where \(\sigma_1, \sigma_2, \dots, \sigma_k\) are the singular values of \(A\).
\(\mathbf{u}_{k+1}, \ldots, \mathbf{u}_n\) are any orthonormal vectors that complete the orthonormal basis for \(\mathbb{R}^m\) and
\(\mathbf{v}_{k+1}, \ldots, \mathbf{v}_n\) are any orthonormal vectors that complete the orthonormal basis for \(\mathbb{R}^n\) and are in the null space of \(A\).
Singular Value Decomposition
We can collect the vectors \(\mathbf{v}_i\) into a matrix \(V\) and the vectors \(\mathbf{u}_i\) into a matrix \(U\). \[
A
\begin{bmatrix}
\vert & \vert & & \vert \\
\mathbf{v}_1 & \mathbf{v}_2 & \dots & \mathbf{v}_n \\
\vert & \vert & & \vert
\end{bmatrix} =
\begin{bmatrix}
\vert & \vert & & \vert \\
\mathbf{u}_1 & \mathbf{u}_2 & \dots & \mathbf{u}_m \\
\vert & \vert & & \vert
\end{bmatrix}
\left[
\begin{array}{c|c}
\begin{matrix}
\sigma_1 & \cdots & 0 \\
\vdots & \ddots & \vdots \\
0 & \cdots & \sigma_k
\end{matrix}
&
\mathbf{0}
\\
\hline
\mathbf{0} & \mathbf{0}
\end{array}
\right]
.
\]
We call the \(\mathbf{v}_i\) the right singular vectors and the \(\mathbf{u}_i\) the left singular vectors.
Singular Value Decomposition
And because \(V\) is an orthogonal matrix, we have \(V V^T = I\), so we can right multiply both sides by \(V^T\) to get
The SVD of a matrix \(A\in\mathbb{R}^{m\times n}\) (where \(m>n\)) is
\[
A = U\Sigma V^{T},
\]
where
\(U\) has dimension \(m\times n\). The columns of \(U\) are orthogonal. The columns of \(U\) are the left singular vectors.
\(\Sigma\) has dimension \(n\times n\). The only non-zero values are on the main diagonal and they are nonnegative real numbers \(\sigma_1\geq \sigma_2 \geq \ldots \geq \sigma_k\) and \(\sigma_{k+1} = \ldots = \sigma_n = 0\). These are called the singular values of \(A\).
\(V\) has dimension \(n \times n\). The columns of \(V\) are orthogonal. The columns of \(V\) are the right singular vectors.
The SVD decomposes \(A\) into a linear combination of rank-1 matrices.
The singular value tells us the weight (contribution) of each rank-1 matrix to the matrix \(A\).
Lecture Organization
In this lecture we first discuss:
Theoretical properties of the SVD related to
matrix rank
determining the best low rank approximations to a matrix
We will then apply these results when we consider data matrices from the following applications
internet traffic data
social media data
image data
movie data
SVD Properties
Matrix Rank
Let’s review some definitions.
Let \(A\in\mathbb{R}^{m\times n}\) be a real matrix such that with \(m>n\).
The rank of \(A\) is the number of linearly independent rows or columns of the matrix.
The largest value that a matrix rank can take is \(\min(m,n)\). Since we assumed \(m>n\), the largest value of the rank is \(n\).
If the matrix \(A\) has rank equal to \(n\), then we say it is full rank.
However, it can happen that the rank of a matrix is less than \(\min(m,n)\). In this case we say that \(A\) is rank-deficient.
Matrix Rank and Column Space
The dimension of the column space of \(A\) is the smallest number of vectors that suffice to construct the columns of \(A\).
And it is equal to the rank of the matrix.
If the dimension of the column spaces is \(k\), then there exists a set of vectors \(\{\mathbf{c}_1, \mathbf{c}_2, \dots, \mathbf{c}_k\}\) such that every column \(\mathbf{a}_i\) of \(A\) can be expressed as:
This means that the distance (in Frobenius norm) of the best rank-\(k\) approximation \(A^{(k)}\) from \(A\) is equal to \(\sqrt{\sum_{i=k+1}^n\sigma^2_i}\).
Low Rank Approximations in Practice
Models are simplifications
One way of thinking about modeling or clustering is that we are building a simplification of the data.
That is, a model is a description of the data, that is simpler than the data.
