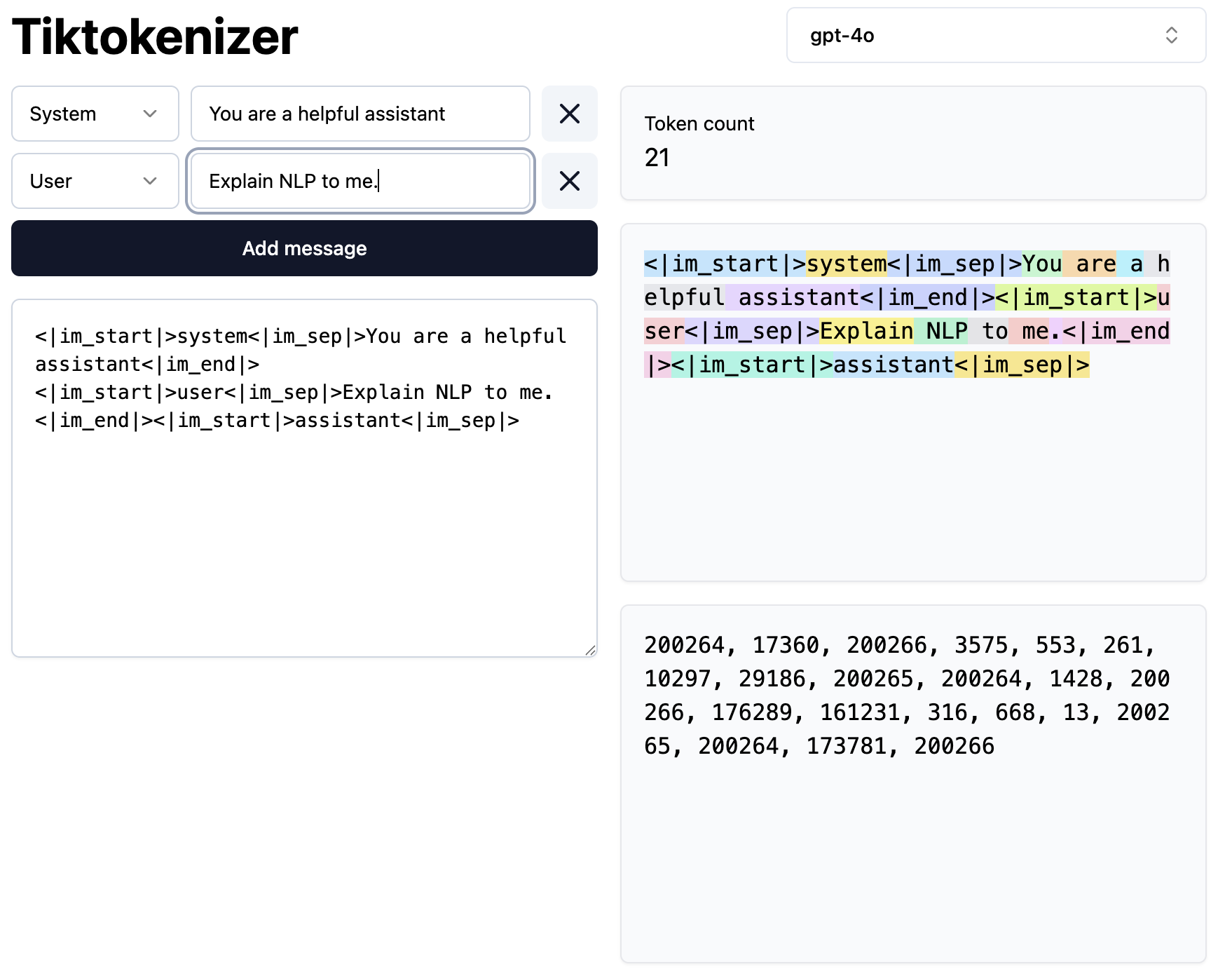
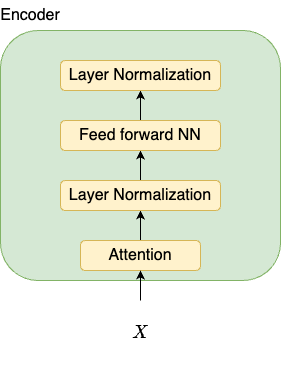
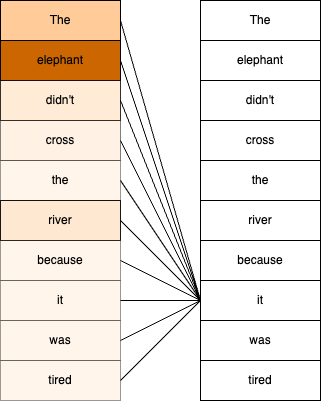
Top words per topic:
Topic 0: the(0.02), he(0.02), to(0.02), in(0.02), that(0.02), and(0.01), his(0.01), of(0.01)
Topic 1: the(0.03), to(0.02), of(0.02), space(0.02), and(0.02), launch(0.02), that(0.02), in(0.02)
Topic 2: image(0.03), and(0.03), for(0.02), of(0.02), or(0.02), it(0.02), the(0.01), is(0.01)
Topic 3: the(0.03), points(0.02), den(0.02), is(0.02), of(0.02), problem(0.02), this(0.02), algorithm(0.02)
Topic 4: the(0.03), of(0.02), sky(0.02), to(0.02), that(0.02), in(0.02), it(0.02), is(0.02)
Topic 5: jpeg(0.06), gif(0.03), file(0.03), you(0.03), image(0.03), format(0.02), is(0.02), to(0.02)
Topic 6: hello(2.78), why(1.76), (0.00), (0.00), (0.00), (0.00), (0.00), (0.00)
Topic 7: card(0.05), vesa(0.04), mode(0.04), driver(0.03), vga(0.03), video(0.02), drivers(0.02), modes(0.02)
Topic 8: for(0.02), and(0.02), data(0.02), ftp(0.02), available(0.02), the(0.02), in(0.02), is(0.01)
Topic 9: hst(0.05), reboost(0.03), the(0.03), mission(0.02), to(0.02), shuttle(0.02), is(0.02), mass(0.02)
Topic 10: conference(0.04), int(0.03), nok(0.03), opcols(0.02), oprows(0.02), for(0.02), and(0.02), on(0.02)
Topic 11: the(0.02), to(0.02), oxygen(0.02), of(0.02), is(0.02), it(0.02), in(0.02), be(0.02)
Topic 12: oort(0.04), the(0.03), cloud(0.03), grbs(0.03), of(0.03), distribution(0.03), burst(0.02), detectors(0.02)
Topic 13: siggraph(0.05), me(0.02), membership(0.02), to(0.02), send(0.02), you(0.02), my(0.02), address(0.02)
Topic 14: launch(0.04), of(0.02), km(0.02), constant(0.02), is(0.02), the(0.02), orbit(0.02), mass(0.02)
Topic 15: question(0.06), 42(0.06), tea(0.05), number(0.04), answer(0.03), two(0.03), the(0.03), peter(0.03)
Topic 16: colour(0.04), rgb(0.03), color(0.03), luminosity(0.03), colours(0.02), bits(0.02), to(0.02), green(0.02)
Topic 17: group(0.05), groups(0.04), newsgroup(0.04), aspects(0.03), this(0.03), liefting(0.03), split(0.03), of(0.03)
