We’ll review the essentials of probability and statistics that we’ll need for this course.
Motivation
Why do we need knowledge of probability and statistics as a data scientist?
Data Analysis: Helps in understanding and interpreting data. Statistical methods allow you to summarize data (mean and variance) and identify patterns.
Model Building: Many machine learning algorithms are based on statistical principles. For example, linear regression and logistic regression rely on probability and statistics.
Uncertainty Quantification: Probability helps in quantifying uncertainty. This is crucial in making predictions and decisions based on data, as it allows you to estimate the likelihood of different outcomes.
Hypothesis Testing: Statistics provide tools for testing hypotheses and validating models. This is essential for determining whether the patterns observed in data are significant or just due to random chance.
Combined with linear algebra, probability and statistics provide the theoretical foundation and practical tools needed to extract meaningful insights from data and make data-driven decisions.
Probability
Probability
We all have a general sense of what is meant by probability. Probability is the study of randomness. It is the branch of mathematics that analyzes the chances (likelihood) of random events.
There are two different ways in which probability is interpreted. These views are
frequentist, and
Bayesian.
The Frequentist View
The frequentist view of probability requires the definition of several concepts.
Experiment: a situation in which the outcomes occur randomly.
Example: Driving to work, a commuter passes through a sequence of three intersections with traffic lights. At each light she either stops \(s\) or continues \(c\).
Sample space: the set of all possible outcomes of the experiment.
Example: \(\{ccc, ccs, csc, css, scc, ssc, scs, sss\},\) where \(csc\), for example, denotes the outcome that the commuter continues through the first light, stops at the second light, and continues through the third light.
Event: a subset of the sample space.
Example: continuing through the first light (i.e., \(\{ccc, ccs, csc, css\}\)).
The frequentist view is summarized by this quote from the first pages of Y. A. Rozanov. Probability Theory: A Concise Course. 1969.
Suppose an experiment under consideration can be repeated any number of times, so that, in principle at least, we can produce a whole series of “independent trials under identical conditions” in each of which, depending on chance, a particular event \(A\) of interest either occurs or does not occur.
Let \(n\) be the total number of experiments in the whole series of trials, and let \(n(A)\) be the number of experiement in which \(A\) occurs. Then the ratio \(n(A)/n\) is called the relative frequency of the event \(A.\)
It turns out that the relative frequencies observed in different series of trials are virtually the same for large \(n,\) clustering about some constant \(P(A),\) which is called the probability of the event \(A.\)
This is called the frequentist intepretation of probability.
The key idea in the above definition is to be able to:
produce a whole series of “independent trials under identical conditions”
Which, when you think about it, is really a rather tricky notion.
Nevertheless, the frequentist view of probability is quite useful and we will often use it in this course.
You can think of it as treating each event as a sort of idealized coin-flip.
In other words, when we use the frequentist view, we will generally be thinking of a somewhat abstract situation where we assume that “independent trials under identical conditions” is a good description of the situation.
The Bayesian View
To understand the Bayesian view of probability, consider the following situations.
On a visit to the doctor, we may ask, “What is the probability that I have disease X?”
Or, before digging a well, we may ask, “What is the probability that I will strike water?”
These questions are totally incompatible with the notion of “independent trials under identical conditions”!
Either I do, or do not, have disease X. Either I will, or will not, strike water.
What we are really asking is
“How certain should I be that I have disease X?”
“How certain should I be that I will strike water?”
In this setting, we are using probability to encode “degree of belief” or a “state of knowledge.”
This is called the Bayesian interpretation of probability.
Somewhat amazingly, it turns out that whichever way we think of probability (frequentist or Bayesian),
… the rules that we use for computing probabilities are exactly the same.
This is a very deep and surprising thing.
In other words, it’s often really a “state of knowledge” that we are really talking about when we use probability models in this course.
A thing appears random only through the incompleteness of our knowledge.
Spinoza, Ethics, Part 1
In other words, we use probability as an abstraction that hides details we don’t want to deal with.
So it’s important to recognize that both frequentist and Bayesian views are valid and useful views of probability.
Any simple idea is approximate; as an illustration, consider an object … what is an object? Philosophers are always saying, “Well, just take a chair for example.” The moment they say that, you know that they do not know what they are talking about any more. What is a chair? … every object is a mixture of a lot of things, so we can deal with it only as a series of approximations and idealizations.
The trick is the idealizations.
Richard Feynman, The Feynman Lectures on Physics, 12-2
Here is an illustration of this principle applied to probability:
In a serious work … an expression such as “this phenomenon is due to chance” constitutes simply, an elliptic form of speech. … It really means “everything occurs as if this phenomenon were due to chance,” or, to be more precise: “To describe, or interpret or formalize this phenomenon, only probabilistic models have so far given good results.”
Georges Matheron, Estimating and Choosing: An Essay on Probability in Practice
So, now, let’s talk about rules for computing probabilities.
Sample Space and Events
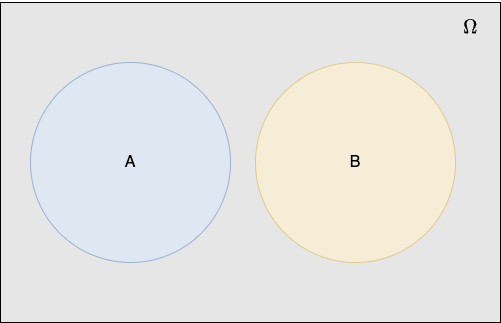
Definition. The sample space \(\Omega\) is the set of all possible outcomes of an experiment.
Definition. An event \(E\subset\Omega\) is an outcome, or a set of outcomes of an experiment.
Examples:
Rolling a dice: \(\Omega = \{1, 2, 3, 4, 5, 6 \}\), \(E = \text{Rolling a 2}.\)
Flipping a coin 2 times: \(\Omega = \{ (H, H), (H, T), (T, H), (T, T)\}\), \(E=\text{Rolling a heads and a tail}\).
Distance a car travels before breaking down: \(\Omega = \mathbb{R}_{+}\), \(E=\text{
Travels greater than 100 miles}.\)
Location of a dart thrown at a target. What is \(\Omega\) in this case? What is an event \(E\)?
The sample space \(\Omega\) may be continuous or discrete and bounded or unbounded.
Sample Space and Events – Example
You have a jar with three types of candies: (C)hocolates, (G)ummies, and (M)ints.
You randomly select three candies from the jar.
The sample space \(\Omega = \ldots\)
An example event, \(E = \ldots\)
Image by Gemini
Probability and Conditioning
Definition. Consider a sample space \(\Omega\). A probability measure on \(\Omega\) is a function \(P(\cdot)\) defined on all the subsets of \(\Omega\) (the events) such that:
\(P(\Omega) = 1\)
For any event \(A \subset \Omega\), \(P(A) \geq 0.\)
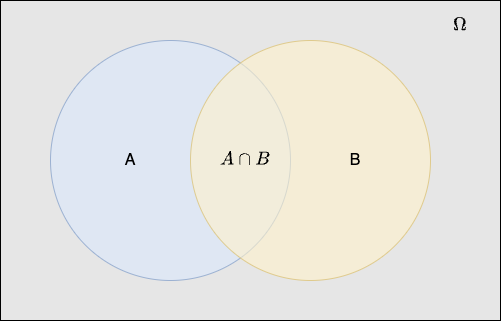
For any events \(A, B \subset \Omega\) where \(A \cap B = \emptyset\), \(P(A \cup B) = P(A) + P(B)\).
When \(A \cap B \neq \emptyset\), \(P(A \cup B) = P(A) + P(B) - P(A \cap B)\).
Often we want to ask how a probability measure changes if we restrict the sample space to be some subset of \(\Omega\).
This is called conditioning.
Definition. The conditional probability of an event \(A\) given that event \(B\) (having positive probability) is known to occur, is
The function \(P(\cdot|B)\) is a probability measure over the sample space \(B\).
Note that in the expression \(P(A|B)\), \(A\) is random but \(B\) is fixed.
Now if \(B\) is a proper subset of \(\Omega,\) then \(P(B) < 1\). So \(P(\cdot|B)\) is a rescaling of the quantity \(P(A\cap B)\) so that \(P(B|B) = 1.\)
Probability Multiplication Rule
The probability multiplication rule is a simple consequence of the definition of conditional probability.
\[
P(A \cap B) = P(A|B) P(B)
\]
This can be extended to three events \(A\), \(B\), and \(C\) as follows:
\[
P(A \cap B \cap C) = P(A|B \cap C) P(B \cap C) = P(A|B \cap C)P(B|C)P(C)
\]
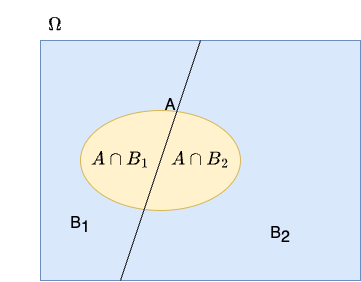
Law of total probability
An important tool for computing probabilities is provided by the law of total probabilities.
Let \(B_1\) and \(B_2\) form the complete sample space \(\Omega\) and be disjoint \(\left(B_1 \cap B_2 = \emptyset\right)\). Then for any event \(A\),
Bayes’ Theorem is a simple way of manipulating conditional probabilities in a way that can be very useful.
Let \(A,B\) be events, then
\[
P(A|B) = \frac{P(B|A)P(A)}{P(B)}.
\]
The terms in the above equation are often given the following names:
\(P(A)\) is the prior probability of \(A\) – initial belief before new evidence.
\(P(A|B)\) is the posterior probability of \(A\) – updated belief after new evidence.
\(P(B|A)\) is the likelihood of \(B\) – probability of observing evidence given a particular belief.
\(P(B)\) is the marginal probability of \(B\) – total probability of observing the evidence under all possible causes.
We can extend this theorem to more than two events.
Start with a situation in which we are interested in two events, \(A_1\) and \(A_2\). Let \(B\) be any event in the samples space \(\Omega\).
These are exhaustive, meaning that in any experiment either \(A_1\) or \(A_2\) must occur. This means they form a partition of \(\Omega\), i.e., \(\Omega = A_1 \cup A_2\) and \(A_1 \cap A_2 = \emptyset\).
Answer: If a package arrives on time, there’s approximately a 22.4% chance it was delivered by drone.
Key Insight:
Even though drones have the highest on-time rate (95%), most on-time packages still come by truck because trucks handle the majority of deliveries (65% of packages).
Prior probabilities heavily influence posterior probabilities even with strong likelihood evidence.
Bayes’ Theorem Example
Empirical evidence suggests that amongs sets of twins, about 1/3 are identical.
Assume therefore that probability of a pair of twins being identical to be 1/3.
Now, consider how a couple might update this probability after they get an ultrasound that shows that the twins are of the same gender.
What is their new estimate of the probability that their twins are identical?
Let \(I\) be the event that the twins are identical. Let \(G\) be the event that gender is the same via ultrasound.
The prior probability here is \(P(I)\).
What we want to calculate is the posterior probability \(P(I|G)\).
First, we note:
\[P(G|I) = 1.\]
Surprisingly, people are sometimes confused about that fact!
We also assume that if the twins are not identical, they are like any two siblings. This means they have an equal probability of being the same gender, i.e.,
\[P(G|\bar{I}) = 1/2.\]
We know from observing the population at large that among all sets of twins, about 1/3 are identical
So we have updated our estimate of the twins being identical from 1/3 (prior probability) to 1/2 (posterior probability).
We did this in a way that used quantities that were relatively easy to obtain or measure.
Independent Events
Definition. Two events \(A\) and \(B\) are independent if \(P(A\cap B) = P(A) \cdot P(B).\)
For example, consider rolling a die and flipping a coin. The result of the coin flip does not affect the result of the die roll. Therefore, the events are independent.
This is exactly the same as saying that \(P(A|B) = P(A).\)(Prove this to yourself using the definition of conditional probability.)
So we can see that the intuitive notion of independence is that “if one event occurs, that does not change the probability of the other event.”
Random Variables
Random Variables
When an experiment is performed, we might be interested in the actual outcome. However, more frequently we are interested in some function of the outcome. This leads us to the notion of a random variable.
Definition. A random variable \(X\) is a function \(X:\Omega\rightarrow \mathbb{R}\).
We generally use capital letters to denote random variables and lowercase to denote non-random quantities.
We distinguish between discrete and continuous random variables.
Discrete random variables
A discrete random variable is a random variable that can take on only a finite or at most a countably infinite number of values.
Examples
The number of points showing after a roll of a die.
The number of heads after flipping a coin twice.
The number of people arriving at a train station between 8 and 9 AM.
Continuous random variables
A continuous random variable is a random variable that can take on any value from a given range. That is, a continuous random variable has an uncountable set of possible outcomes.
Examples
The lifetime of a light bulb.
The distance a car travels before breaking down.
Distributions
To collect information about what values of random variable are more probable than others, we introduce the concept of distributions.
We have two options to consider:
discrete distributions using the probability mass function (PMF), and
continuous distributions using the probability density function (PDF).
We will also introduce the cumulative distribution functions corresponding to both PMFs and PDFS.
Discrete Distributions
Probability Mass Function
Definition. For a discrete random variable \(X\), we define the probability mass function (PMF)\(p(a)\) of \(X\) by
\[p(a) = P(X=a).\]
The PMF \(p(a)\) is positive for at most a countable number of values of \(a\). That is, if \(X\) must assume one of the values \(x_1, x_2,...,\) then
\[\begin{align*}
&p(x_i) \geq 0 \: \text{ for } i=1,2,... \\
&p(x) = 0 \: \text{ for all other values of } x.
