
38
51
22
N
2
66
13
61
C
3
80
46
76
E
4
79
69
83
E
Here is a regression using the feature Literacy, Wealth, and Region.
In the previous cell, using the patsy syntax determined that elements of Region were text strings, so it treated Region as a categorical variable.
Alternatively, we could manually enforce this with the syntax on the following slide. Recall that the - sign is used to remove columns/variables. Here we remove the intercept from a model by.
We can also apply vectorized functions to the variables in our model. The following cell shows how to do this. In this case we apply the natural log function to the Literacy column and use this single column to predict the Lottery values.
Code
res = smf.ols(formula='Lottery ~ np.log(Literacy)', data=df).fit()print(res.summary())