We now consider a new kind of data, networks, which are represented by graphs.
Motivation
Graphs allow us to represent and analyze complex relationships and structures in data.
By using nodes (vertices) and edges (connections), graphs can model various types of relationships and interactions, making it easier to visualize and understand the underlying patterns.
Example Applications in Machine Learning
Social Network Analysis
Model social networks with nodes representing individuals and edges representing relationships or interactions.
Understand community structures, influence, and information spread.
Biological Network Analysis
Model biological systems, such as protein-protein interaction networks.
Understand cellular processes and disease mechanisms.
Knowledge Graphs
Store and retrieve structured information.
Enable better search and question-answering systems.
Natural Language Processing (NLP)
Use dependency parsing to represent the grammatical structure of sentences.
Aid in tasks like machine translation and sentiment analysis.
Recommendation Systems
Use graph-based algorithms like collaborative filtering.
Recommend products or content by analyzing relationships between users and items.
Fraud Detection
Detect fraudulent activities by identifying unusual patterns and connections in financial transactions.
Graphs
A graph \(G=(V, E)\) is a pair, where \(V\) is a set of vertices, and \(E\) is a set of unordered vertex pairs \((u, v)\) called edges.
The term nodes is also used for vertices. The term links or connections is also used for edges.
We’ll distinguish between undirected graphs and directed graphs.
NetworkX
We’ll use the NetworkX library to create and manipulate graphs.
import networkx as nx
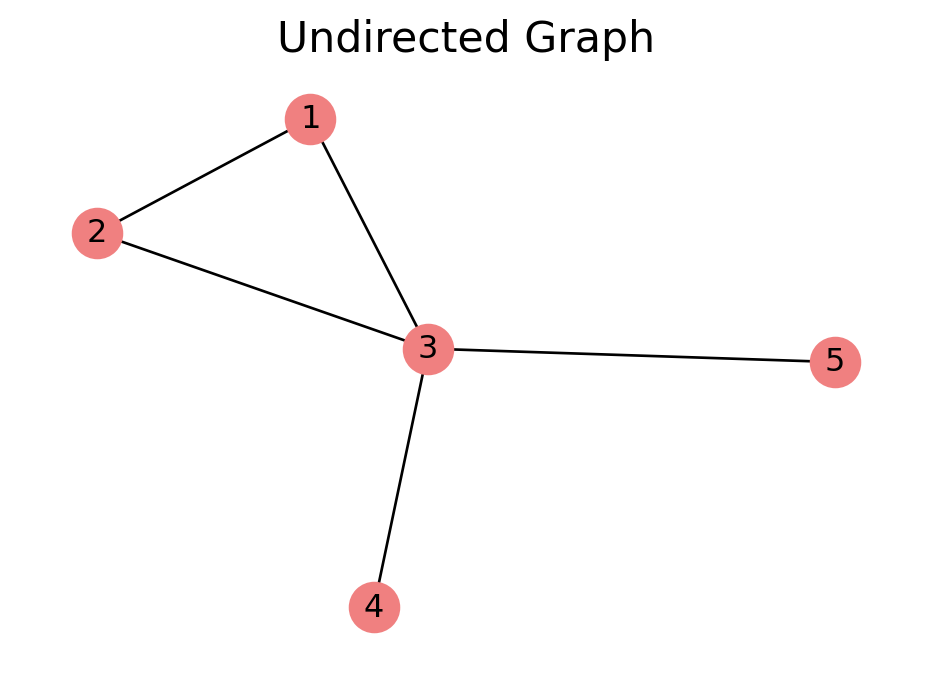
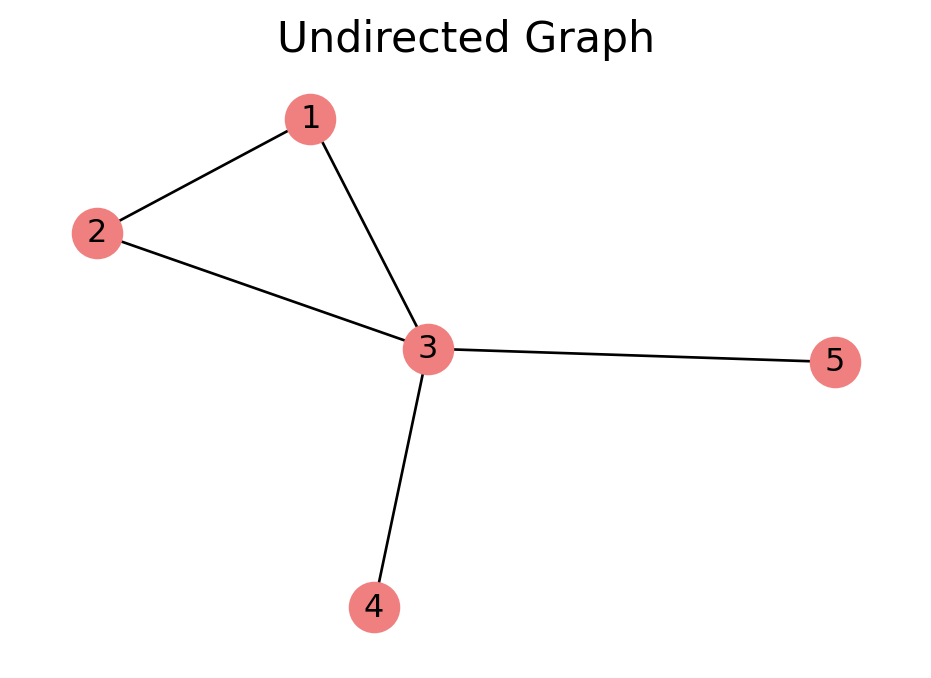
Undirected Graphs
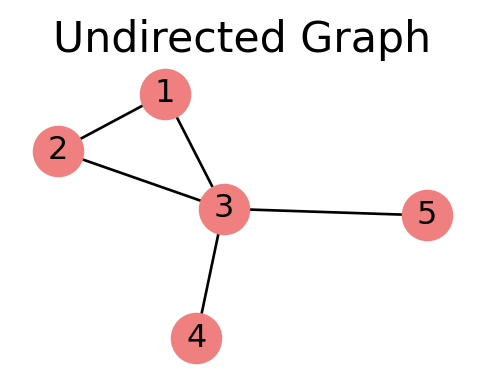