\end{align*}\]
Since \(X\) must take on one of the values \(x_i\), we have
\[\sum_{i=1}^{\infty} p(x_i) = 1.\]
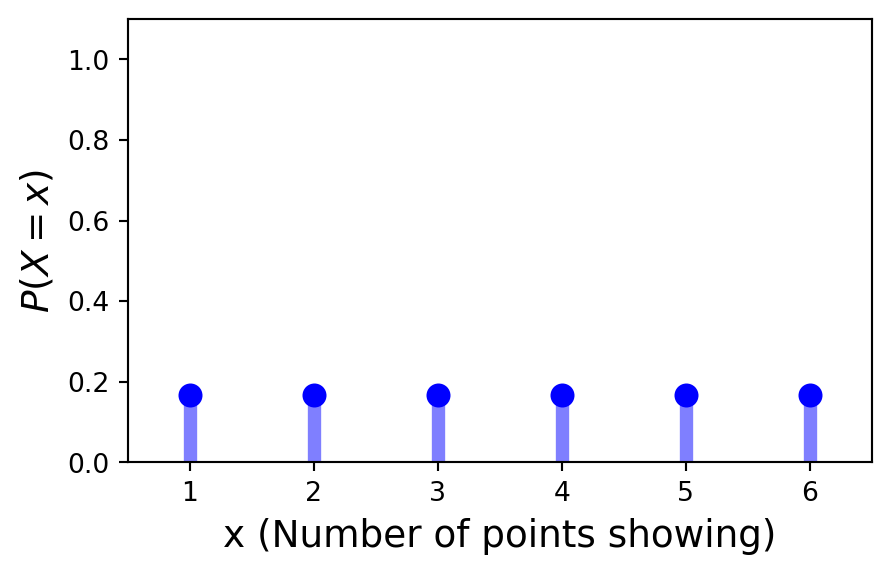
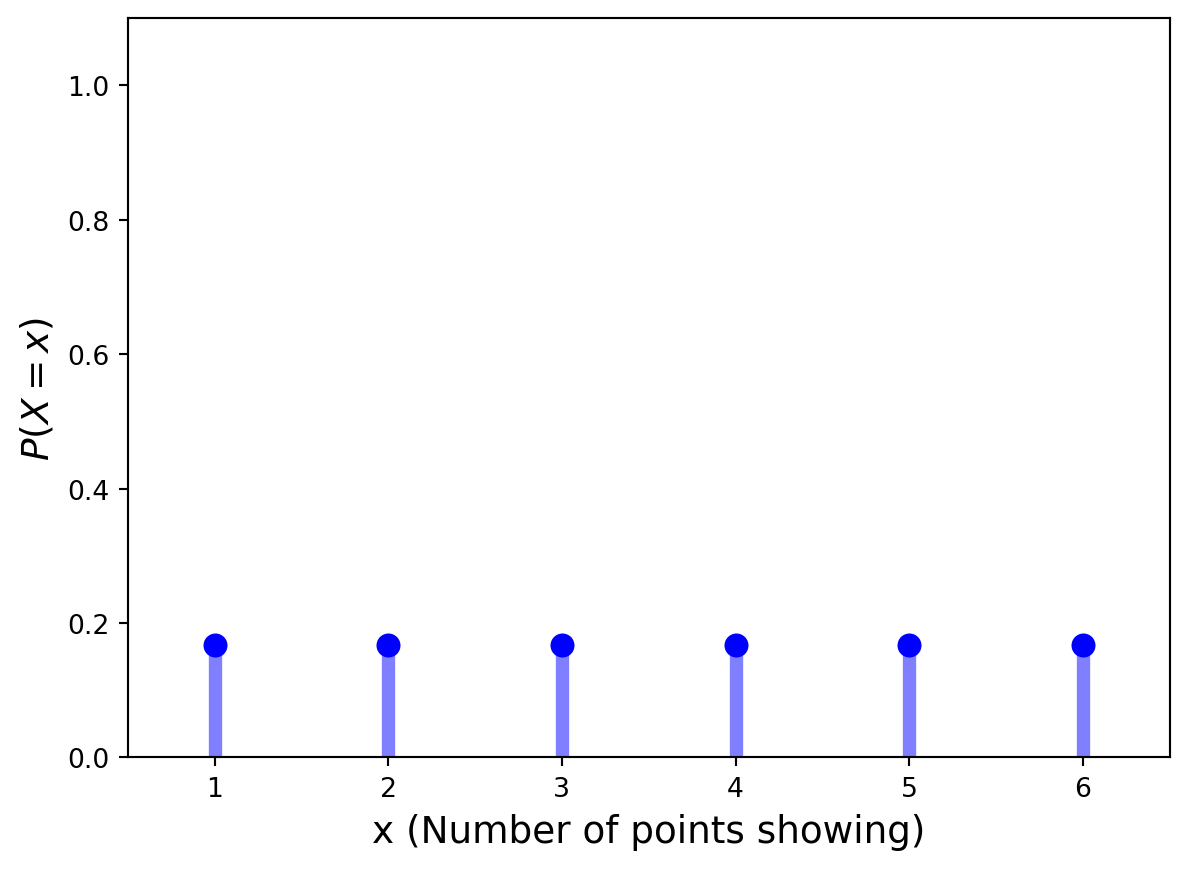
Example. Consider the roll of a single die. The random variable here is the number of points showing. What is the PDF of this discrete random variable?
We assign equal probabilities to each outcome \(\Omega = \{1, 2, 3, 4, 5, 6\}\):
Definition. The cumulative distribution function (CDF)\(F\) can be expressed in terms of \(p(a)\) by
\[F(a) = P(X \leq a) = \sum_{x\leq a} p(x).\]
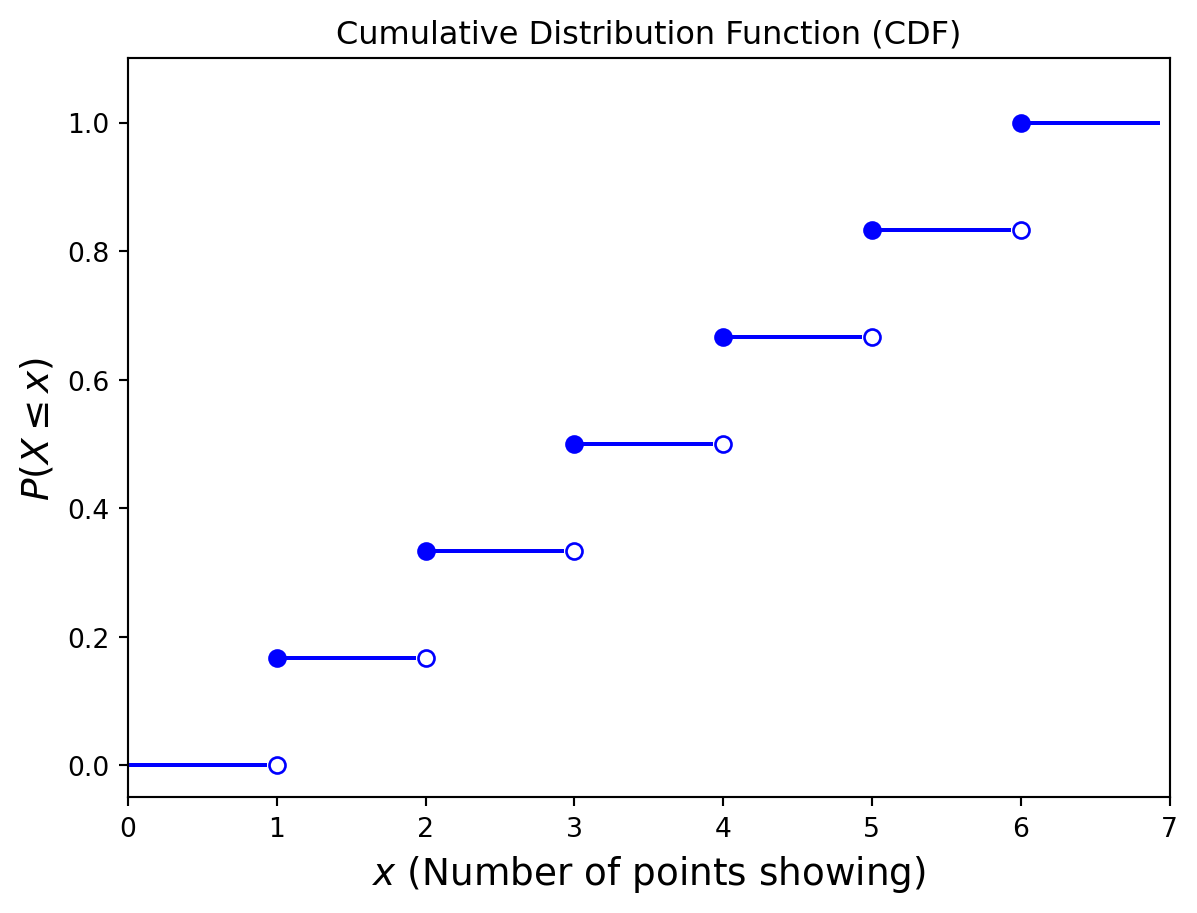
If \(X\) is a discrete random variable whose possible values are \(x_1 , x_2 , x_3 ,...\), where \(x_1 < x_2 < x_3 <...\), then the distribution function \(F\) of \(X\) is a step function. That is, the value of \(F\) is constant in the intervals \([x_{i−1},x_i)\) and then takes a step (or jump) of size \(p(x_i)\) at \(x_i\).
Example. Let us return to the roll of a single die. The corresponding CDF is shown below.
Code
plt.figure()for i inrange(7): plt.plot([i, i+1-.08], [i/6, i/6],'-b')for i inrange(1, 7): plt.plot(i, i/6, 'ob') plt.plot(i, (i-1)/6, 'ob', fillstyle ='none')plt.xlim([0, 7])plt.ylim([-0.05, 1.1])plt.title('Cumulative Distribution Function (CDF)')plt.xlabel(r'$x$(Number of points showing)', size=14)plt.ylabel(r'$P(X\leq x)$', size=14)plt.show()
Continuous Distributions
Probability Density Function
Continuous random variables are described by their probability density functions (PDFs). If \(f\) is a PDF, then it has the following properties:
\(f(x) \geq 0,\)
\(\int_{- \infty}^{\infty} f(x) dx = 1.\)
The probability density function plays a central role in probability theory, because all probability statements about a continuous random variable can be answered in terms of its PDF.
For instance, for a continuous variable \(X\) where \(P(X\leq a) = \int_{-\infty}^a f(x) dx\), we obtain
\[
P(a \leq X \leq b) = \int_{-\infty}^b f(x) dx - \int_{-\infty}^a f(x) dx = \int_a^b f(x) dx.
\]
Continuous Cumulative Distribution Function
Definition. The cumulative distribution function (CDF)\(F\) can be expressed as
\[F(a) = P(X\leq a) = \int_{-\infty}^a f(x) dx.\]
So continuing from the previous slide:
\[
P(a \leq X \leq b) = \int_{-\infty}^b f(x) dx - \int_{-\infty}^a f(x) dx = F(b) - F(a).
\]
The relationship between the continuous CDF and PDF is
\[f(x) = \frac{d F(x)}{dx}.\]
The above formula tells us that the PDF is the derivative of the CDF.
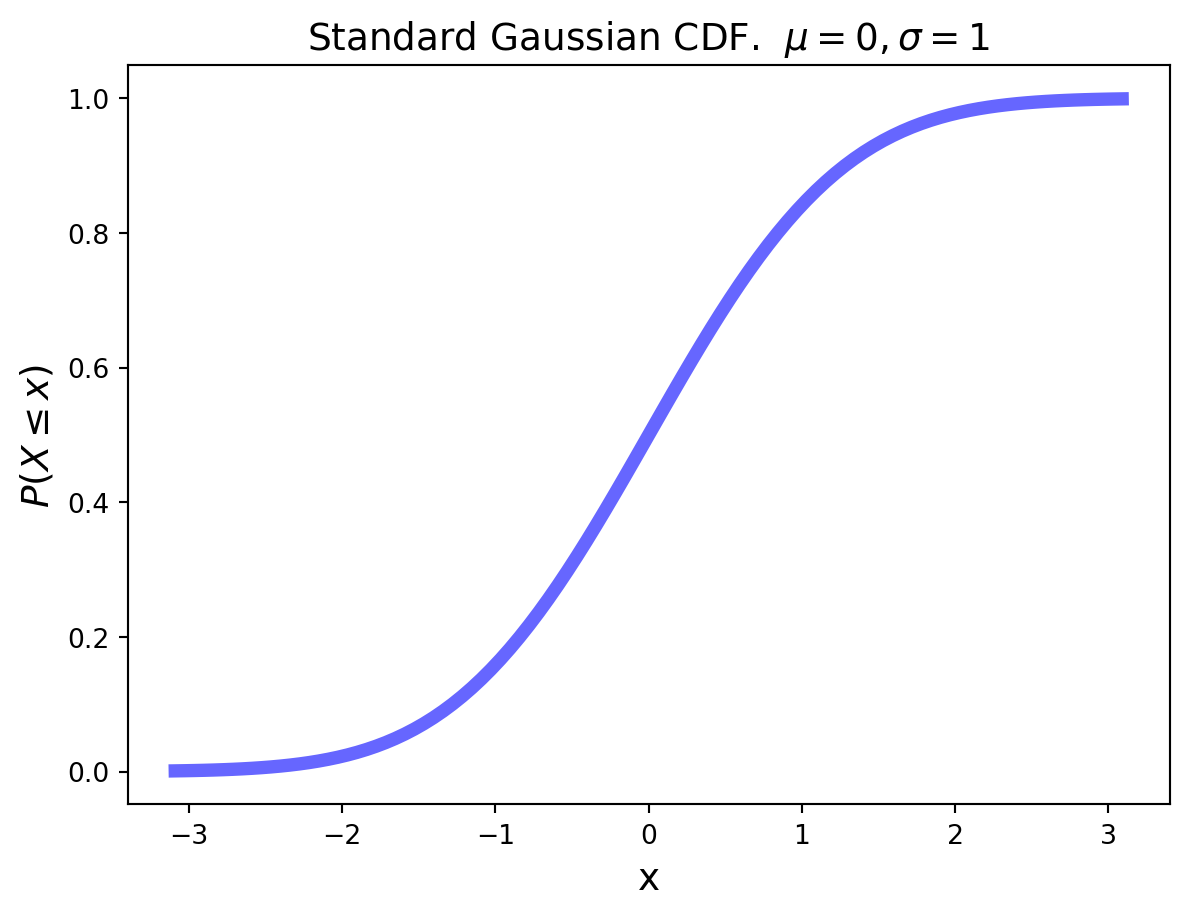
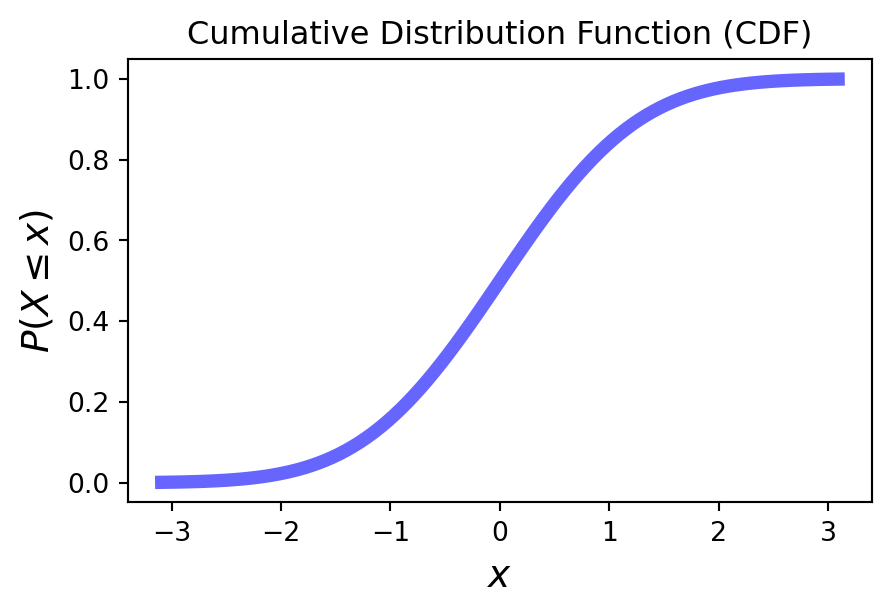
Here is an example of a continuous CDF of some random variable.
