So far, we have seen how to cluster objects using \(k\)-means:
Start with an initial set of cluster centers,
Assign each object to its closest cluster center
Recompute the centers of the new clusters
Repeat 2 \(\rightarrow\) 3 until convergence
In \(k\)-means clustering every object is assigned to a single cluster.
This is called hard assignment.
However, there may be cases where we either cannot use hard assignments or we do not want to do it.
In particular, we might have reason to believe that the best description of the data is a set of overlapping clusters.
Overlapping Clusters
Income Level Example
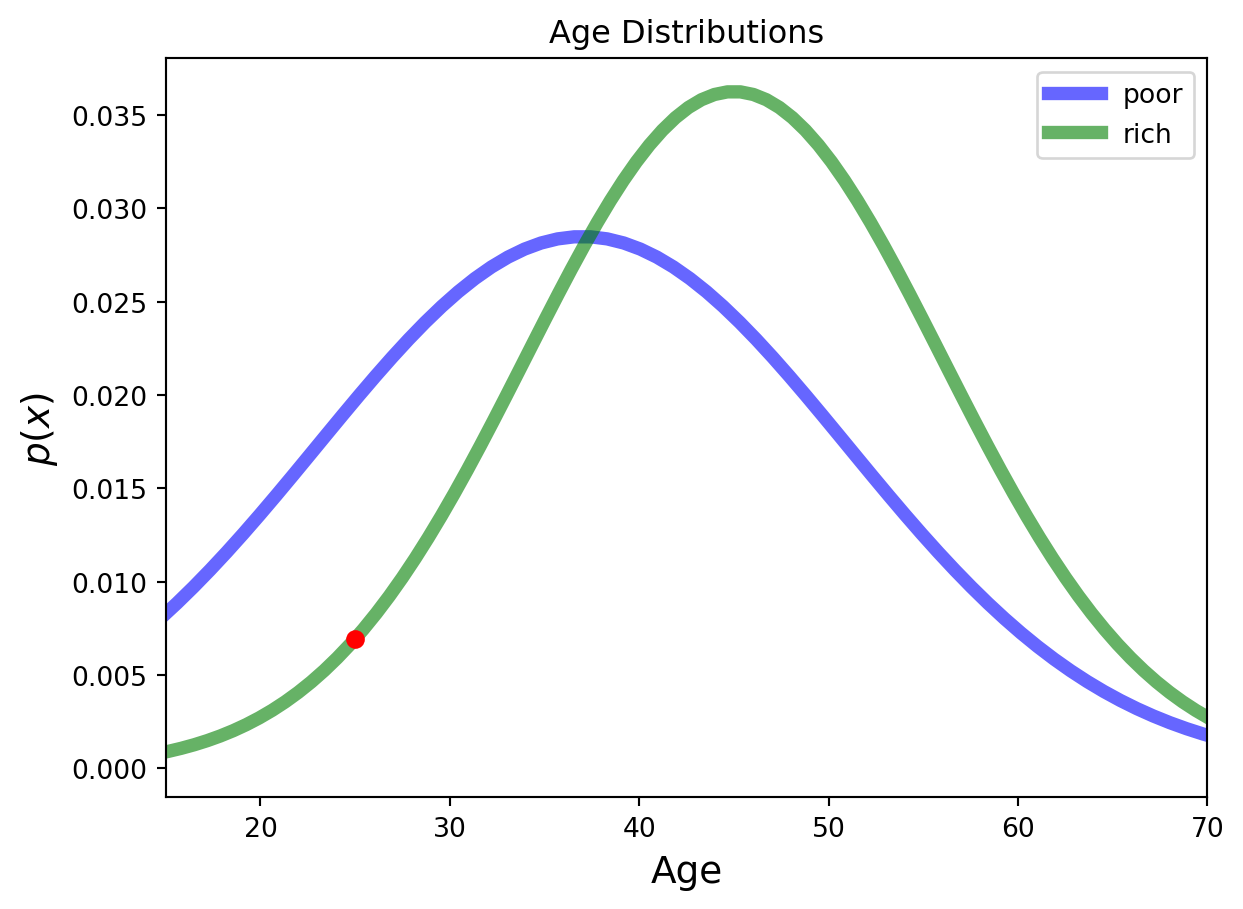
Consider a population in terms of a simple binary income level: higher or lower than some threshold.
How might we model such a population in terms of the single feature age?
Income Level Sampling
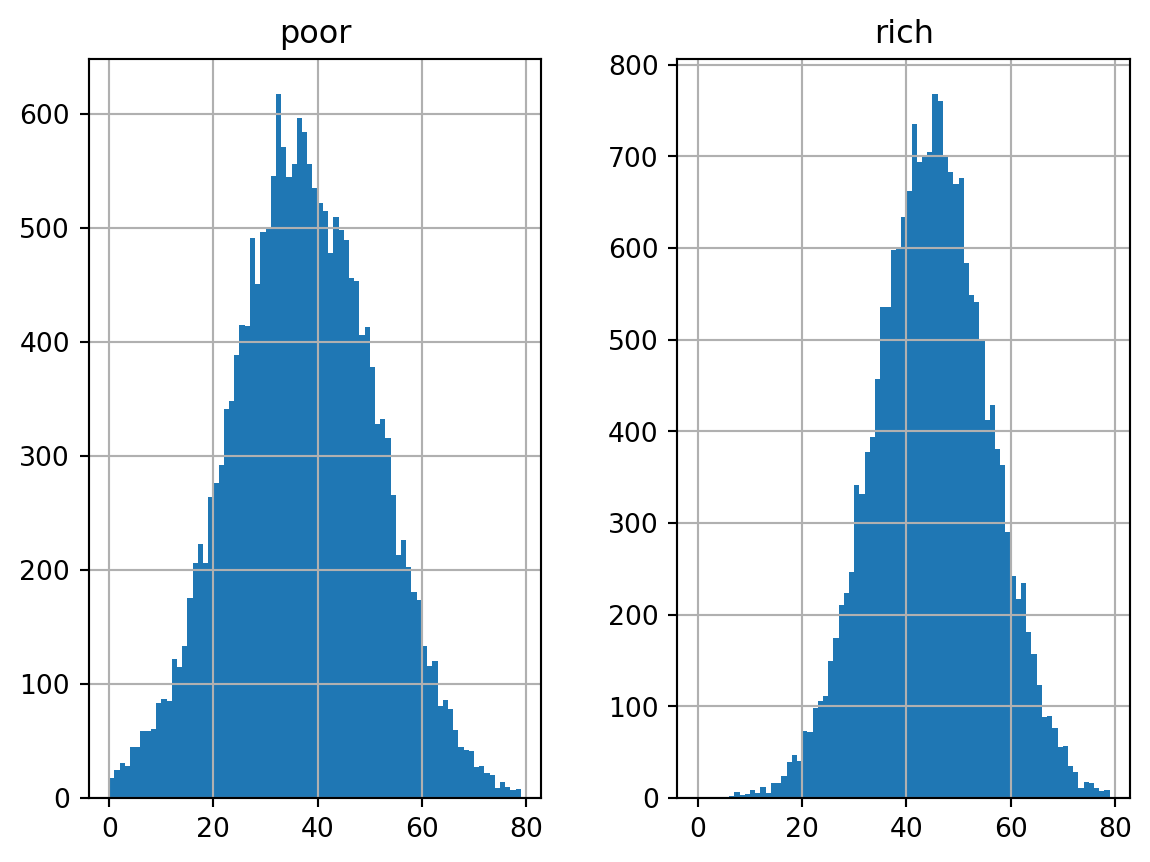
Let’s sample 20,000 above income threshold individuals and 20,000 below income threshold individuals.