In particular, instead of thinking of the data as thousands or millions of individual data points, we might think of it in terms of a small number of clusters, or a parametric distribution, etc.
From this simpler description, we hope to gain insight.
There is an interesting question here: why does this process often lead to insight?
That is, why does it happen so often that a large dataset can be described in terms of a much simpler model?
Among competing hypotheses, the one with the fewest assumptions should be selected.
This has come to be known as “Occam’s razor.”
Occam’s Razor
William was saying that it is more common for a set of observations to be determined by a simple process than a complex process.
In other words, the world is full of simple (but often hidden) patterns.
From which one can justify the observation that modeling works surprisingly often.
Low Effective Rank of Data Matrices
In general, a data matrix \(A\in\mathbb{R}^{m\times n}\) is usually full rank, meaning that \(\operatorname{Rank}(A)\equiv p = \min(m, n)\).
However, it is possible to encounter data matrices that have low effective rank.
This means that we can approximate \(A\) by some \(A^{(k)}\) for which \(k \ll p\).
For any data matrix, we can judge when this is the case by looking at its singular values, because the singular values tell us the distance to the nearest rank-\(k\) matrix.
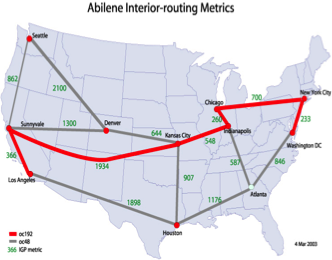
Traffic Data
Let’s see how this theory can be used in practice and investigate some real data.
We’ll look at data traffic on the Abilene network:
Source: Internet2, circa 2005
Code
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltwithopen('data/net-traffic/AbileneFlows/odnames','r') as f: odnames = [line.strip() for line in f]dates = pd.date_range('9/1/2003', freq ='10min', periods =1008)Atraf = pd.read_table('data/net-traffic/AbileneFlows/X', sep=' ', header=None, names=odnames, engine='python')Atraf.index = datesAtraf.head(4)
ATLA-ATLA
ATLA-CHIN
ATLA-DNVR
ATLA-HSTN
ATLA-IPLS
ATLA-KSCY
ATLA-LOSA
ATLA-NYCM
ATLA-SNVA
ATLA-STTL
...
WASH-CHIN
WASH-DNVR
WASH-HSTN
WASH-IPLS
WASH-KSCY
WASH-LOSA
WASH-NYCM
WASH-SNVA
WASH-STTL
WASH-WASH
2003-09-01 00:00:00
8466132.0
29346537.0
15792104.0
3646187.0
21756443.0
10792818.0
14220940.0
25014340.0
13677284.0
10591345.0
...
53296727.0
18724766.0
12238893.0
52782009.0
12836459.0
31460190.0
105796930.0
13756184.0
13582945.0
120384980.0
2003-09-01 00:10:00
20524567.0
28726106.0
8030109.0
4175817.0
24497174.0
8623734.0
15695839.0
36788680.0
5607086.0
10714795.0
...
68413060.0
28522606.0
11377094.0
60006620.0
12556471.0
32450393.0
70665497.0
13968786.0
16144471.0
135679630.0
2003-09-01 00:20:00
12864863.0
27630217.0
7417228.0
5337471.0
23254392.0
7882377.0
16176022.0
31682355.0
6354657.0
12205515.0
...
67969461.0
37073856.0
15680615.0
61484233.0
16318506.0
33768245.0
71577084.0
13938533.0
14959708.0
126175780.0
2003-09-01 00:30:00
10856263.0
32243146.0
7136130.0
3695059.0
28747761.0
9102603.0
16200072.0
27472465.0
9402609.0
10934084.0
...
66616097.0
43019246.0
12726958.0
64027333.0
16394673.0
33440318.0
79682647.0
16212806.0
16425845.0
112891500.0
4 rows × 121 columns
Atraf.shape
(1008, 121)
As we would expect, our traffic matrix has rank 121:
np.linalg.matrix_rank(Atraf)
np.int64(121)
However – perhaps it has low effective rank.
The numpy routine for computing the SVD is np.linalg.svd:
u, s, vt = np.linalg.svd(Atraf)
Now let’s look at the singular values of Atraf to see if it can be usefully approximated as a low-rank matrix:
In other words, \(\mathbf{u}_1\) (the first column of \(U\)) is the “strongest” pattern occurring in \(A\), and its strength is measured by \(\sigma_1\).