Code
from scipy.stats import normplt.figure(figsize=(5, 3))x = np.linspace(norm.ppf(0.001), norm.ppf(0.999), 100)plt.plot(x, norm.cdf(x),'b-', lw=5, alpha=0.6)plt.title('Cumulative Distribution Function (CDF)')plt.xlabel(r'$x$', size=14)plt.ylabel(r'$P(X\leq x)$', size=14)plt.show()
Characterizing Random Variables
Definition. The expected value\(E[X]\) of a random variable \(X\) is the probability-weighted sum or integral of all possible values of the R.V.
For a discrete random variable, this is:
\[E[X] \equiv \sum_{x} x \cdot P(X=x).\]
For a continuous random variable with pdf \(p()\)
\[E[X] \equiv \int_{-\infty}^{+\infty} x p(x) dx.\]
The expected value is also called the average or the mean, although we prefer to reserve those terms for empirical statistics (actual measurements, not idealizations like these formulas).
The expected value is in some sense the “center of mass” of the random variable. It is often denoted \(\mu\).
Expected Value Example: Food Delivery App
Scenario:
You’re working for a food delivery app which takes a 20% commission on every food delivery order.
You’re considering partnering with a new restaurant and need to calculate if the partnership would be profitable.
Your delivery costs are $3.50 per delivery.
Given Information:
The restaurant offers three meal categories with different prices and order probabilities
You need to calculate the expected profit per order to decide if the partnership is worthwhile
Data:
Appetizers: $8 each, ordered 15% of the time
Main Courses: $18 each, ordered 70% of the time
Desserts: $6 each, ordered 15% of the time
Question: What is the expected meal price per order?
Solution:
Let \(X\) be the meal price per order. We need to calculate \(E[X]\).
We use the symbol \(\sigma^2\) to denote variance.
The units of variance are the square of the units of the mean.
So to compare variance and mean in the same units, we take the square root of the variance.
This is called the standard deviation and is denoted \(\sigma\).
Mean and Variance Example
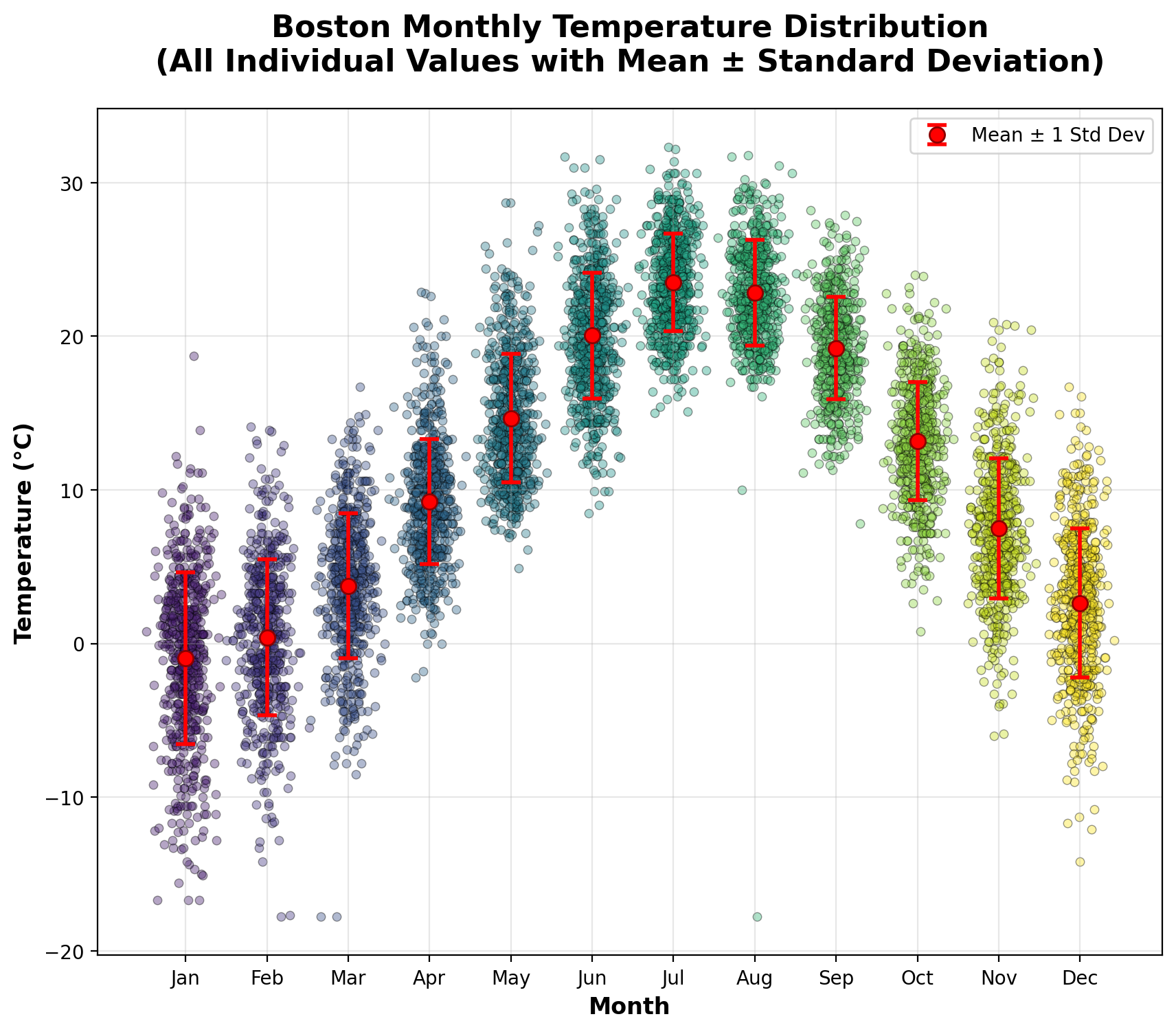
Let’s look at the average monthly temperatures in Boston from 1936 – 2025.
Code
"""Boston Historical Temperature Analysis=====================================This script downloads historical monthly temperature data for Boston over the last 100 years,calculates statistics for each month, and creates scatter plots showing all individual valueswith mean and standard deviation error bars.Data Source: NOAA Climate Data Online (CDO) APIStation: Boston Logan International Airport (USW00014739)"""import pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport requestsimport numpy as npfrom datetime import datetime, timedeltaimport warningswarnings.filterwarnings('ignore')# Set up plotting styleplt.style.use('default')sns.set_palette("husl")def download_boston_temperature_data():""" Download historical temperature data for Boston from NOAA CDO API. Returns: pandas.DataFrame: Temperature data with columns for date, month, and temperature """print("Downloading Boston temperature data from NOAA...")# Boston Logan International Airport station ID station_id ="USW00014739"# Calculate date range for last 100 years end_date = datetime.now() start_date = end_date - timedelta(days=365*100)# Format dates for API start_str = start_date.strftime("%Y-%m-%d") end_str = end_date.strftime("%Y-%m-%d")# NOAA CDO API endpoint base_url ="https://www.ncei.noaa.gov/access/services/data/v1"# Parameters for the API request params = {'dataset': 'daily-summaries','stations': station_id,'startDate': start_str,'endDate': end_str,'dataTypes': 'TMAX,TMIN,TAVG','format': 'json','units': 'metric' }try:# Make API request response = requests.get(base_url, params=params, timeout=30) response.raise_for_status()# Convert to DataFrame data = response.json() df = pd.DataFrame(data)if df.empty:print("No data returned from API. Trying alternative approach...")return download_alternative_data()# Convert date column df['DATE'] = pd.to_datetime(df['DATE'])# Convert temperature columns to numeric, handling missing values temp_columns = ['TMAX', 'TMIN', 'TAVG']for col in temp_columns:if col in df.columns: df[col] = pd.to_numeric(df[col], errors='coerce')# Add month column df['MONTH'] = df['DATE'].dt.month df['YEAR'] = df['DATE'].dt.yearprint(f"Downloaded {len(df)} temperature records")return dfexceptExceptionas e:print(f"Error downloading from NOAA API: {e}")returnNonedef calculate_monthly_statistics(df):""" Calculate average and standard deviation for each month. Args: df (pandas.DataFrame): Temperature data Returns: pandas.DataFrame: Monthly statistics """print("Calculating monthly statistics...")# Calculate monthly statistics for average temperature monthly_stats = df.groupby('MONTH')['TAVG'].agg(['mean', 'std', 'count', 'min', 'max' ]).round(2)# Add month names month_names = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun','Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'] monthly_stats['MONTH_NAME'] = [month_names[i-1] for i in monthly_stats.index]print("\nMonthly Temperature Statistics (Celsius):")print("="*50)print(f"{'Month':<6}{'Mean':<8}{'Std':<8}{'Count':<8}{'Min':<8}{'Max':<8}")print("-"*50)for month, row in monthly_stats.iterrows():print(f"{row['MONTH_NAME']:<6}{row['mean']:<8.1f}{row['std']:<8.1f} "f"{row['count']:<8.0f}{row['min']:<8.1f}{row['max']:<8.1f}")return monthly_statsdef create_scatter_plot_with_error_bars(df, monthly_stats):""" Create a scatter plot showing all individual temperature values for each month with mean and standard deviation error bars. Args: df (pandas.DataFrame): Temperature data monthly_stats (pandas.DataFrame): Monthly statistics """print("Creating scatter plot with error bars...")# Set up the plot plt.figure(figsize=(10, 8))# Month names for x-axis month_names = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun','Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']# Create scatter plot for each monthfor month inrange(1, 13): month_data = df[df['MONTH'] == month]['TAVG'].dropna()iflen(month_data) >0:# Add some jitter to x-coordinates to spread out points x_jitter = np.random.normal(month, 0.15, len(month_data))# Create scatter plot with transparency plt.scatter(x_jitter, month_data, alpha=0.4, s=20, color=plt.cm.viridis(month/12), edgecolors='black', linewidth=0.5)# Add error bars for mean ± std means = monthly_stats['mean'].values stds = monthly_stats['std'].values months =range(1, 13)# Plot mean points plt.errorbar(months, means, yerr=stds, fmt='ro', ecolor='red', capsize=5, capthick=2, markersize=8, markerfacecolor='red', markeredgecolor='darkred', linewidth=2, label='Mean ± 1 Std Dev')# Customize the plot plt.title('Boston Monthly Temperature Distribution\n(All Individual Values with Mean ± Standard Deviation)', fontsize=16, fontweight='bold', pad=20) plt.xlabel('Month', fontsize=12, fontweight='bold') plt.ylabel('Temperature (°C)', fontsize=12, fontweight='bold') plt.grid(True, alpha=0.3)# Set x-axis labels plt.xticks(range(1, 13), month_names)# Add legend plt.legend(loc='upper right', fontsize=10)# Add statistics text stats_text =f"Data Period: {df['DATE'].min().strftime('%Y')} - {df['DATE'].max().strftime('%Y')}\n" stats_text +=f"Total Records: {len(df):,}\n" stats_text +=f"Station: Boston Logan International Airport\n" stats_text +=f"Red dots: Monthly means\n" stats_text +=f"Red bars: ±1 standard deviation"# plt.figtext(0.02, 0.02, stats_text, fontsize=10, # bbox=dict(boxstyle="round,pad=0.3", facecolor="lightgray", alpha=0.8))# Adjust layout to prevent label cutoff# plt.tight_layout()# Save the plot# plt.savefig('boston_monthly_temperature_scatter.png', dpi=300, bbox_inches='tight')# print("Plot saved as 'boston_monthly_temperature_scatter.png'") plt.show()def main():""" Main function to run the complete analysis. """print("Boston Historical Temperature Analysis")print("="*40)# Download data df = download_boston_temperature_data()# Filter data to last 100 years if we have moreifnot df.empty: current_year = datetime.now().year df = df[df['YEAR'] >= (current_year -100)]print(f"Filtered to last 100 years: {df['YEAR'].min()} - {df['YEAR'].max()}")# Calculate statistics monthly_stats = calculate_monthly_statistics(df)# Create visualizations create_scatter_plot_with_error_bars(df, monthly_stats)main()
Boston Historical Temperature Analysis
========================================
Downloading Boston temperature data from NOAA...
Downloaded 32744 temperature records
Filtered to last 100 years: 1936 - 2025
Calculating monthly statistics...