From this sample we get have the following histograms.
Code
# original inspiration for this example from# https://www.cs.cmu.edu/~./awm/tutorials/gmm14.pdffrom scipy.stats import multivariate_normalnp.random.seed(4)df = pd.DataFrame(multivariate_normal.rvs(mean = np.array([37, 45]), cov = np.diag([196, 121]), size =20000), columns = ['below', 'above'])df.hist(bins =range(80), sharex =True, sharey=True, figsize=(12, 2))plt.show()
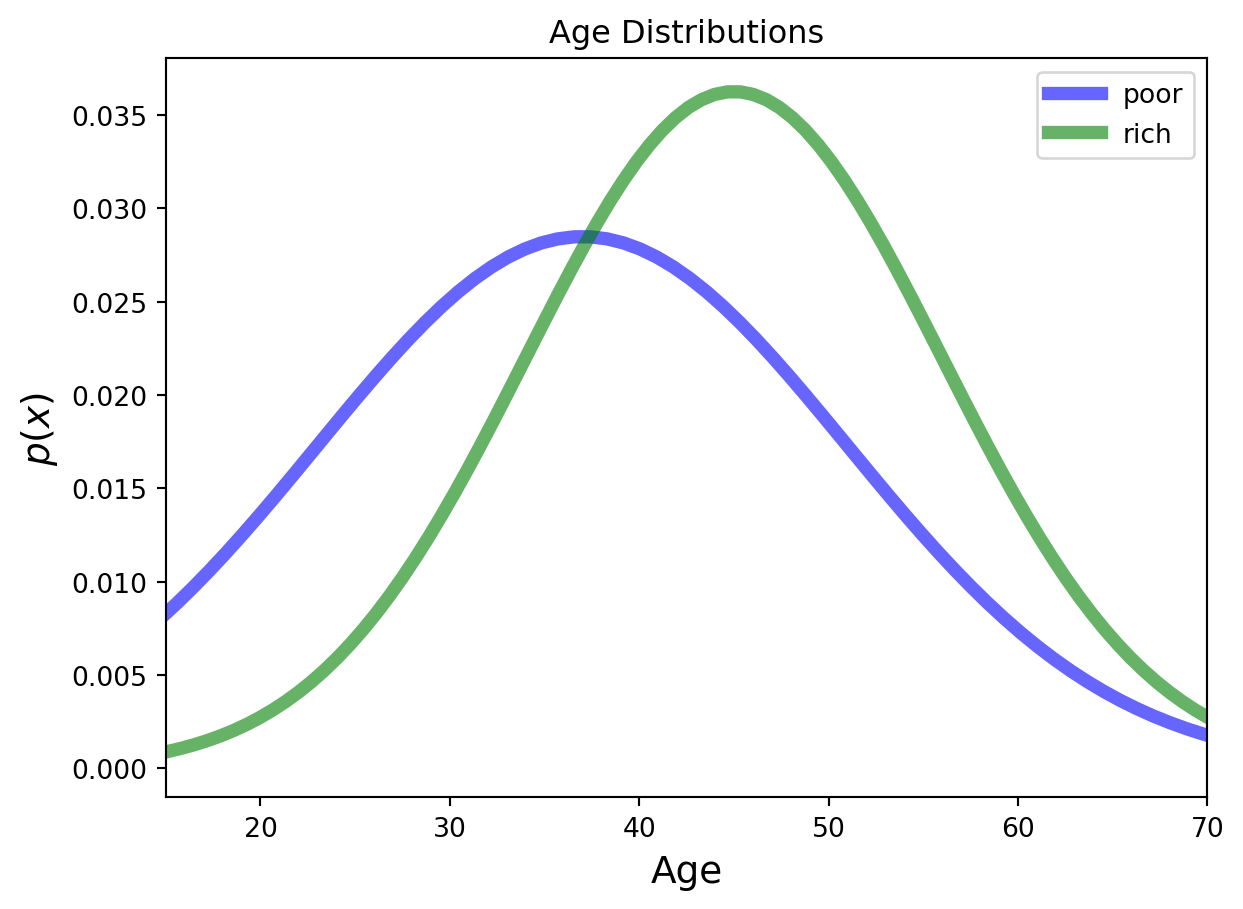
We find that ages of the below income threshold set have mean \(\mu=37\) with standard deviation \(\sigma=14\), while the ages of the above income threshold set have mean \(\mu=45\) with standard deviation \(\sigma=11\).
Income Level by Age
We can plot gaussian distributions for the two income levels.
Code
from scipy.stats import normplt.figure(figsize=(7, 4.5))x = np.linspace(norm.ppf(0.001, loc =37, scale =14), norm.ppf(0.999, loc =37, scale =14), 100)plt.plot(x, norm.pdf(x, loc =37, scale =14),'b-', lw =5, alpha =0.6, label ='below')x = np.linspace(norm.ppf(0.001, loc =45, scale =11), norm.ppf(0.999, loc =45, scale =11), 100)plt.plot(x, norm.pdf(x, loc =45, scale =11),'g-', lw =5, alpha =0.6, label ='above')plt.xlim([15, 70])plt.xlabel('Age', size=14)plt.legend(loc ='best')plt.title('Age Distributions')plt.ylabel(r'$p(x)$', size=14)plt.show()
Soft Clustering
two overlapping clusters.
given some particular individual at a given age, say 25, we cannot say for sure which cluster they belong to.
use probability to quantify our uncertainty about cluster membership.
Individual belongs to the cluster 1 with some probability \(p_1\) and the cluster 2 with a different probability \(p_2\).
Naturally we expect the probabilities to sum up to 1.
This is called soft assignment, and a clustering using this principle is called soft clustering.
Conditional Probability
More formally, we say that an object can belong to each particular cluster with some probability, such that the sum of the probabilities adds up to 1 for each object.
For example, assuming that we have two clusters \(C_1\) and \(C_2\), we can have that an object \(x_1\) belongs to \(C_1\) with probability \(0.3\) and to \(C_2\) with probability \(0.7\).
Note that the distribution over \(C_1\) and \(C_2\) only refers to object \(x_1\).
Maximum likelihood estimation is a method to estimate the parameters of a probability distribution given a sample of observed data that best fits the data.
Likelihood Function
The likelihood function \(L(\boldsymbol{\theta}, x)\) represents the probability of observing the given data \(x\) as a function of the parameters \(\boldsymbol{\theta}\) of the distribution.
The primary purpose of the likelihood function is to estimate the parameters that make the observed data \(x\) most probable.
The likelihood function for a set of samples \(x_{n}~\text{for}~n=1, \ldots, N\) drawn from an independent and identically distributed (i.i.d.) Gaussian distribution is
For a particular set of parameters \(\mu, \sigma^{2}\)
large values of \(L(\mu, \sigma^{2}, x_1, \ldots, x_n)\) indicate the observed data is very probable (high likelihood) and thus well modeled by the parameters
small values of \(L(\mu, \sigma^{2}, x_1, \ldots, x_n)\) indicate the observed data is very improbable (low likelihood) and thus poorly modeled by the parameters
The parameters that maximize the likelihood function are called the maximum likelihood estimates.
Log-likelihood
A common manipulation to obtain a more useful form of the likelihood function is to take its natural logarithm.