Here is a view of the first 2 columns of \(U\Sigma\) for the traffic matrix data.
These are the strongest patterns occurring across all of the 121 traces.
Code
u, s, vt = np.linalg.svd(Atraf, full_matrices=False)uframe = pd.DataFrame(u @ np.diag(s), index=pd.date_range('9/1/2003', freq ='10min', periods =1008))uframe[0].plot(color='r', label='Column 1')uframe[1].plot(label='Column 2')plt.legend(loc='best')plt.title('First Two Columns of $U$')plt.show()
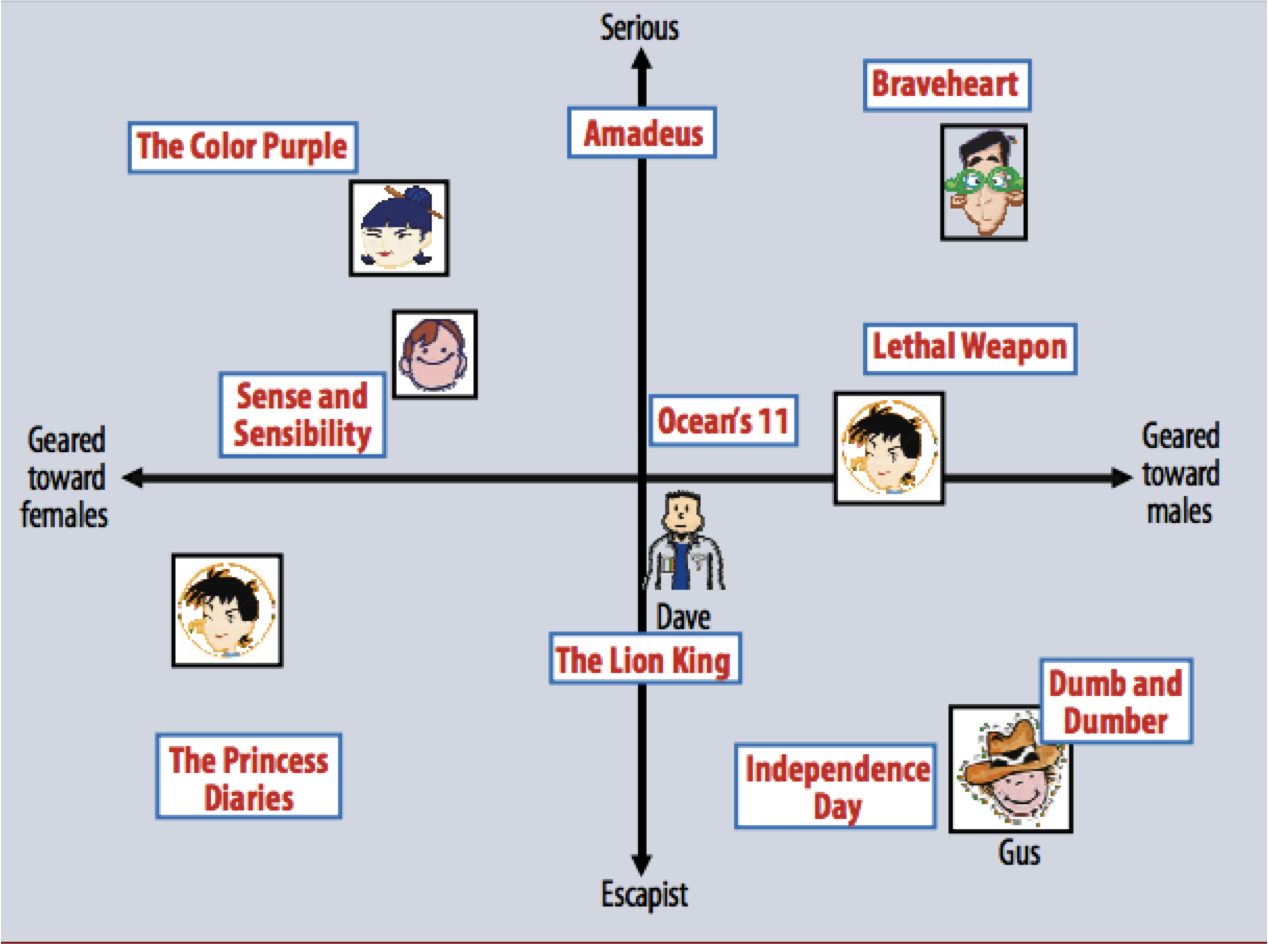
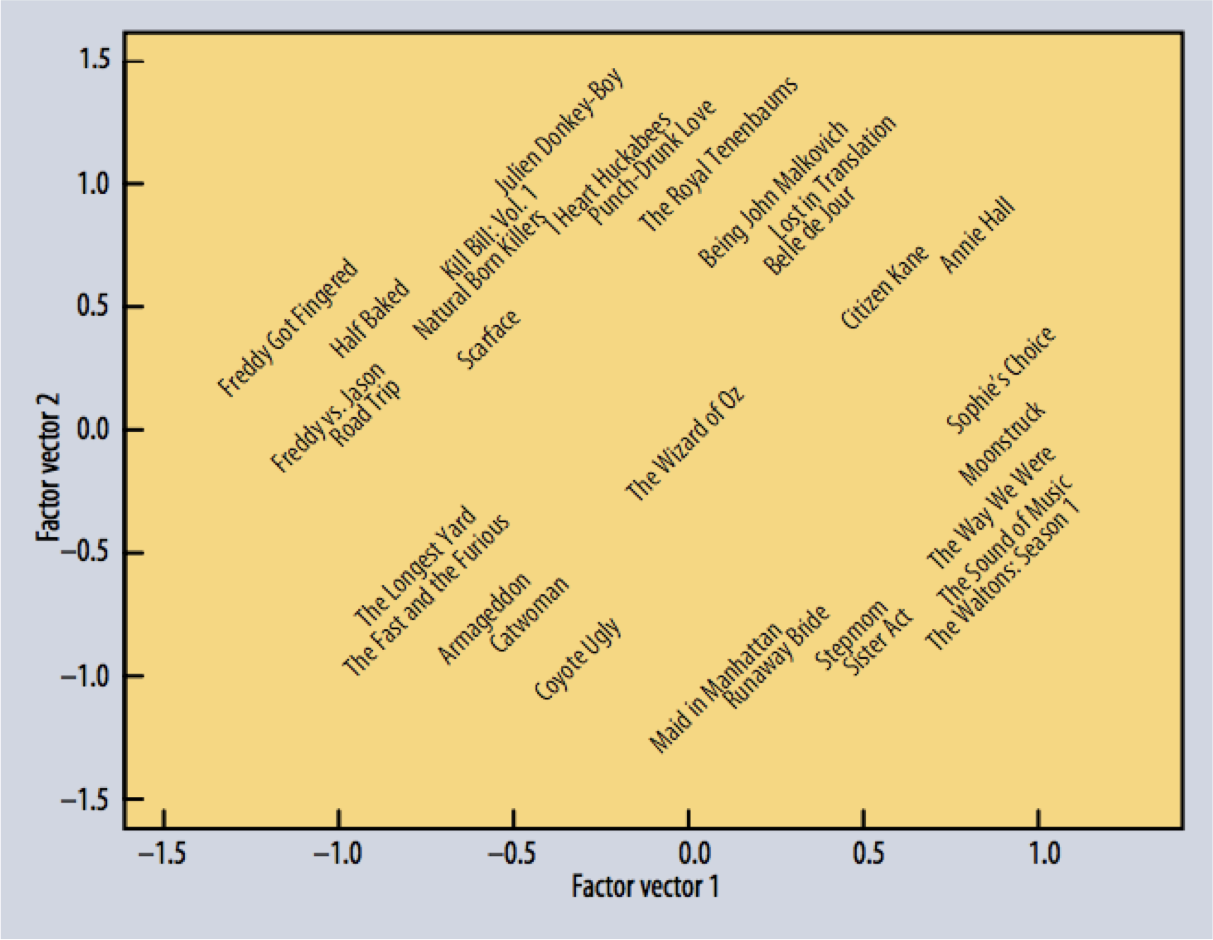
Low Rank Defines Latent Factors
The next interpretation of low-rank behavior is that it exposes “latent factors” that describe the data.
In this interpretation, we think of each element of \(A^{(k)}=U'\Sigma'(V')^T\) as the inner product of a row of \(U'\Sigma'\) and a column of \((V')^{T}\) (equivalently a row of \(V'\)).