Monthly Temperature Statistics (Celsius):
==================================================
Month Mean Std Count Min Max
--------------------------------------------------
Jan -1.0 5.6 588 -16.7 18.7
Feb 0.4 5.1 537 -17.8 14.1
Mar 3.8 4.7 587 -17.8 16.7
Apr 9.2 4.1 630 -2.2 22.9
May 14.7 4.2 651 4.9 28.7
Jun 20.1 4.1 626 8.5 31.7
Jul 23.5 3.2 651 15.0 32.3
Aug 22.8 3.5 611 -17.8 31.8
Sep 19.2 3.3 570 7.8 28.2
Oct 13.2 3.9 588 0.8 24.0
Nov 7.5 4.6 570 -6.0 20.9
Dec 2.6 4.9 589 -14.2 16.7
Creating scatter plot with error bars...
Let’s take the case of the Tesla and NVidia returns in 2023:
Code
import pandas as pdimport yfinance as yfstocks = ['TSLA', 'NVDA']df = pd.DataFrame()for s in stocks: df[s] = pd.DataFrame(yf.download(s, start='2023-01-01', end='2023-12-31', progress =False))['Close']rets = df.pct_change(30)rets[['TSLA', 'NVDA']].plot(lw=2)plt.legend(loc='best')plt.show()
YF.download() has changed argument auto_adjust default to True
1 Failed download:
['TSLA']: YFRateLimitError('Too Many Requests. Rate limited. Try after a while.')
1 Failed download:
['NVDA']: YFRateLimitError('Too Many Requests. Rate limited. Try after a while.')
Treating these two time-series as random variables, we are interested in how they vary together.
This is captured by the concept of covariance.
Definition. For two random variables \(X\) and \(Y\), their covariance is defined as:
If covariance is positive, this tells us that \(X\) and \(Y\) tend to both be above their means together and both below their means together.
We will often denote \(\text{Cov}(X,Y)\) as \(\sigma_{XY}\).
If we are interested in asking “how similar” are two random variables, we want to normalize covariance by the amount of variance shown by the random variables.
The tool for this purpose is correlation, i.e., normalized covariance:
where \(\tilde{d}_1\) and \(\tilde{d}_2\) are the columns of \(\tilde{D}\).
This shows that covariance is actually an inner product between normalized observation vectors.
Low and High Variability
Historically, most sources of random variation that have concerned statisticians are instances of low variability.
The original roots of probability in the study of games of chance, and later in the study of biology and medicine, have mainly studied objects with low variability.
Note that by “low variability” I don’t mean that such variability is unimportant.
Some examples of random variation in this category are:
the heights of adult humans,
the number of trees per unit area in a mature forest,
the sum of 10 rolls of a die,
the time between emission of subatomic particles from a radioactive material.
In each of these cases, there are a range of values that are “typical,” and there is a clear threshold above what is typical, that essentially never occurs.
On the other hand, there are some situations in which variability is quite different.
In these cases, there is no real “typical” range of values, and arbitrarily large values can occur with non-negligible frequency.
Some examples in this category are
the distribution of wealth among individuals in society,
the sizes of human settlements,
the areas burnt in forest fires,
the runs of gains and losses in various financial markets over time,
and the number of collaborators a scholar has over their lifetime.
Example
The banking system (betting against rare events) just lost [more than] 1 Trillion dollars (so far) on a single error, more than was ever earned in the history of banking.
Nassim Nicholas Taleb, September 2008
An example of a run of observations showing high variability. This figure shows the daily variations in a derivatives portfolio over the time-frame 1988-2008. About 99% of the variation over the 20 years occurs in a single day (the day the European Monetary System collapsed).
Important Distributions
Important Distributions
Now we will review certain distributions that come up over and over again in typical situations.
The Bernoulli Distribution
An experiment of a particularly simple type is one in which there are only two possible outcomes, such as
head or tail
success or failure
defective or non-defective component
patient recovers or does not recover
Each distribution has one or more parameters. Parameters are settings that control the distribution. A Bernoulli distribution has one parameter, \(p\), which is the probability that the random variable is equal to 1.
Definition. It is said that a random variable \(X\) has a Bernoulli distribution with parameter \(p\)\((0\leq p \leq 1)\) if \(X\) can take only the values 0 and 1 and the corresponding probabilities are
\[P(X=1) = p \: \text{ and } \: P(X=0) = 1-p.\]
Note that there is a particularly concise way of writing the above definition:
\[ p(x) = P(X=x) = p^x (1-p)^{(1-x)} \: \text{ for } \: x = 0 \text{ and } x=1.\]
The mean of a \(X\) is \(p\) and the variance of \(X\) is \(p(1-p)\).
Can you derive this yourself?
The Binomial Distribution
The binomial distribution considers precisely \(N\) Bernoulli trials. Each trial has the probability of a success equal to \(p\). \(N\) and \(p\) are the parameters of the binomial distribution.
The binomial distribution answers the question “What is the probability there will be \(k\) successes in \(N\) trials?”
Definition. If \(X\) represents the number of successes that occur in \(N\) trials, then \(X\) is said to have a binomial distribution with parameters \(N\) and \(p\)\((0\leq p \leq 1)\). The PMF of a binomial random variable is given by
The validity of the above PMF can be verified as follows. First we notice, that, by the assumed independence of trials, for any given sequence of \(k\) successes and \(N-k\) failures, the probability is \(p^k \;(1-p)^{N-k}\). Then there are \(\binom{N}{k}\) different sequences of the \(N\) outcomes leading to \(k\) successes and \(N-k\) failures.
The mean of the Binomial distribution is \(pN\), and its variance is \(p(1-p)N\).
The PMF of the Binomial distribution with \(N = 10\) and \(p=0.3\) is shown below.
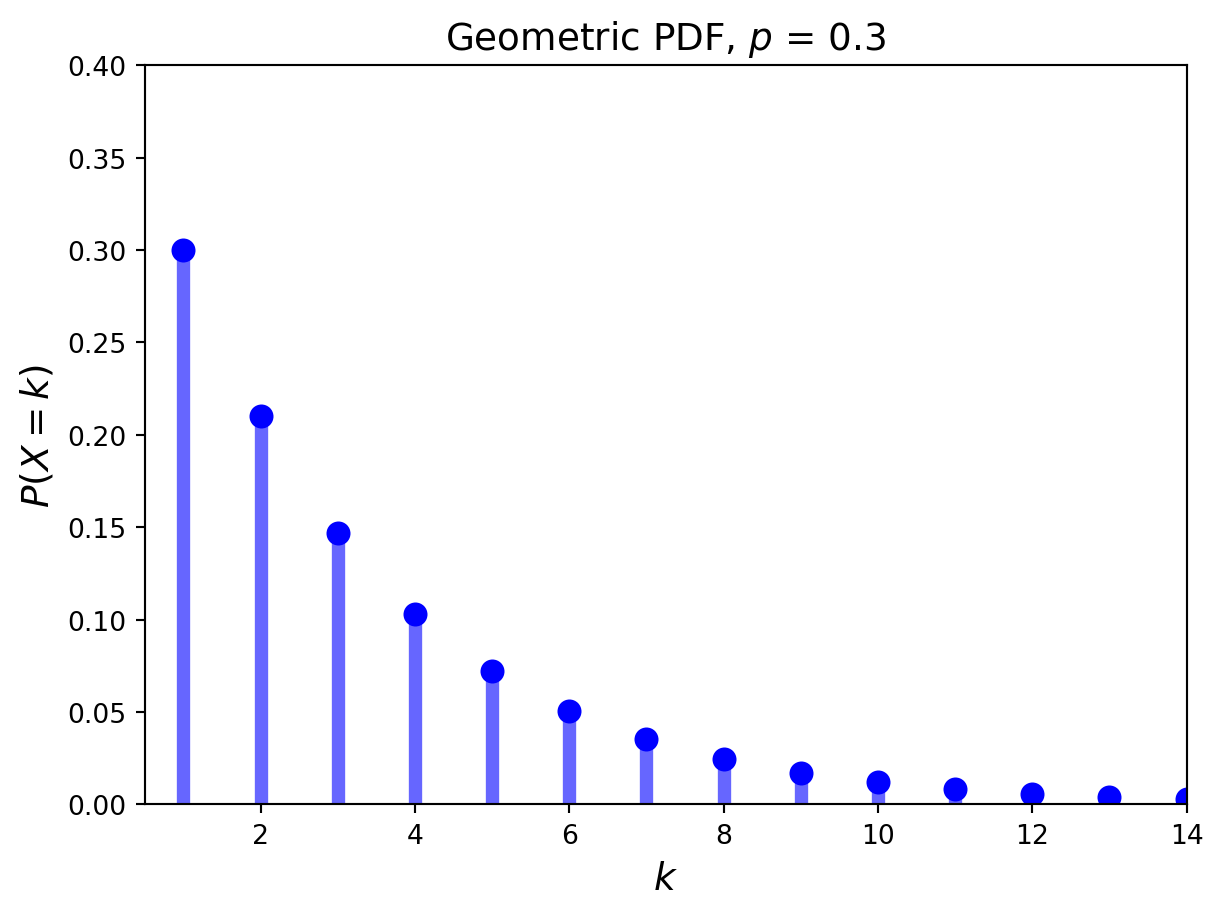
The geometric distribution concerns Bernoulli trials as well. It has only one parameter \(p\), the probability of success.
The geometric distribution answers the question: “What is the probability it takes \(k\) trials to obtain the first success?”
Definition. It is said that a random variable \(X\) has a geometric distribution with parameter \(p\)\((0\leq p \leq 1)\) if \(X\) has a discrete distribution with
Although the Bernoulli trials underlie all of the previous distributions in these notes, they do not form the basis for the Poisson distribution. To introduce the Poisson distribution we will look at some examples of random variables that generally obey the Poisson probability law:
The number of misprints on a page (or a group of pages) of a book;
The number of people in a community who survive to age 100;
The number of wrong telephone numbers that are dialed in a day;
The number of customers entering a post office on a given day;
The number of \(\alpha\)-particles discharged in a fixed period of time from some radioactive material.
In the above examples the events appear to happen at a certain rate, but completely at random (i.e., without a certain structure).
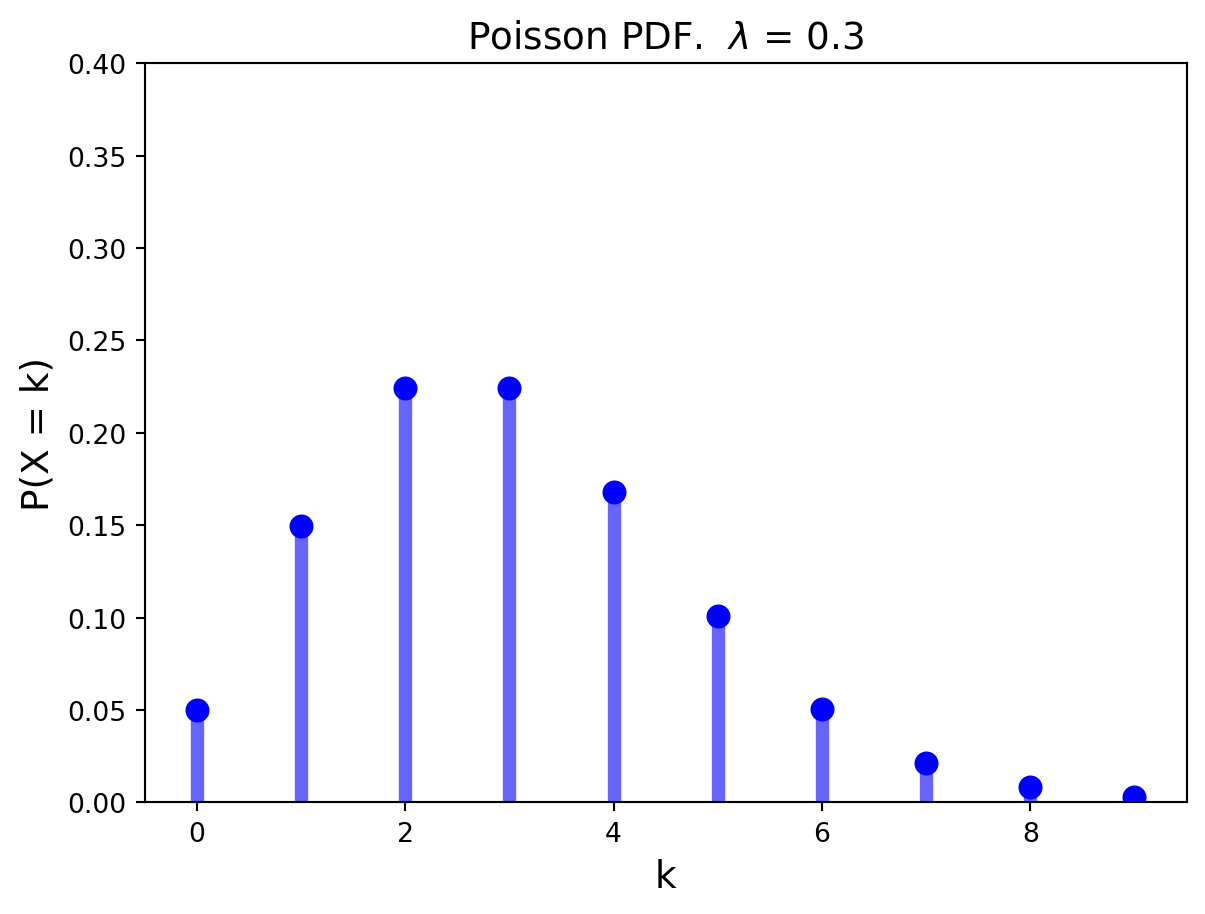
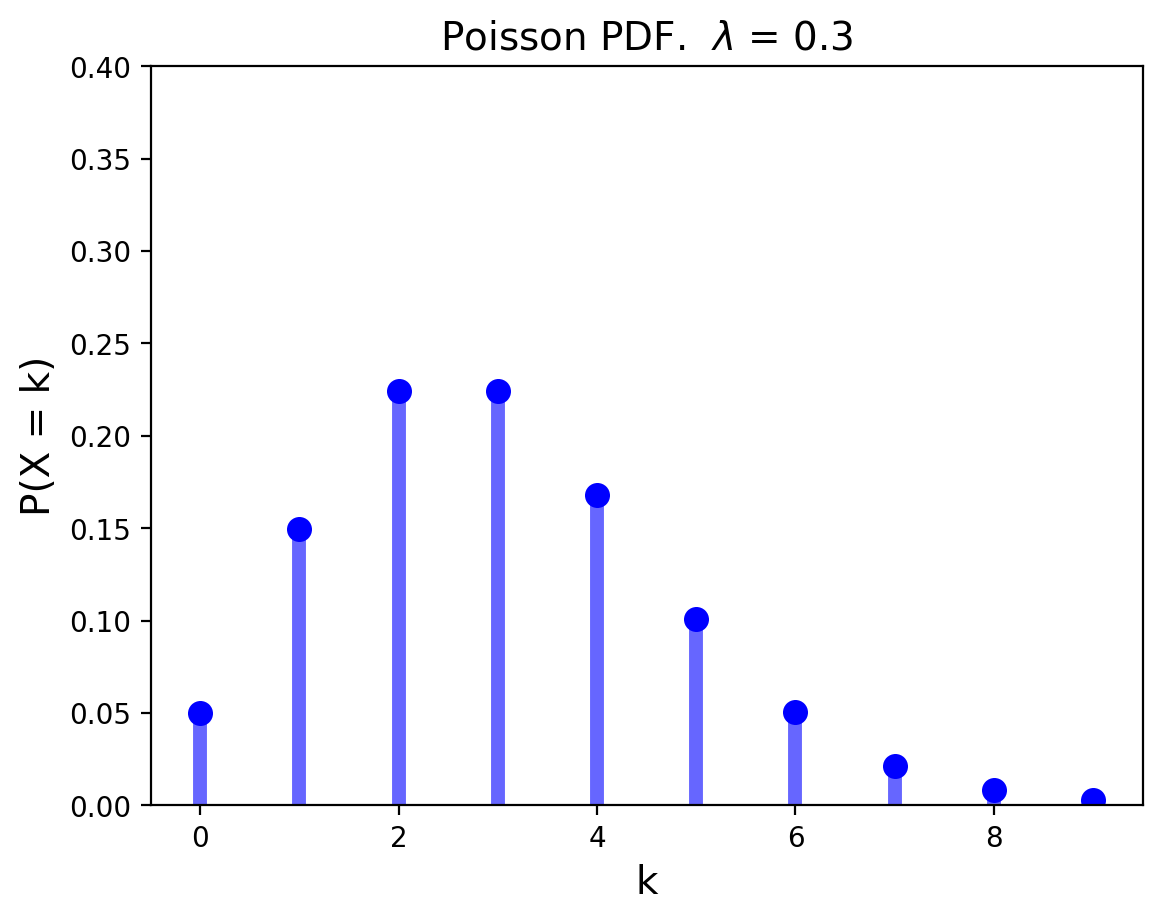
A Poisson distribution answers the question: “How many successes occur in a fixed amount of time?”