Advantages of the log-likelihood:
The log function is monotonically increasing, so the MLE is the same as the log-likelihood estimate
The product of probabilities becomes a sum of logarithms, which is more numerically stable
Using the log-likelihood we will be able to derive formulas for the maximum likelihood estimates.
Maximizing the log-likelihood
How do we maximize (optimize) a function of parameters?
To find the optimal parameters of a function, we compute partial derivatives of the function and set them equal to zero. The solution to these equations gives us a local optimal value for the parameters.
The full derivation of these results is provided here.
Tip: Try deriving these results yourself!
Summary of MLE
Given samples \(x_{1}, \ldots, x_n\) drawn from a Gaussian distribution, we compute the maximum likelihood estimates by maximizing the log likelihood function
We use this information to help our understanding of Gaussian Mixture models.
Gaussian Mixture Models
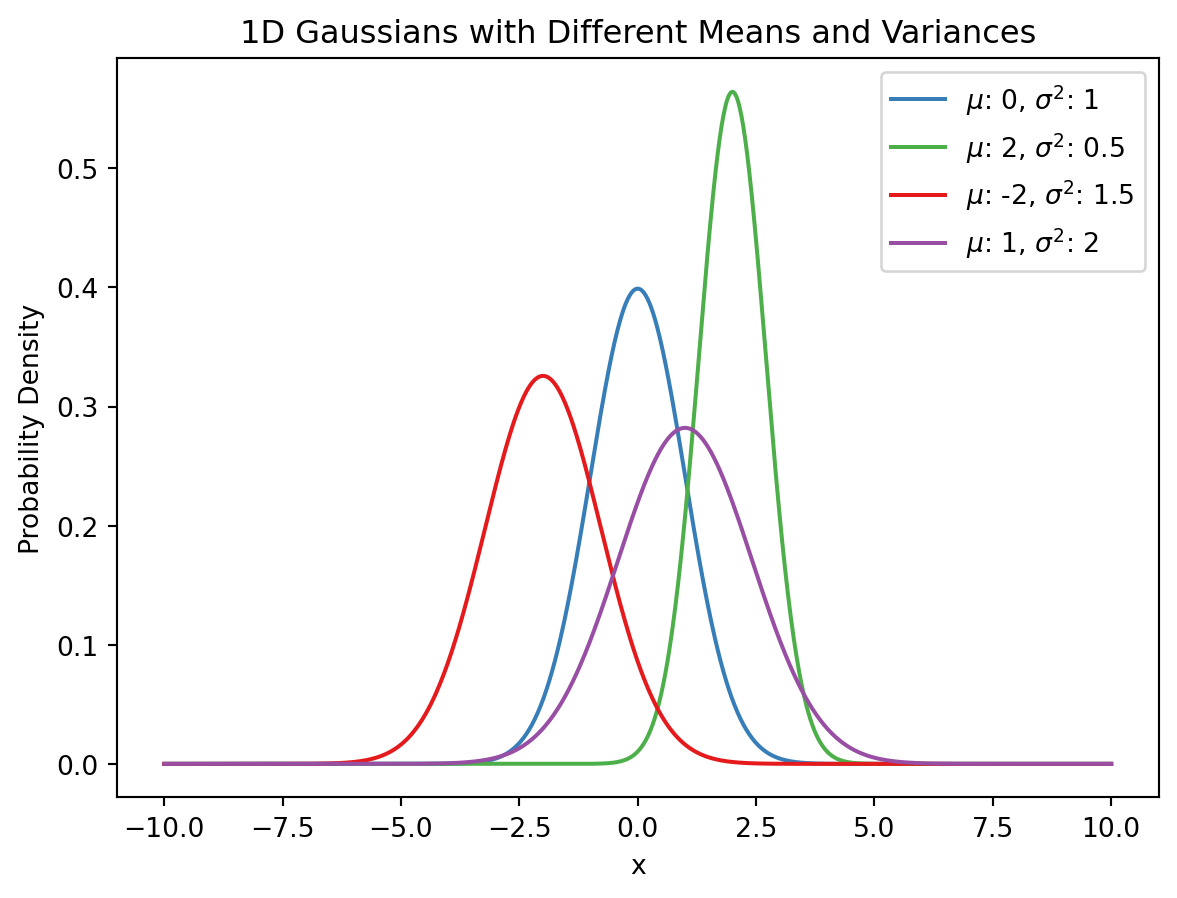
Univariate Gaussians
In GMMs we assume that each of our clusters follows a Gaussian (normal) distribution with their own parameters.
Code
import numpy as npimport matplotlib.pyplot as plt# Define the parameters for the 4 Gaussiansparams = [ {"mean": 0, "variance": 1, "color": "#377eb8"}, # Blue {"mean": 2, "variance": 0.5, "color": "#4daf4a"}, # Green {"mean": -2, "variance": 1.5, "color": "#e41a1c"}, # Red {"mean": 1, "variance": 2, "color": "#984ea3"} # Purple]# Generate x valuesx = np.linspace(-10, 10, 1000)# Plot each Gaussianfor param in params: mean = param["mean"] variance = param["variance"] color = param["color"]# Calculate the Gaussian y = (1/ np.sqrt(2* np.pi * variance)) * np.exp(- (x - mean)**2/ (2* variance))# Plot the Gaussian plt.plot(x, y, color=color, label=f"$\\mu$: {mean}, $\\sigma^2$: {variance}")# Add legendplt.legend()# Add title and labelsplt.title("1D Gaussians with Different Means and Variances")plt.xlabel("x")plt.ylabel("Probability Density")# Show the plotplt.show()
This is a similar situation to our previous example where we considered labeling a person as above or below an income threshold based on the single feature age.
This could be a hypothetical situation with \(K=4\) normally distributed clusters.
Multivariate Gaussians
Given data points \(\mathbf{x}\in\mathbb{R}^{d}\), i.e., \(d\)-dimensional points, then we use the multivariate Gaussian to describe the clusters. The formula for the multivariate Gaussian is
where \(\Sigma\in\mathbb{R}^{d\times d}\) is the covariance matrix, \(\vert \Sigma\vert\), denote the determinant of \(\Sigma\), and \(\boldsymbol{\mu}\) is the \(d\)-dimensional vector of expected values.
The covariance matrix is the multidimensional analog of the variance. It determines the extent to which vector components are correlated.
See here for a refresher on the covariance matrix.
Notation
The notation \(x \sim \mathcal{N}(\mu, \sigma^2)\) is used to denote a univariate random variable that is normally distributed with expected value \(\mu\) and variance \(\sigma^{2}.\)
The notation \(\mathbf{x} \sim \mathcal{N}(\boldsymbol{\mu}, \Sigma)\) is used to denote a multivariate random variable that is normally distributed with mean \(\boldsymbol{\mu}\) and covariance matrix \(\Sigma\).