Let’s say we are working with a matrix of users and items.
In particular, let the items be movies and matrix entries be ratings, as in the Netflix prize.
where the rows of \(A\) are the users and the columns are movie ratings.
Then the rating that a user gives a movie is the inner product of a \(k\)-element vector that corresponds to the user, and a \(k\)-element vector that corresponds to the movie.

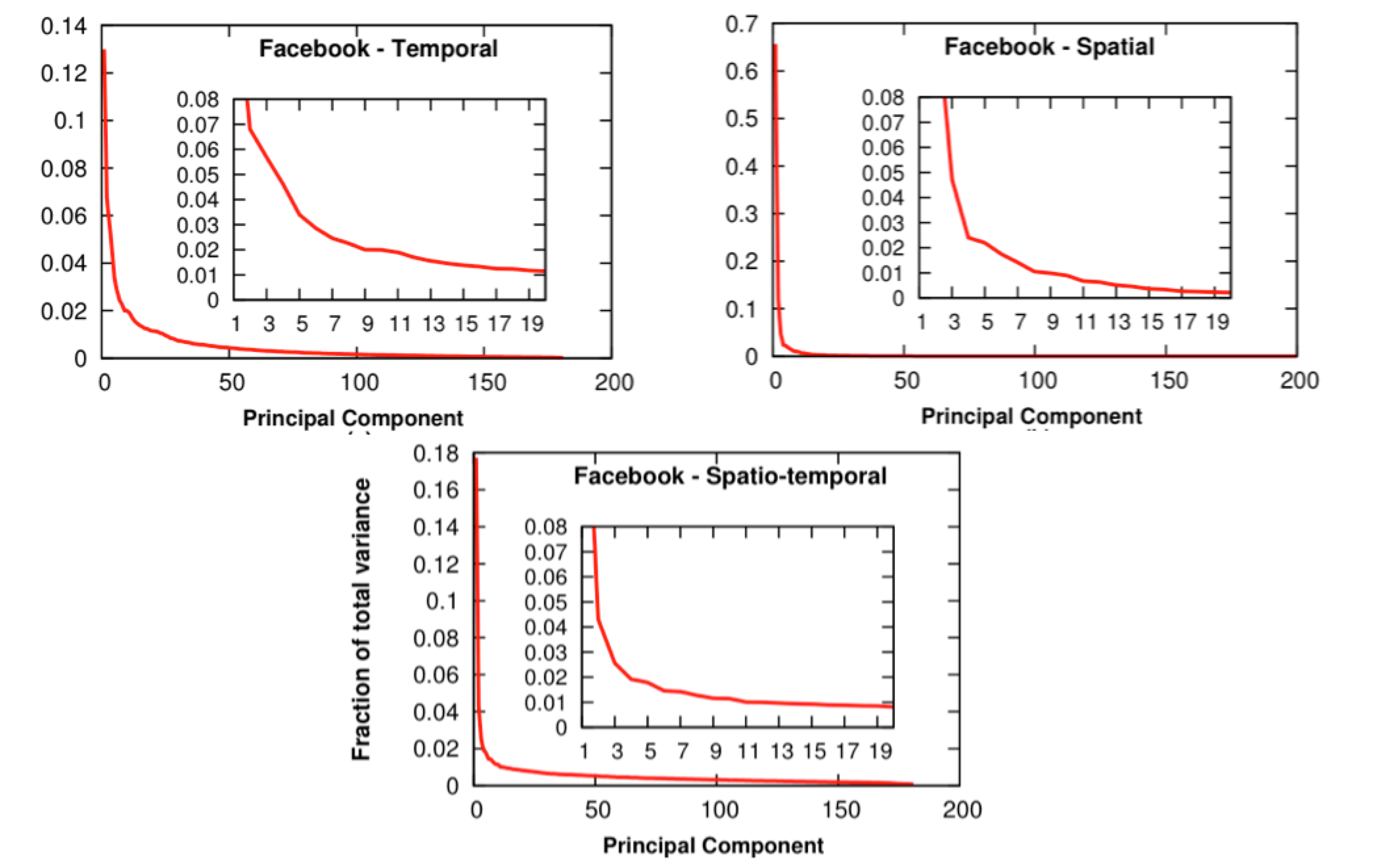
Social Media Activity
Here, the matrices are
Source: [Viswanath et al., Usenix Security, 2014]