Definition. A random variable \(X\) that takes on one of the values \(0, 1, 2,...\) is said to have a Poisson distribution with parameter \(\lambda\) if, for some \(\lambda > 0\),
\[
p(k) = P(X=k) = \lambda^k \frac{e^{- \lambda}}{k!} \: \text{ for } k = 0, 1, 2,...
\]
Here, we used the fact that the exponential function \(e^{\lambda}\), can be expressed as series, \(\sum_{k=0}^{\infty} \frac{\lambda^k}{k!}\) for every real number \(\lambda\).
Both the mean and the variance of a Poisson distribution with parameter \(\lambda\) are equal to \(\lambda.\)
The PMF of the Poisson distribution with parameter \(\lambda = 0.3\) is shown below.
The Poisson random variable has a tremendous range of applications in diverse areas. The reason for that is the fact that a Poisson distribution with mean \(Np\) may be used as an approximation for a binomial distribution with parameters \(N\) and \(p\) when \(N\) is large and \(p\) is small enough so that \(Np\) is of moderate size.
The Poisson distribution has an interesting role in our perception of randomness (which you can read more about here).
More generally that rare events in large populations can be statistically modeled using the Poisson distribution
In 1898 Ladislaus Bortkiewicz, a Russian statistician of Polish descent, was trying to understand why, in some years, an unusually large number of soldiers in the Prussian army were dying due to horse-kicks. In a single army corp, there were sometimes 4 such deaths in a single year. Was this just coincidence?
To assess whether horse-kicks were random (not following any pattern) Bortkiewicz simply compared the number per year to what would be predicted by the Poisson distribution.
Code
# note that this data is available in 'data/HorseKicks.txt'horse_kicks = pd.DataFrame(data = np.array([[0, 108.67, 109],[1, 66.29, 65],[2, 20.22, 22],[3, 4.11, 3],[4, 0.63, 1],[5, 0.08, 0],[6, 0.01, 0]]),columns = ["Number of Deaths Per Year","Predicted Instances (Poisson)","Observed Instances"])horse_kicks.set_index("Number of Deaths Per Year", inplace=True)horse_kicks
Predicted Instances (Poisson)
Observed Instances
Number of Deaths Per Year
0.0
108.67
109.0
1.0
66.29
65.0
2.0
20.22
22.0
3.0
4.11
3.0
4.0
0.63
1.0
5.0
0.08
0.0
6.0
0.01
0.0
Code
horse_kicks[["Predicted Instances (Poisson)","Observed Instances"]].plot.bar()plt.xlabel("Number of Deaths Per Year", size=14)plt.ylabel("Count", size=14)plt.show()
The message here is that when events occur at random, we actually tend to perceive them as clustered.
Here is another example:
Which of these was generated by a random process occurring equally likely everywhere?
These images are from Steven Pinker’s book, The Better Angels of our Nature.
In the left figure, the number of dots falling into regions of a given size follows the Poisson distribution.
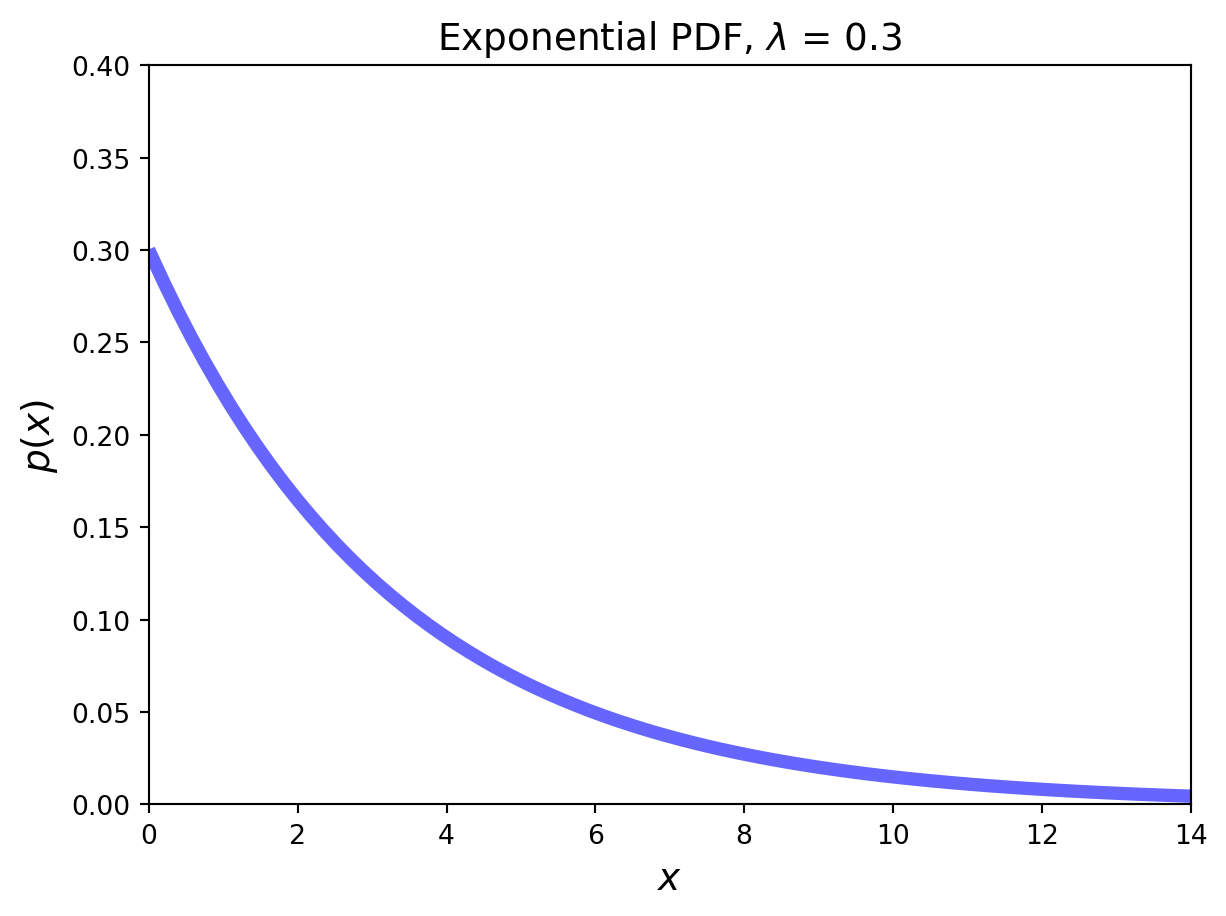
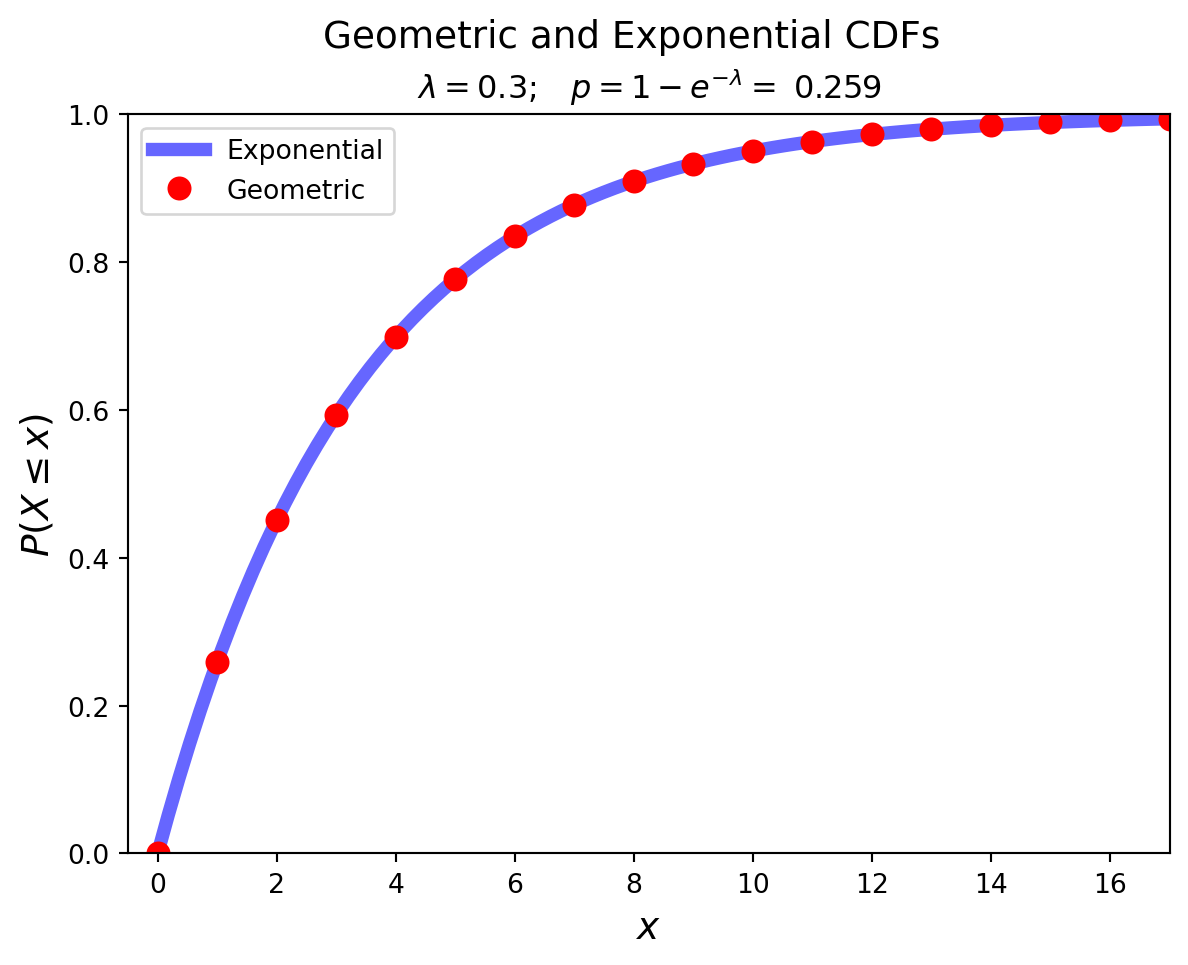
The Exponential Distribution
The exponential distribution is an example of a continuous distribution. It concerns a Poisson process and has one parameter, \(\lambda\), the rate of success.
Definition. A continuous random variable whose PDF is given, for some \(\lambda > 0\), by
There is an important relationship between the uniform and Poisson distributions.
When the time an event occurs is uniformly distributed, the number of events in a time interval is Poisson distributed.
You can replace “time” with “location”, and so on.
Also, the reverse statment is true as well.
So a simple way to generate a picture like the scattered points above is to select the \(x\) and \(y\) coordinates of each point uniformly distributed over the picture size.