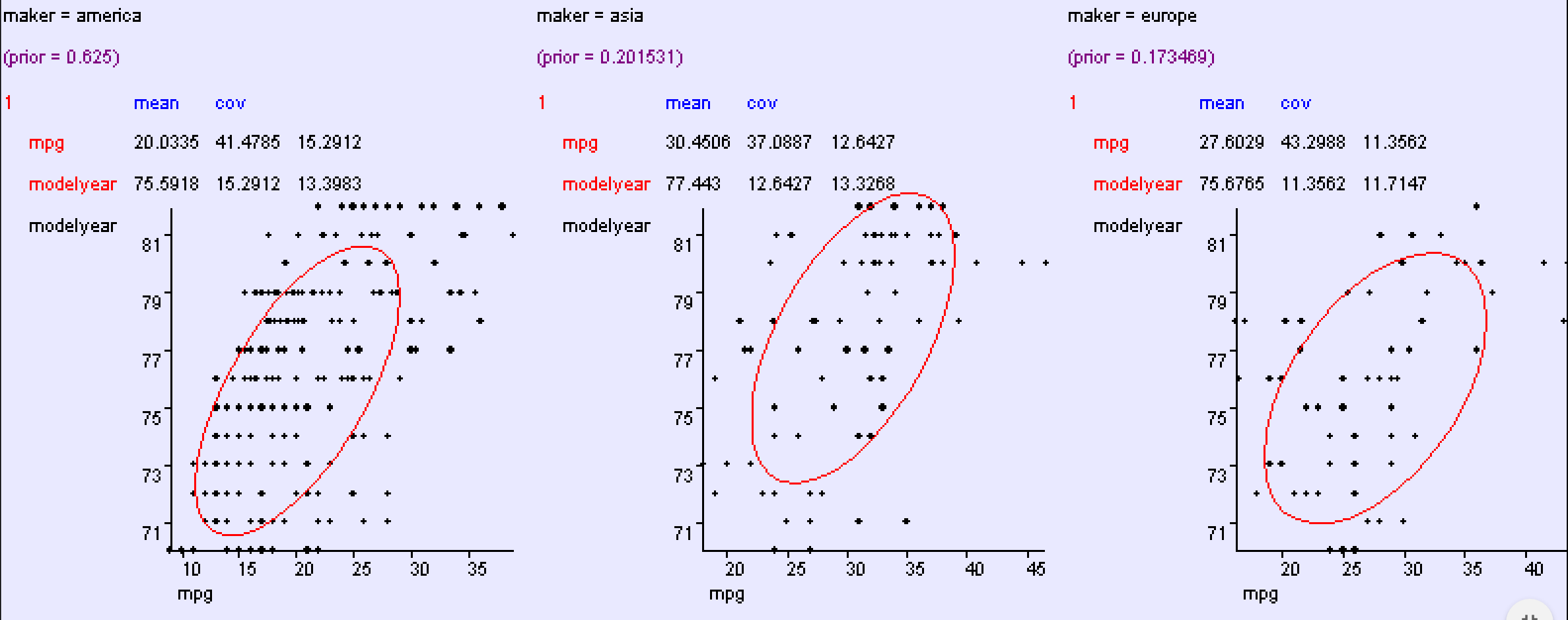
Multivariate Example: Cars
To illustrate a particular model, let us consider the properties of cars produced in the US, Europe, and Asia.
For example, let’s say we are looking to classify cars based on their model year and miles per gallon (mpg).
It seems that the data can be described (roughly) as a mixture of threemultivariate Gaussian distributions.
Expectation-Maximization for Gaussian Mixture Models
The Clustering Problem
Suppose we observe \(n\) data points \(X = \{x_1, x_2, \ldots, x_n\}\) in \(\mathbb{R}^d\) that appear to come from multiple clusters.
We want to model this data as a mixture of \(K\) Gaussian distributions, each representing a different cluster.
The Gaussian Mixture Model
A Gaussian Mixture Model (GMM) assumes each data point is generated by the following process:
Choose a cluster \(k \in \{1, 2, \ldots, K\}\) with probability \(\pi_k\) (where \(\sum_{k=1}^K \pi_k = 1\))
Generate the point from a Gaussian distribution: \(x_i \sim \mathcal{N}(\mu_k, \Sigma_k)\)
The probability density of observing point \(x_i\) is:
E-Step: Since we don’t know \(z_i\), we compute the expected value of the indicator \(\mathbb{1}(z_i = k)\), which is the posterior probability \(\gamma_{ik} = p(z_i = k \mid x_i, \theta^{(t)})\), where \(\theta^{(t)}\) is the parameter vector at iteration \(t\).
M-Step: With these soft assignments, maximizing the expected complete log-likelihood yields closed-form updates that look like weighted versions of the standard MLE formulas
This elegant approach transforms an intractable optimization problem into a simple iterative procedure with intuitive updates at each step.
We observe data points \(x_1, x_2, \ldots, x_n\) in \(d\)-dimensional space
We assume the data comes from \(K\) Gaussian distributions, each with mean \(\mu_k\), covariance \(\Sigma_k\), and mixing weight \(\pi_k\)
The latent variables are the cluster assignments \(z_i\) (which component generated each point)
Goal: Find parameters \(\theta = \{\mu_k, \Sigma_k, \pi_k\}_{k=1}^K\) that maximize the likelihood of the observed data
Initialization
Randomly initialize the \(K\) means \(\mu_k\) (or use k-means clustering)
Initialize covariances \(\Sigma_k\) (often as identity matrices or sample covariance)
Initialize mixing weights \(\pi_k = \frac{1}{K}\) (uniform distribution over components)
E-Step: Compute Responsibilities
For each data point \(x_i\) and each component \(k\), compute the responsibility \(\gamma_{ik}\) (the probability that point \(i\) belongs to component \(k\) given current parameters)
Each parameter update has an intuitive interpretation as a weighted MLE
Iteration and Convergence
Alternate between E and M steps until convergence
Monitor the log-likelihood: it’s guaranteed to increase (or stay the same) at each iteration
Stop when log-likelihood change falls below a threshold or after a maximum number of iterations
Note: EM finds a local maximum, so results depend on initialization (run multiple times with different initializations)
Key Intuition
E-step: Given current cluster parameters, probabilistically assign points to clusters
M-step: Given these soft assignments, update cluster parameters as if they were the true assignments
This 🐓 and 🥚 problem is resolved through iteration
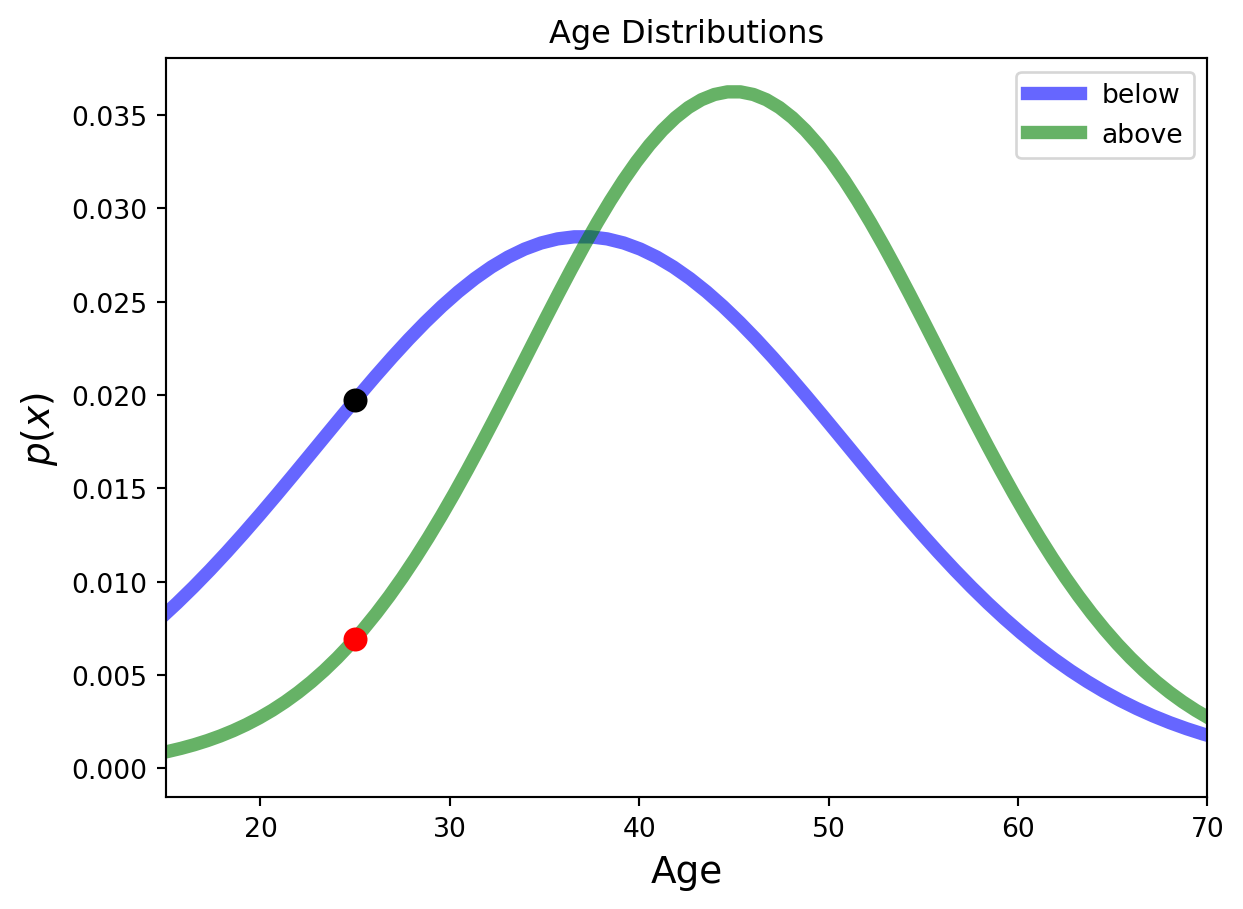
Income Level Example
We have
Our single data point \(x=25\), and
We have 2 Gaussians representing our clusters,
\(C_1\) with parameters \(\mu_1 = 37, \sigma_1^{2}=14\) and
\(C_2\) with parameters \(\mu_2 = 45, \sigma_2^{2}=11\),
Our latent variables are the probabilities that we classify someone as either above or below an income threshold, i.e., \[
\gamma_1 = P(z = 1) = P(\text{above income threshold})
\] and \[
\gamma_2 = P(z = 2) = P(\text{below income threshold}).
\]
Income Level Example, cont.
Our interest in this problem is computing the posterior probability, which is,
“red” = \(P(\text{age 25} | \text{above})\) and “black” = \(P(\text{age 25} | \text{below})\), and