Topic 18: space(0.03), propulsion(0.03), of(0.02), and(0.02), the(0.02), for(0.02), fusion(0.02), lunar(0.02)
Topic 19: xv(0.08), bit(0.04), 24bit(0.04), image(0.04), is(0.03), it(0.03), you(0.03), 24(0.03)
Topic 20: joke(0.07), arbitron(0.04), deleted(0.03), was(0.03), it(0.03), flame(0.03), thought(0.03), humour(0.03)
Topic 21: menu(0.04), image(0.03), pressing(0.03), program(0.03), bits(0.03), display(0.03), you(0.03), read(0.03)
Topic 22: sail(0.04), solar(0.04), pluto(0.03), mission(0.03), to(0.02), be(0.02), would(0.02), the(0.02)
Topic 23: gopher(0.03), space(0.03), search(0.03), list(0.02), nasa(0.02), telescope(0.02), and(0.02), of(0.02)
Topic 24: that(0.03), was(0.02), and(0.02), sgi(0.02), upgrade(0.02), lcd(0.02), screen(0.02), customers(0.02)
Topic 25: space(0.06), nasa(0.03), astronaut(0.03), and(0.03), center(0.02), of(0.02), for(0.02), in(0.02)
Topic 26: phigs(0.06), graphics(0.03), computer(0.03), and(0.03), visualization(0.03), will(0.02), of(0.02), be(0.02)
Topic 27: software(0.09), process(0.06), level(0.05), shuttle(0.03), wingert(0.03), warning(0.03), is(0.03), bret(0.03)
Topic 28: hacker(0.08), hackers(0.04), who(0.03), to(0.03), ethic(0.02), the(0.02), computer(0.02), of(0.02)
Topic 29: probe(0.03), april(0.03), the(0.03), mars(0.02), was(0.02), spacecraft(0.02), on(0.02), and(0.02)
Topic 30: why(1.76), of(0.39), (0.00), (0.00), (0.00), (0.00), (0.00), (0.00)
Topic 31: wings(0.09), aircraft(0.05), pat(0.04), sweep(0.04), flybywire(0.04), military(0.04), supersonic(0.03), x15(0.03)
Topic 32: gamma(0.09), tiff(0.08), correction(0.06), image(0.04), images(0.03), that(0.03), is(0.02), to(0.02)
Topic 33: gun(0.05), the(0.03), ssrt(0.03), projectile(0.03), it(0.02), of(0.02), is(0.02), to(0.02)
Topic 34: sam(0.11), ls(0.09), my(0.08), telling(0.08), yeah(0.07), mom(0.07), elvis(0.07), lemur(0.07)
Topic 35: cview(0.16), temp(0.09), file(0.05), it(0.05), floppy(0.04), disk(0.04), files(0.04), directory(0.04)
Topic 36: spacecraft(0.07), mode(0.04), hga(0.03), be(0.03), that(0.03), it(0.03), earth(0.02), could(0.02)