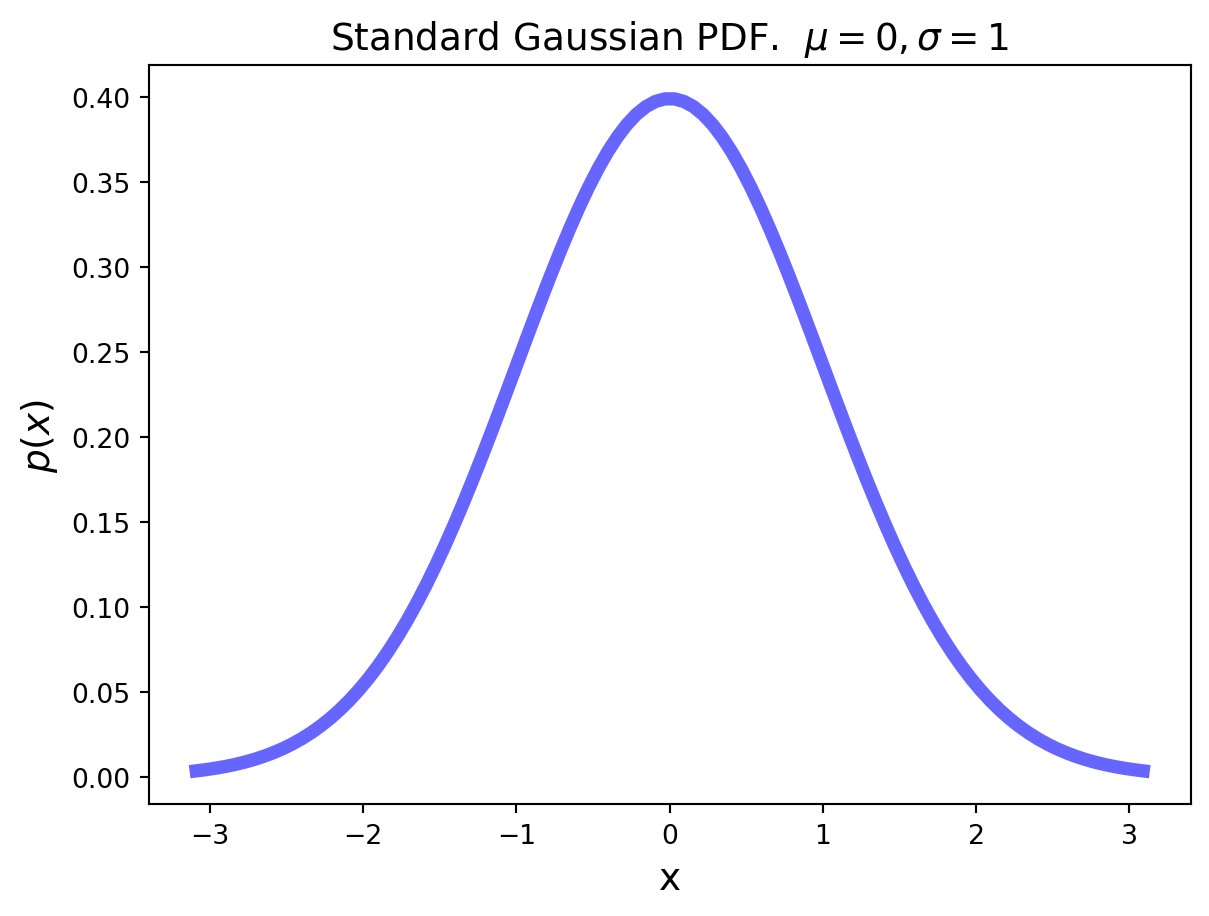
The Gaussian Distribution
The Gaussian Distribution is also called the Normal Distribution.
We will make extensive use of Gaussian distribution, for a number of reasons.
One of reasons we will use it so much is that it is a good guess for how errors are distributed in data.
This comes from the celebrated Central Limit Theorem. Informally,
The sum of a large number of independent observations from any distribution with finite variance tends to have a Gaussian distribution.
”
As a special case, the sum of \(n\) independent Gaussian variates is Gaussian.
Thus Gaussian processes remain Gaussian after passing through linear systems.
If \(X_1\) and \(X_2\) are Gaussian, then \(X_3 = aX_1 + bX_2\) is Gaussian.
One way of thinking of the Gaussian is that it is the limit of the Binomial when \(N\) is large, that is, the limit of the sum of many Bernoulli trials.
However, because of the central limit theorem, many other sums of random variables (not just Bernoulli trials) converge to the Gaussian.
The standard Gaussian distribution has mean zero and a variance (and standard deviation) of 1. The pdf of the standard Gaussian is:
\[p(x) = \frac{1}{\sqrt{2 \pi}} e^{-x^2/2}.\]
For an arbitrary Gaussian distribution with mean \(\mu\) and variance \(\sigma^2\), the pdf is simply the standard Gaussian that is relocated to have its center at \(\mu\) and its width scaled by \(\sigma\)
All of the distributions we have discussed so far have “light tails”, meaning that they show low variability.
In other words, extremely large observations are essentially impossible.
However in other cases, extremely large observations can occur. Distributions that capture this property are called “heavy tailed”.
Some examples of data that can be often modeled using heavy-tailed distributions:
The sizes of files in a file system.
The sizes of objects transferred over the Internet.
The execution time of jobs on a computer system.
The degree of nodes in a network (e.g., social network).
In practice, random variables that follow heavy tailed distributions are characterized as exhibiting many small observations mixed in with a few large observations.
In such datasets, most of the observations are small, but most of the contribution to the sample mean or variance comes from the rare, large observations.
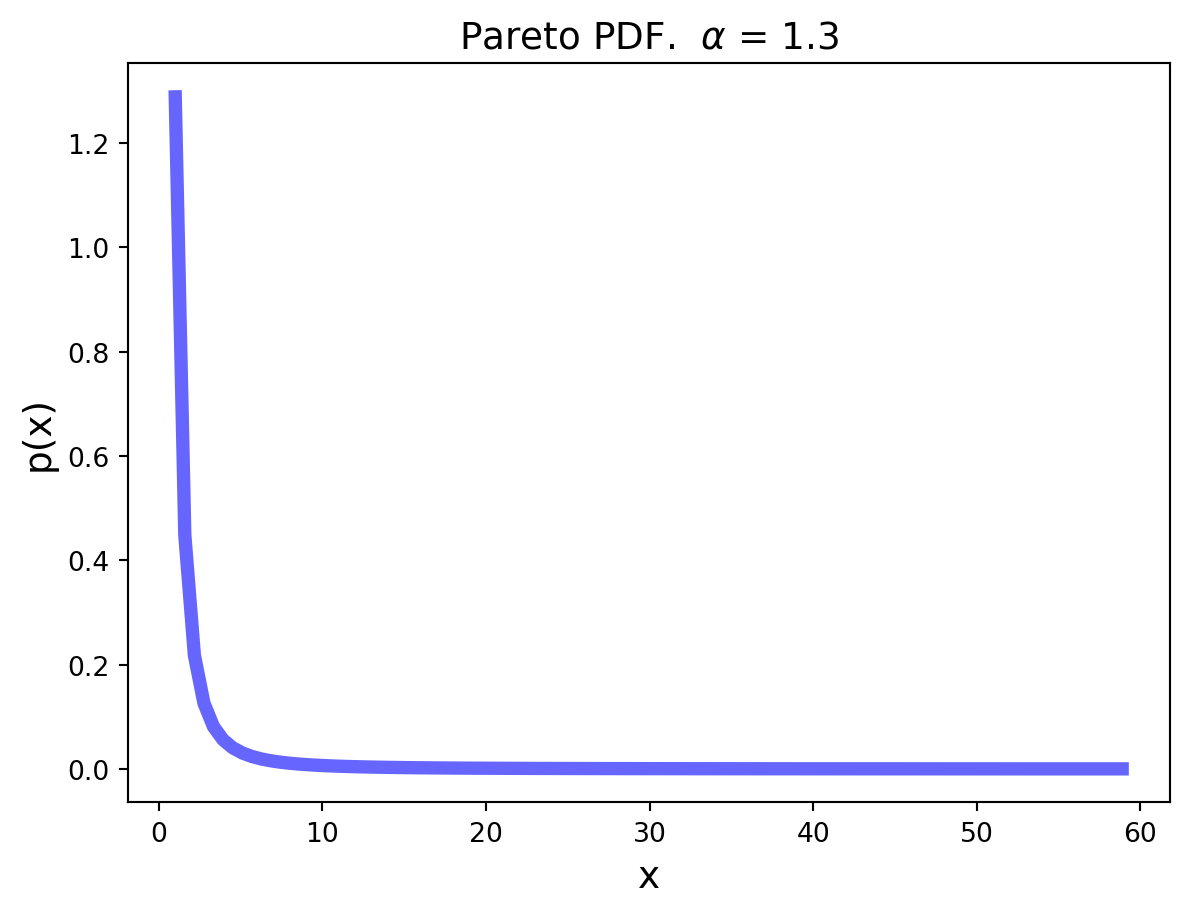
The Pareto Distribution
The Pareto distribution is the simplest continuous heavy-tailed distribution.
Pareto was an Italian economist who studied income distributions. (In fact, income distributions typically show heavy tails.)
The variance of the Pareto distribution is infinite. (The corresponding integral diverges.)
In practice, this means that a new observation that significantly changes the sample variance is always possible, no matter how many samples of the random variable have already been taken.
The mean of the Pareto is \(\frac{k\alpha}{\alpha-1}\), for \(\alpha > 1\).
But note that as \(\alpha\) decreases, the variability of the Pareto increases.
In fact, for \(\alpha \leq 1\), the Pareto distribution has infinite mean. Again, in practice this means that a swamping observation for the mean is always possible.
Hence the running average of a series of Pareto observations with \(\alpha \leq 1\) will never converge to a fixed value, and the mean itself is not a useful statistic in this case.
The Multivariate Gaussian
The most common multivariate distribution we will work with is the multivariate Gaussian.
The multivariate normal distribution of a random vector \(\mathbf{X} = (X_1, \dots, X_k)^T\) is denoted
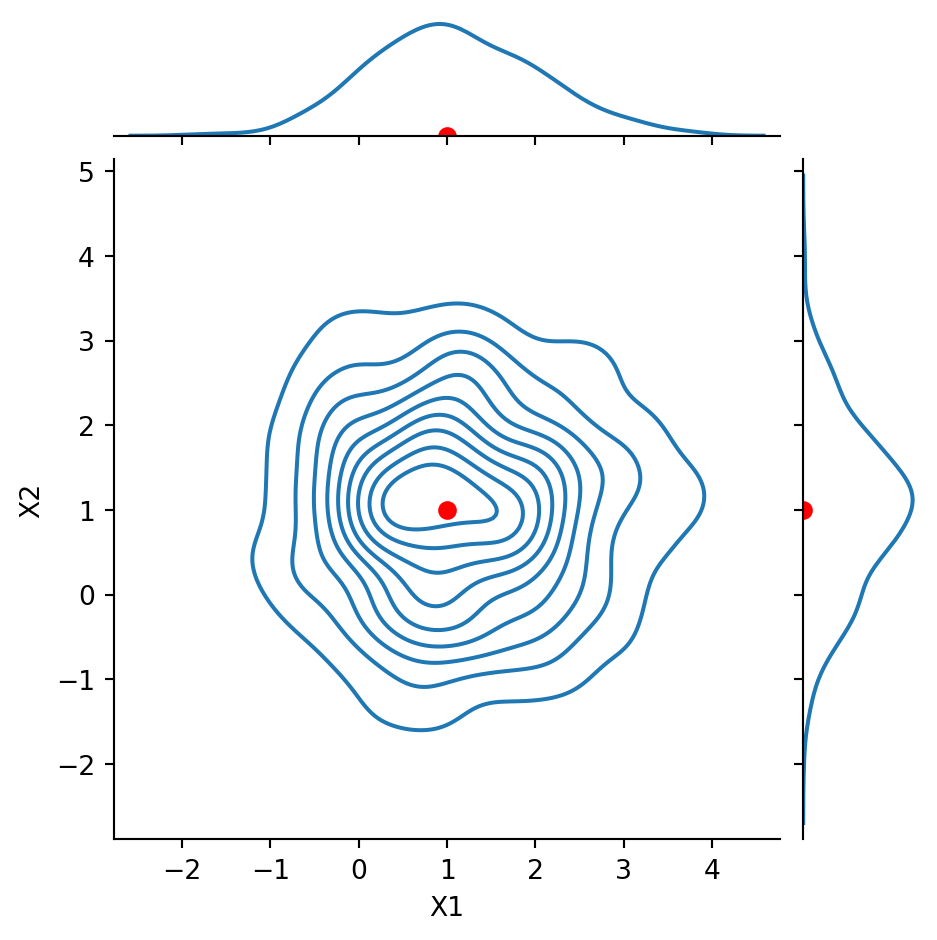
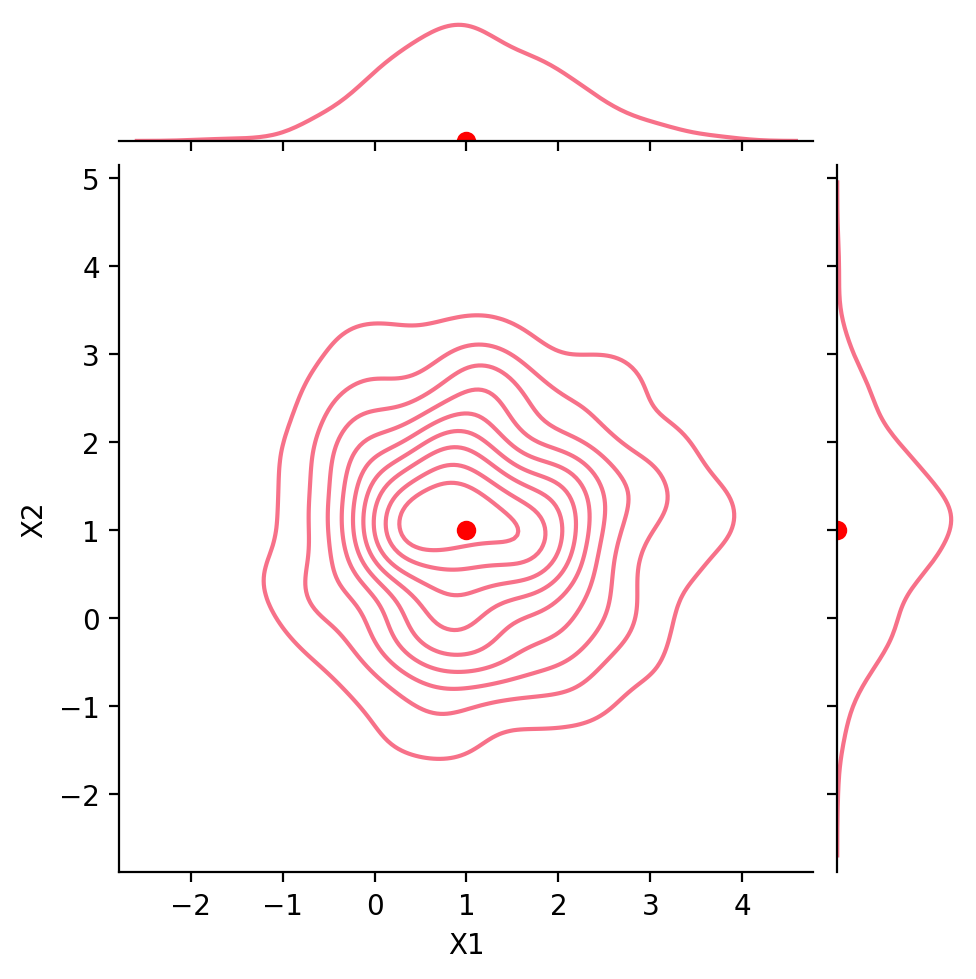
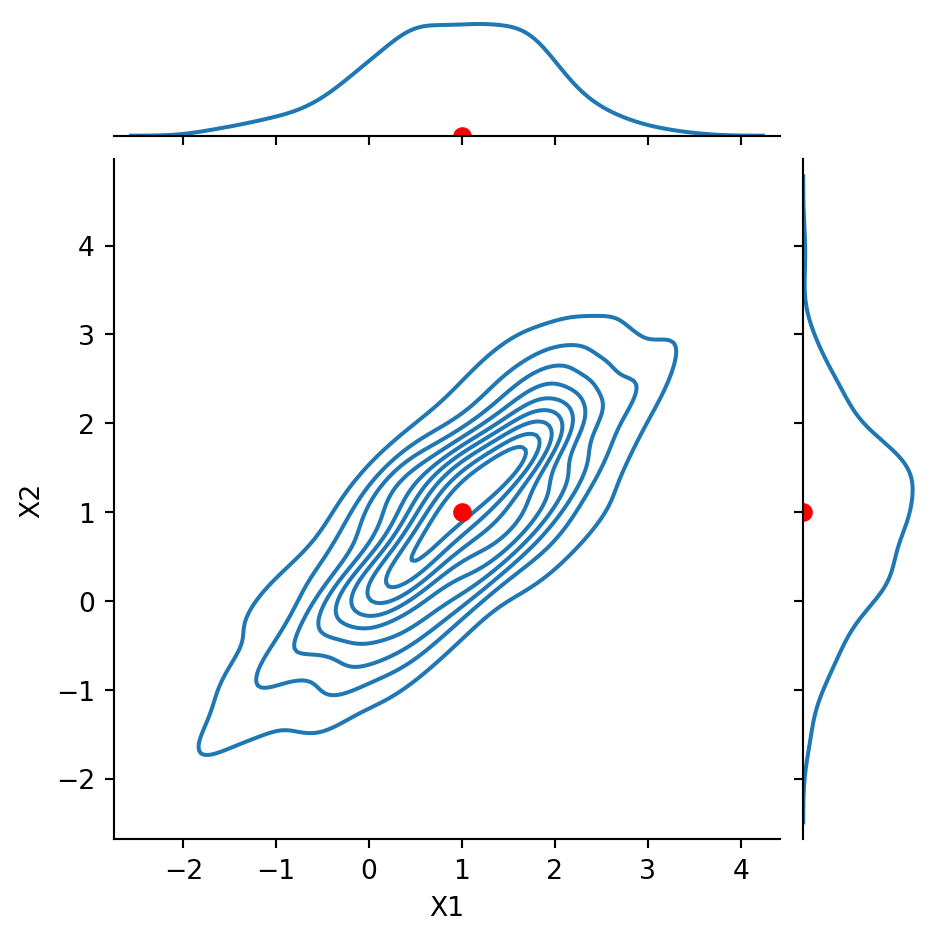
Notice that \(\text{Cov}(X_1, X_2) = -0.8\). We say that the components are negatively correlated or anticorrelated.