\(P(\text{above})\) and \(P(\text{below})\) are the prior probabilities (mixing weights) that must sum to 1: \(P(\text{above}) + P(\text{below}) = 1\),
e.g. 0.5 in this example since we split the 20K points equally.
Convergence criteria
The convergence criteria for the Expectation-Maximization (EM) algorithm assess the change across iterations of either the
likelihood function, or
model parameters
with usually a limit on the maximum number of iterations.
\(\theta^{(t)}\) represents the model parameters (means, covariances, and weights) at iteration \(t\),
\(||\cdot||_2\) is the Euclidean (L2) norm,
\(\text{tol}\) is a small positive number.
Maximum Number of Iterations
The EM algorithm is typically capped at a maximum number of iterations to avoid long runtimes in cases where the log-likelihood or parameters converge very slowly or never fully stabilize.
\[
t > \text{max\_iterations}
\]
Where:
\(\text{max\_iterations}\) is a predefined limit (e.g., 100 or 500 iterations).
Storage and Computational Costs
It is important to be aware of the computational costs of our algorithm.
Storage costs:
There are \(N\)\(d\)-dimensional points
There are \(K\) clusters
There are \(N\times K\) coefficients \(r_{nk}\)
There are \(K\)\(d\)-dimensional cluster centers \(\boldsymbol{\mu}_k\)
There are \(K\)\(d\times d\) covariance matrices \(\Sigma_k\)
There are \(K\) weights \(w_k\)
Computational costs:
Computing each \(r_{nk}\) requires a sum of \(K\) evaluations of the Gaussian PDF.
Updating \(\gamma_k\) requires a division (though we must compute \(N_k\))
k-means vs GMMs
Let’s pause for a minute and compare GMM/EM with \(k\)-means.
GMM/EM
Initialize randomly or using some rule
Compute the probability that each point belongs in each cluster
Update the clusters (weights, means, and variances).
Repeat 2-3 until convergence.
\(k\)-means
Initialize randomly or using some rule
Assign each point to a single cluster
Update the clusters (means).
Repeat 2-3 until convergence.
From a practical standpoint, the main difference is that in GMMs, data points do not belong to a single cluster, but have some probability of belonging to each cluster.
In other words, as stated previously, GMMs use soft assignment.
For that reason, GMMs are also sometimes called soft \(k\)-means.
However, there is also an important conceptual difference.
The GMM starts by making an explicit assumption about how the data were generated.
It says: “the data came from a collection of multivariate Gaussians.”
We made no such assumption when we came up with the \(k\)-means problem. In that case, we simply defined an objective function and declared that it was a good one.
Nonetheless, it appears that we were making a sort of Gaussian assumption when we formulated the \(k\)-means objective function. However, it wasn’t explicitly stated.
The point is that because the GMM makes its assumptions explicit, we can
examine them and think about whether they are valid, and
replace them with different assumptions if we wish.
For example, it is perfectly valid to replace the Gaussian assumption with some other probability distribution. As long as we can estimate the parameters of such distributions from data (e.g., have MLEs), we can use EM in that case as well.
Versatility of EM
A final statement about EM generally. EM is a versatile algorithm that can be used in many other settings. What is the main idea behind it?
Notice that the problem definition only required that we find the clusters, \(C_i\), meaning that we were to find the \((\mu_i, \Sigma_i)\).
However, the EM algorithm posited that we should find as well the \(P(C_j|x_i) = P(z=j | x_i)\), that is, the probability that each point is a member of each cluster.
This is the true heart of what EM does.
By adding parameters to the problem, it actually finds a way to make the problem solvable.
These are the latent parameters we introduced earlier. Latent parameters don’t show up in the solution.
Examples
Example 1
Here is an example using GMM.