Code
g = sns.JointGrid(data = df1, x ='X1', y ='X2', height =5)g.plot(sns.scatterplot, sns.kdeplot)g.ax_joint.plot(1, 1, 'ro', markersize =6)g.ax_marg_x.plot(1, 0, 'ro')g.ax_marg_y.plot(0, 1, 'ro')plt.show()
Code
g = sns.JointGrid(data = df1, x ='X1', y ='X2', height =5)g.plot(sns.kdeplot, sns.kdeplot)g.ax_joint.plot(1, 1, 'ro', markersize =6)g.ax_marg_x.plot(1, 0, 'ro')g.ax_marg_y.plot(0, 1, 'ro')plt.show()
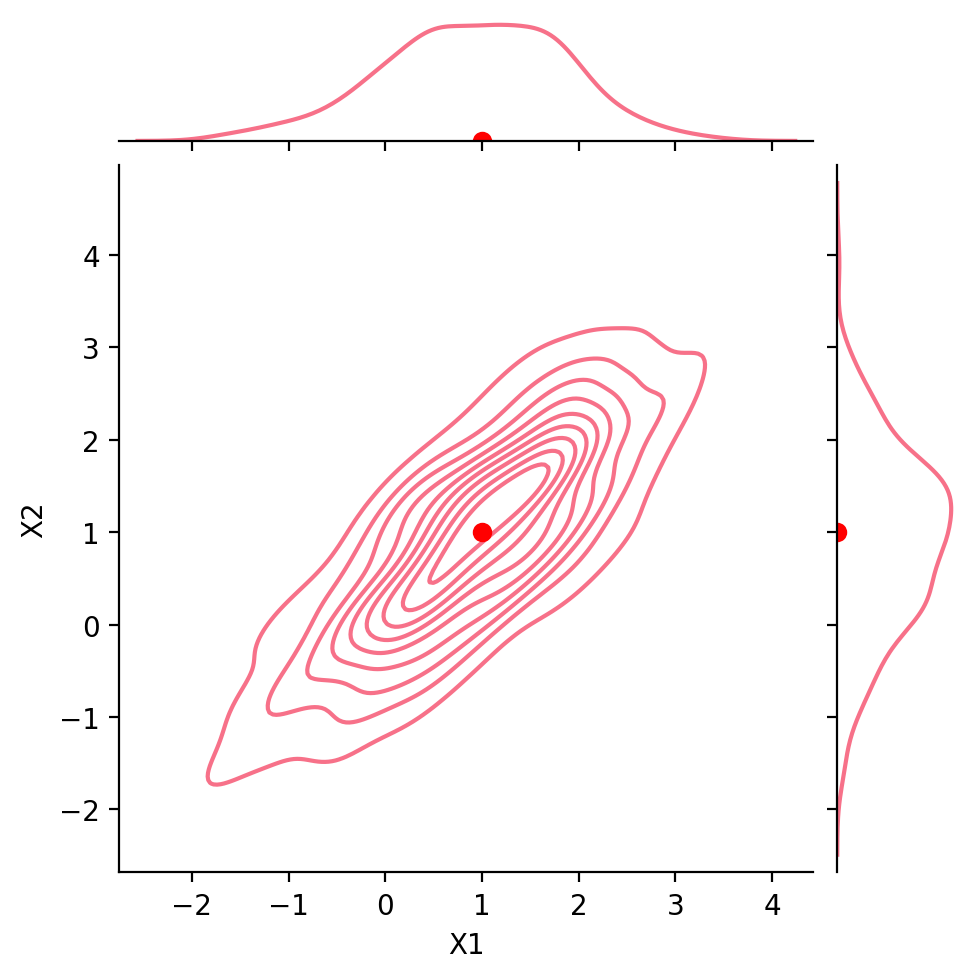
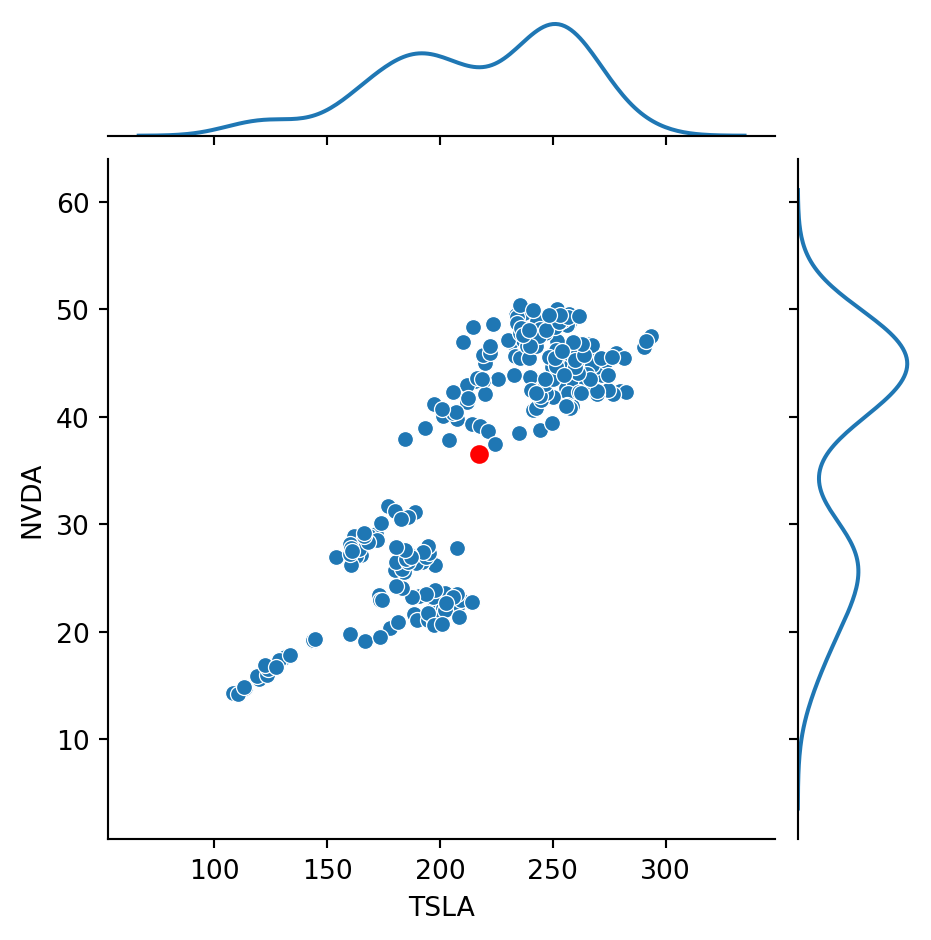
Finally, let’s look at our stock data:
Code
g = sns.JointGrid(data = df, x ='TSLA', y ='NVDA', height =5)g.plot(sns.scatterplot, sns.kdeplot)g.ax_joint.plot(df.mean()['TSLA'], df.mean()['NVDA'], 'ro', markersize =6)plt.show()
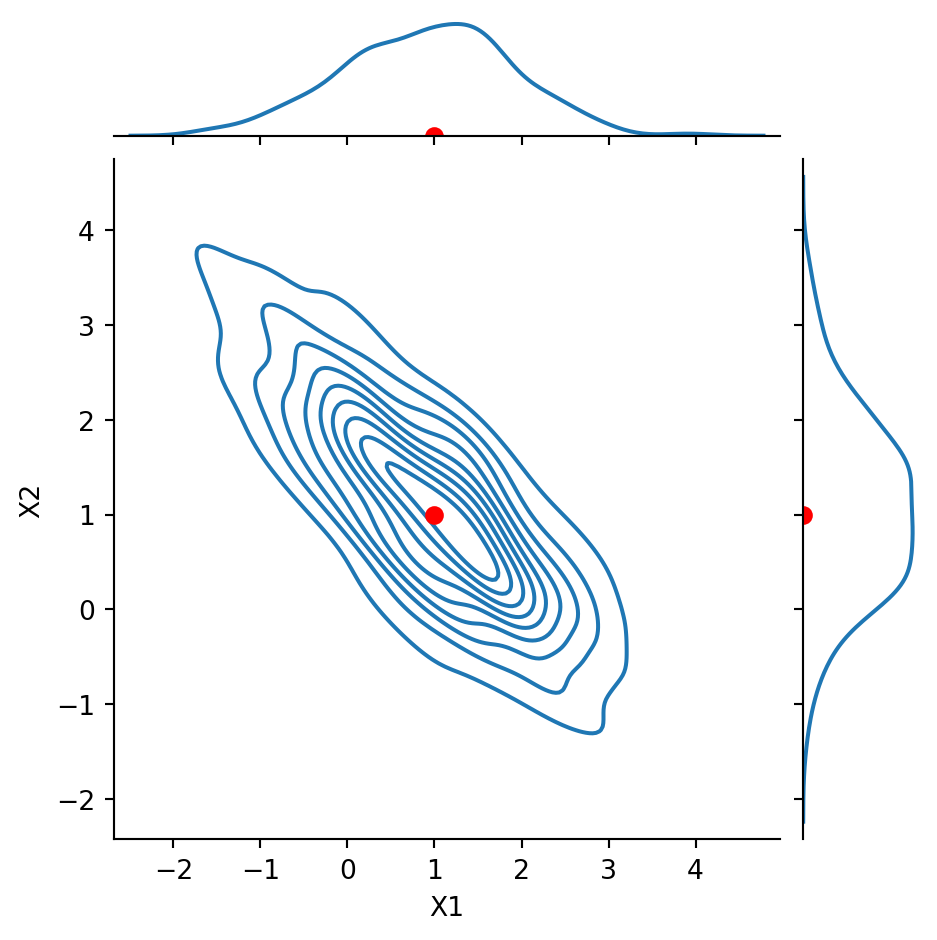
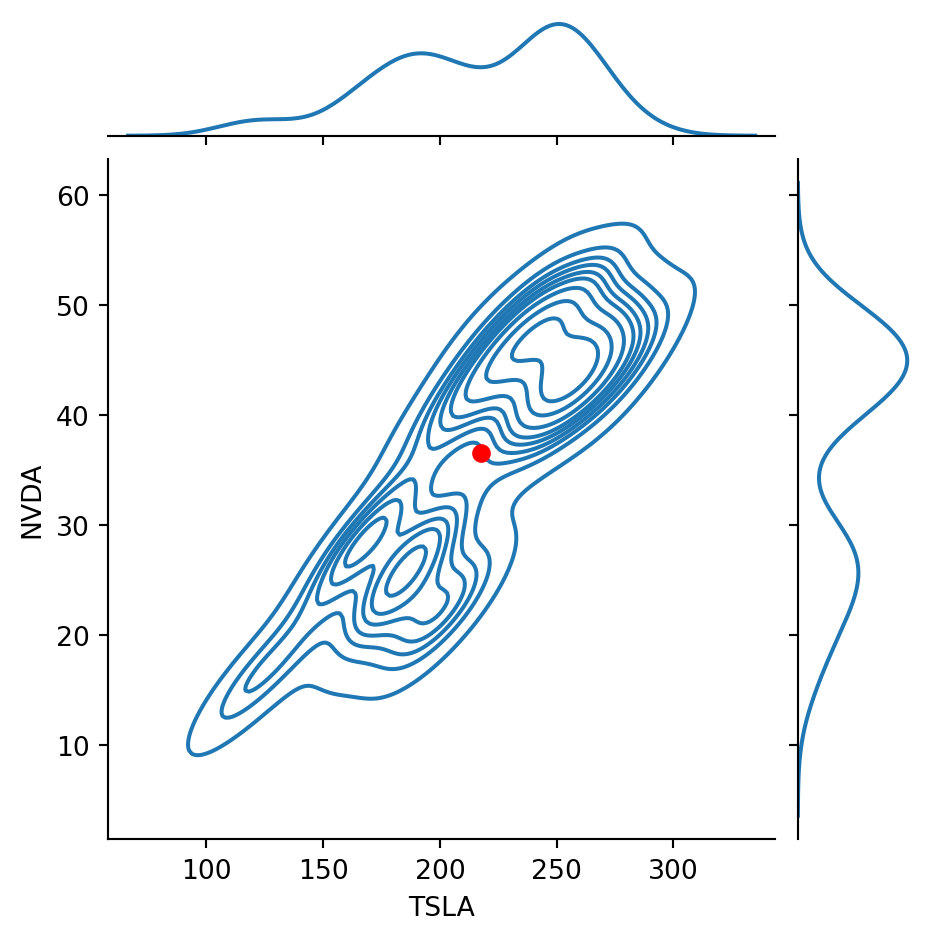
Code
g = sns.JointGrid(data = df, x ='TSLA', y ='NVDA', height =5)g.plot(sns.kdeplot, sns.kdeplot)g.ax_joint.plot(df.mean()['TSLA'], df.mean()['NVDA'], 'ro', markersize =6)plt.show()
Recall that the correlation between these two stocks was about 0.86.