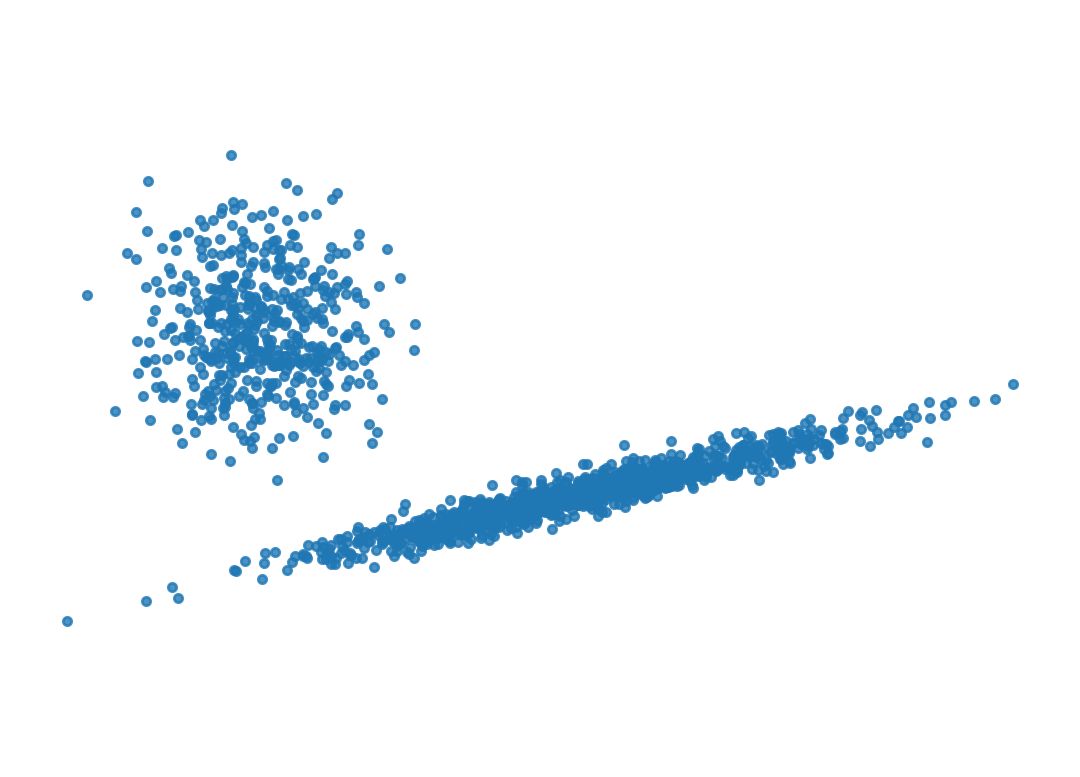
We’re going to create two clusters, one spherical, and one highly skewed.
Code
# Number of samples of larger componentn_samples =1000# C is a transfomation that will make a heavily skewed 2-D GaussianC = np.array([[0.1, -0.1], [1.7, .4]])print(f'The covariance matrix of our skewed cluster will be:\n{C.T@C}')
The covariance matrix of our skewed cluster will be:
[[2.9 0.67]
[0.67 0.17]]
Code
import warningswarnings.filterwarnings('ignore')rng = np.random.default_rng(0)# now we construct a data matrix that has n_samples from the skewed distribution,# and n_samples/2 from a symmetric distribution offset to position (-4, 2)X = np.r_[(rng.standard_normal((n_samples, 2)) @ C),.7* rng.standard_normal((n_samples//2, 2)) + np.array([-4, 2])]
Code
plt.scatter(X[:, 0], X[:, 1], s =10, alpha =0.8)plt.axis('equal')plt.axis('off')plt.show()
Code
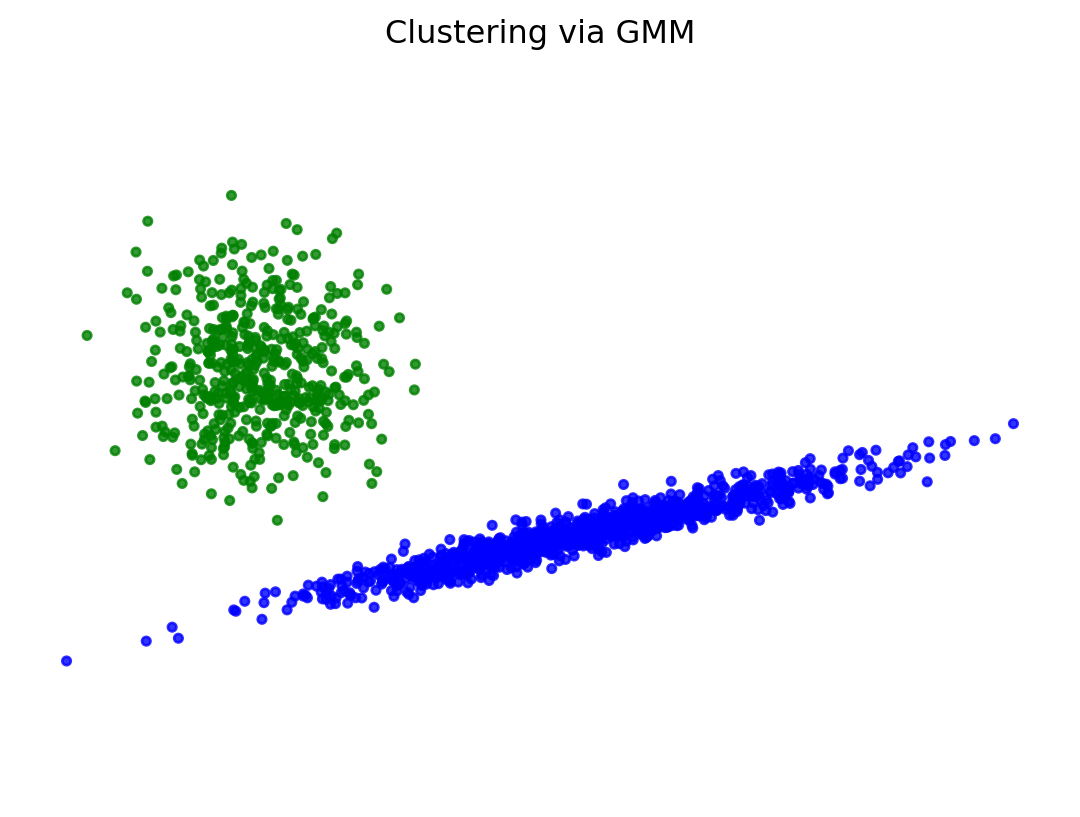
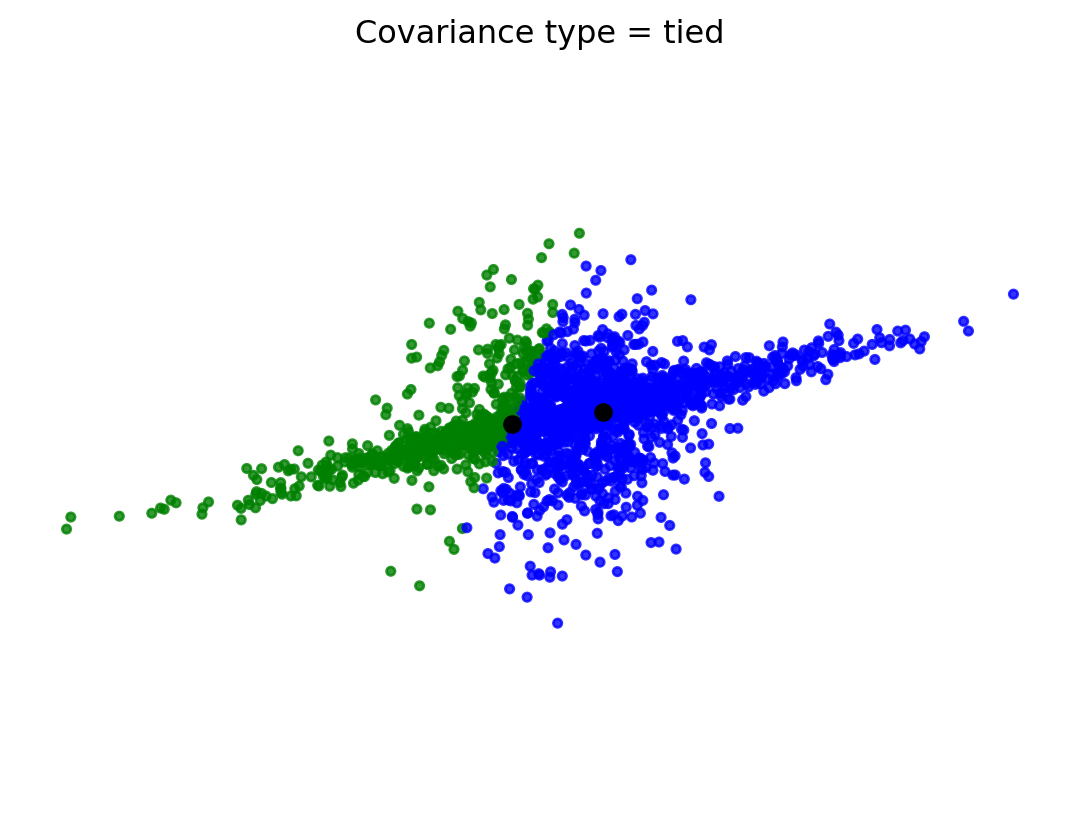