That is, the stocks are positively correlated.
Confidence Intervals
Say you are concerned with some data that we take as coming from a random process.
You want to characterize it as accurately as possible. You measure it, yielding a single value.
How much does that value tell you? Can you rely on it as a description of the random process?
Let’s say you have a dataset and you compute its average value.
How certain are you that the average would be the same if you took another dataset from the same source (i.e., the same random process)?
We think of the hypothetical data source as a random variable with a true mean \(\mu\).
(Note that we are using frequentist style thinking here.)
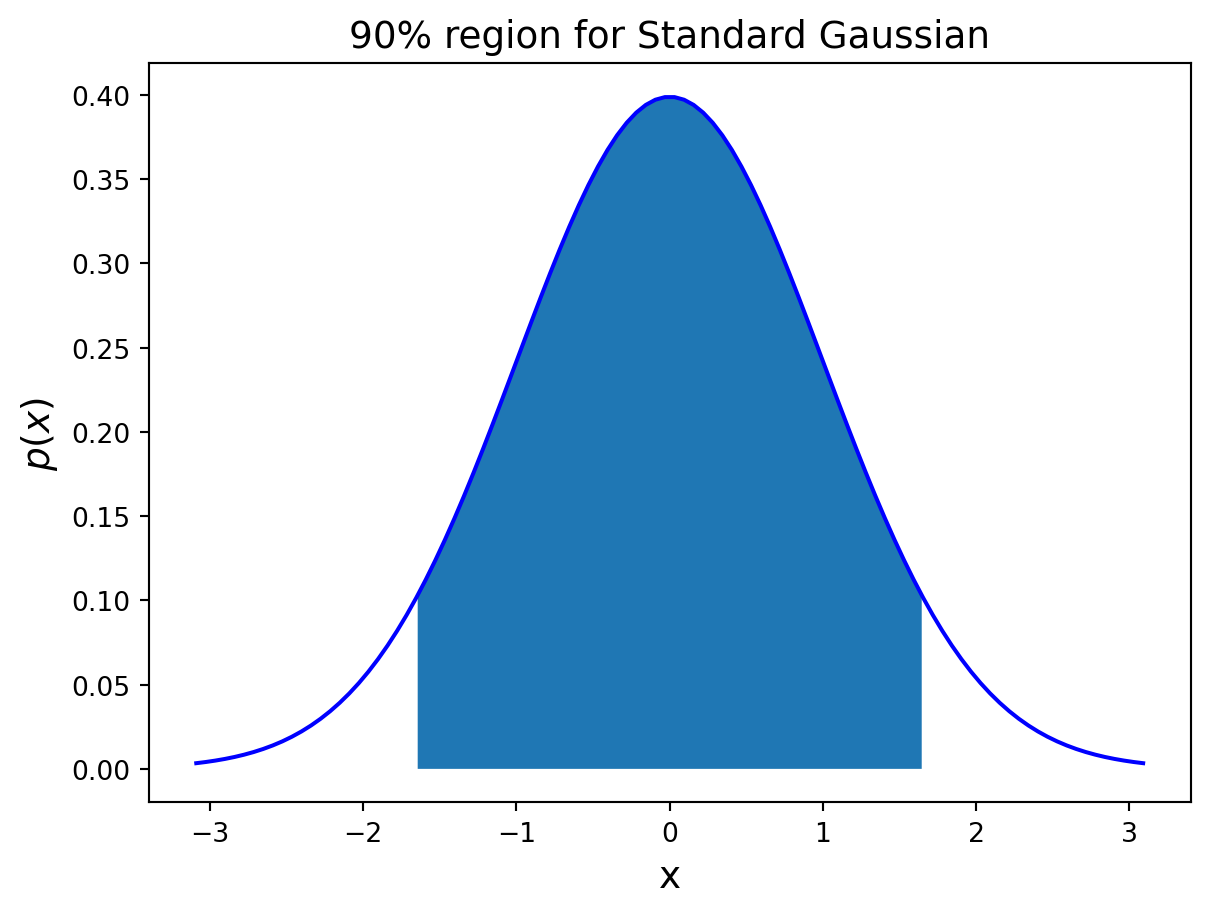
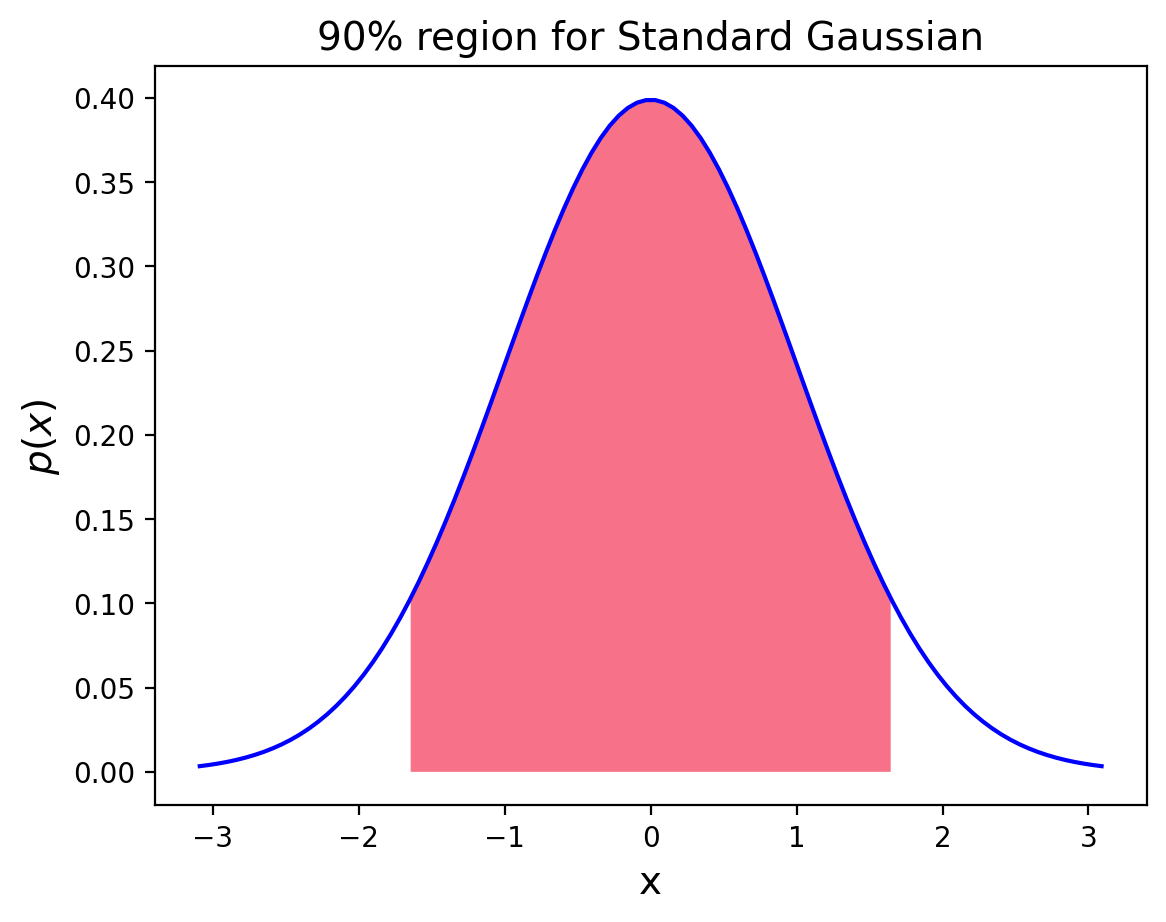
We would like to find a range within which we are 90% sure that the true mean \(\mu\) lies.
In other words, we want the probability that the true mean lies in the interval to be 0.9.
This interval is then called the 90% confidence interval.
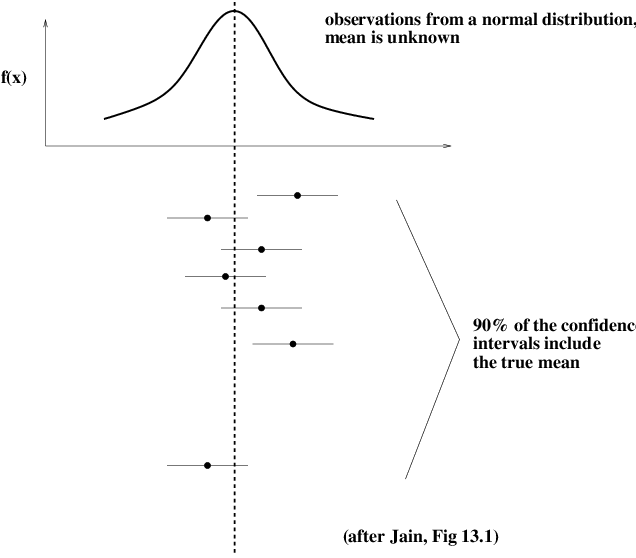
To be more precise: A confidence interval at level \(\gamma\) for a fixed but unknown parameter \(m\) is an interval \((a,b)\) such that
\[P(A < m < B) \geq \gamma.\]
Note that \(m\) is fixed — it is not random.
What is random is the interval \((A, B)\).
This interval is constructed based on the data, which (by assumption) are random.
Confidence Intervals for the Mean
Imagine we have a set of \(n\) samples of a random variable, \(x_1, x_2, ..., x_n\) Let’s assume that the random variable has mean \(\mu\) and variance \(\sigma^2\).
An estimate of \(\mu\) is the empirical average of the samples, \(\bar{x}\).
Now, the Central Limit Theorem tells us that the sum of a large number \(n\) of random variables, each with mean \(\mu\) and variance \(\sigma^2\), yields a Gaussian random variable with mean \(n\mu\) and variance \(n \sigma^2\).
So the distribution of the average of \(n\) samples is normal with mean \(\mu\) and variance \(\sigma^2 / n\). That is,
We usually assume that the number of samples should be 30 or more for the CLT to hold.
While the specific value 30 is a bit arbitrary, we will usually be using very large samples (datasets) in this course for which this assumption is valid.
The standard deviation of the sample mean is called the standard error.
Notice that the standard error decreases as we increase the sample size, according to \(1/\sqrt{n}.\)
So it will turn out that using \(\bar{x}\), we can get increasingly “tight” estimates of \(\mu\) as we increase the number of samples \(n\).
Now, remember that the true mean \(\mu\) is a constant, while the empirical mean \(\bar{x}\) is a random variable.
Let us assume for a moment that we know the true \(\mu\) and \(\sigma\), and that we accept that \(\bar{x}\) has a \(N(\mu, \sigma/\sqrt{n})\) distribution.
The last step: by a simple argument, we can show that the sample mean is in some fixed-size interval centered on the true mean, if and only if the true mean is also in a fixed-size interval (of the same size) centered on the sample mean.
This latter expression defines the \(1-\alpha\) confidence interval for the mean.
We are done, except for estimating \(\sigma\). We do this directly from the data: \(\hat{\sigma} = s\), where \(s\) is the sample standard deviation, that is,
\(s = \sqrt{1/(n-1) \sum (x_i - \bar{x})^2}\).
To summarize: by the argument presented here, a 100(1-\(\alpha\))% confidence interval for the population mean is given by
By no conegut - MacTutor History of Mathematics: http://www-history.mcs.st-andrews.ac.uk/PictDisplay/Bortkiewicz.html, Public Domain, https://commons.wikimedia.org/w/index.php?curid=79219622↩︎





 ”
”