# Fit a mixture of Gaussians with EM using two componentsimport sklearn.mixturegmm = sklearn.mixture.GaussianMixture(n_components=2, covariance_type='full', init_params ='kmeans')y_pred = gmm.fit_predict(X)
Code
colors = ['bg'[p] for p in y_pred]plt.title('Clustering via GMM')plt.axis('off')plt.axis('equal')plt.scatter(X[:, 0], X[:, 1], color = colors, s =10, alpha =0.8)plt.show()
Code
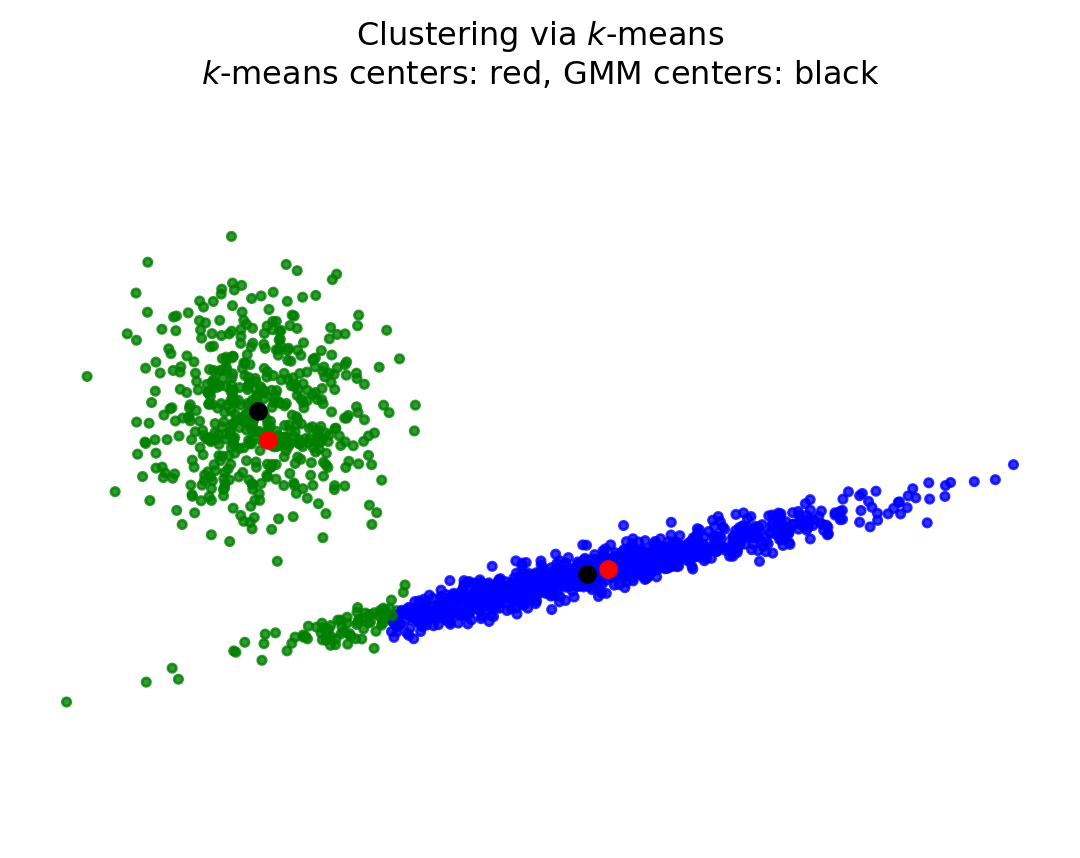
for clus inrange(2):print(f'Cluster {clus}:')print(f' weight: {gmm.weights_[clus]:0.3f}')print(f' mean: {gmm.means_[clus]}')print(f' cov: \n{gmm.covariances_[clus]}\n')
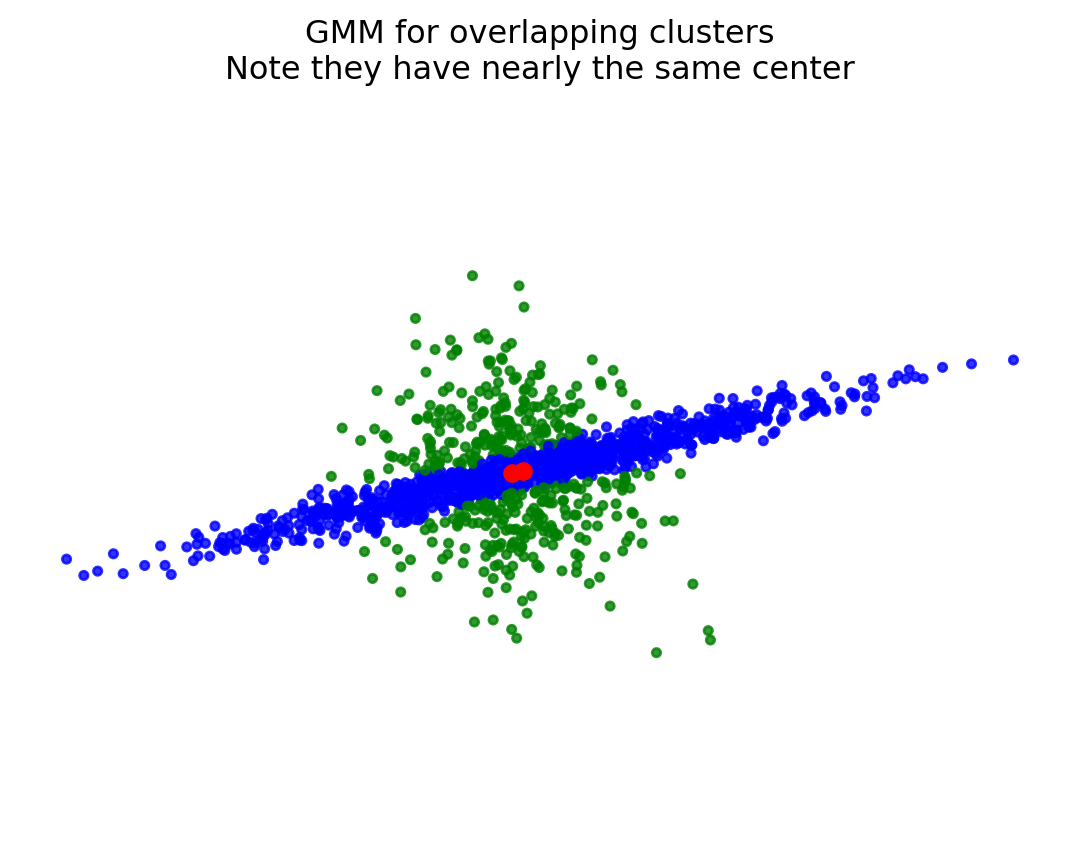
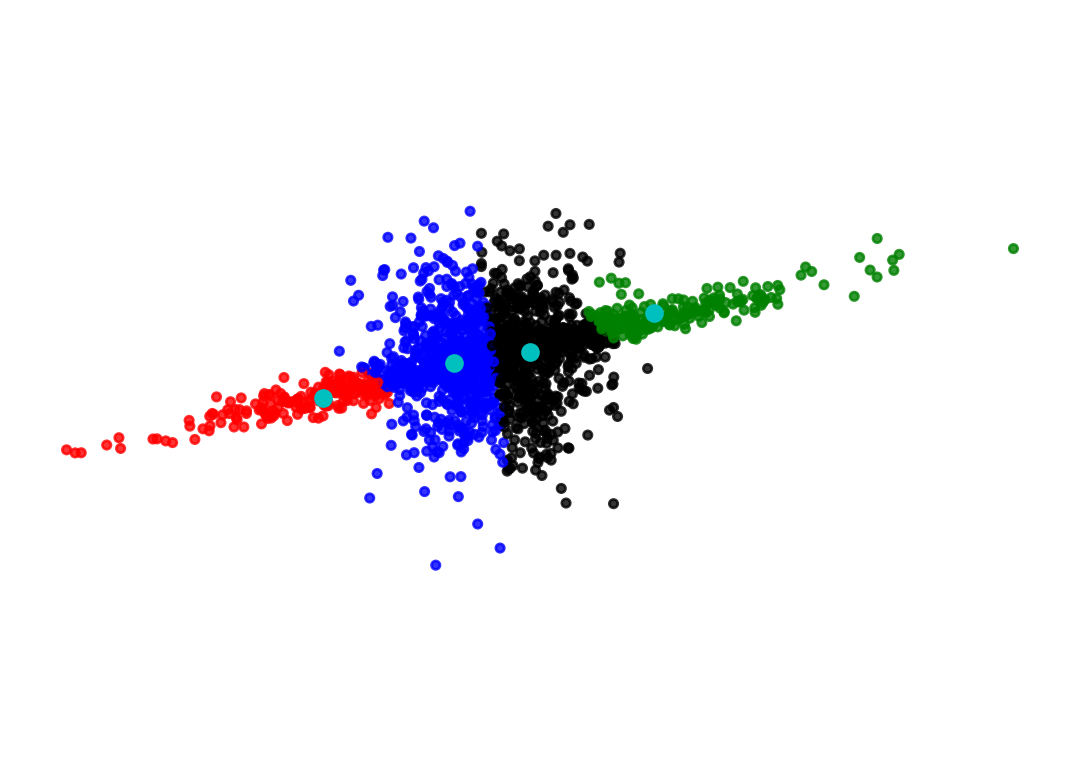
colors = ['bgrky'[p] for p in y_pred_over]plt.title('GMM for overlapping clusters\nNote they have nearly the same center')plt.scatter(X[:, 0], X[:, 1], color = colors, s =10, alpha =0.8)plt.axis('equal')plt.axis('off')plt.plot(gmm.means_[:,0], gmm.means_[:,1], 'ro')plt.show()
colors = ['bgrky'[p] for p in y_pred]plt.scatter(X[:, 0], X[:, 1], color=colors, s=10, alpha=0.8)plt.title('Covariance type = tied')plt.axis('equal')plt.axis('off')plt.plot(gmm.means_[:,0],gmm.means_[:,1], 'ok')plt.show()
Non-Skewed Clusters
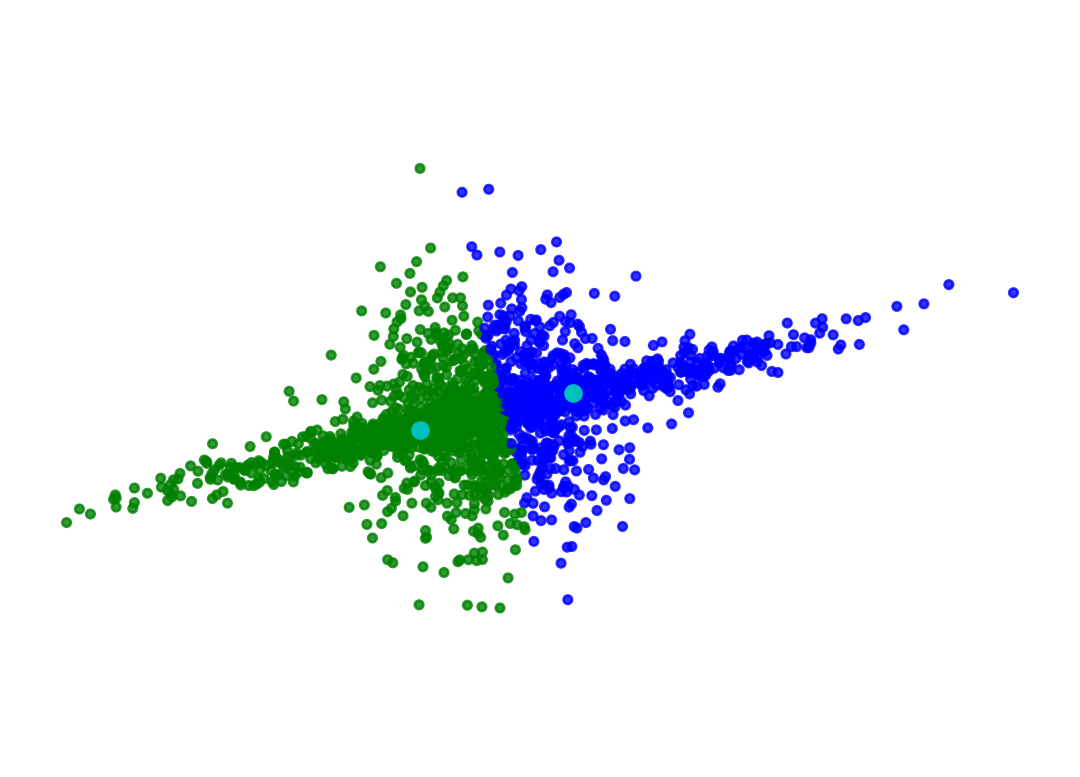
Perhaps you believe in even more restricted shapes: all clusters should have their axes aligned with the coordinate axes.
That is, clusters are not skewed.
Then you only need to estimate the diagonals of the covariance matrices - just \(Kd\) parameters.
This is specified by the GMM parameter covariance_type='diag'.
colors = ['bgrky'[p] for p in y_pred]plt.scatter(X[:, 0], X[:, 1], color = colors, s =10, alpha =0.8)plt.axis('equal')plt.axis('off')plt.plot(gmm.means_[:,0], gmm.means_[:,1], 'oc')plt.show()
Round Clusters
Finally, if you believe that all clusters should be round, then you only need to estimate the \(K\) variances.
This is specified by the GMM parameter covariance_type='spherical'.
colors = ['bgrky'[p] for p in y_pred]plt.scatter(X[:, 0], X[:, 1], color = colors, s =10, alpha =0.8)plt.axis('equal')plt.axis('off')plt.plot(gmm.means_[:,0], gmm.means_[:,1], 'oc')plt.show()