In an undirected graph, an edge \((u, v)\) is an unordered pair. The edge \((v, u)\) is the same thing.
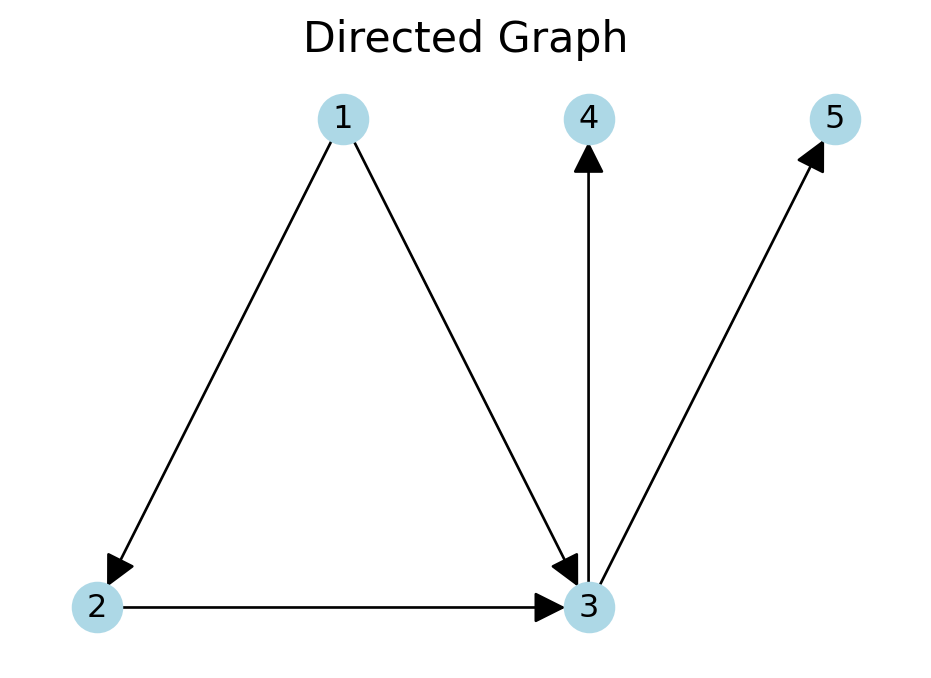
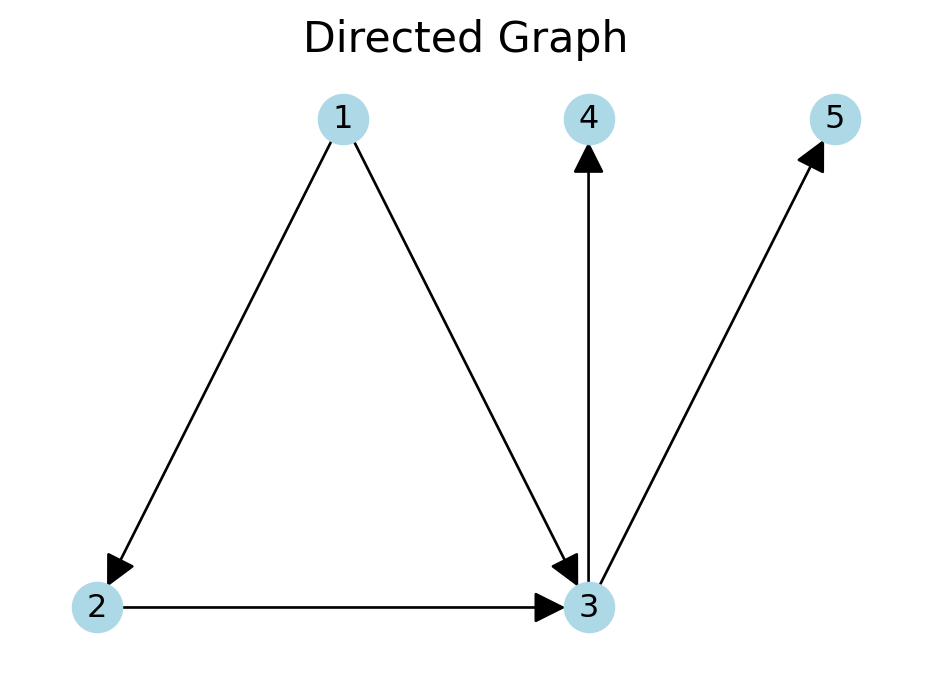
In a directed graph, \((u, v)\) is an ordered pair and it is different from \((v, u)\).
This means that the edges have an orientation. This orientation is indicated by arrows.
For example, the edge \((1, 2)\), is directed from node 1 to node 2.
Code
# Create a directed graphDG = nx.DiGraph()DG.add_edges_from([(1,2), (1,3), (2, 3), (3, 4), (3, 5)])pos = { # positions for each node, defaults to spring layout1: [0, 0],2: [-1, -1],3: [1, -1],4: [1, 0],5: [2, 0]}# Plot the directed graphplt.figure(figsize=(6, 4))nx.draw_networkx(DG, node_size=300, edge_color='k', node_color='lightblue', pos=pos, with_labels=True, arrowsize=25, alpha=1, linewidths=2)plt.title('Directed Graph', size=16)plt.axis('off')plt.show()
Paths
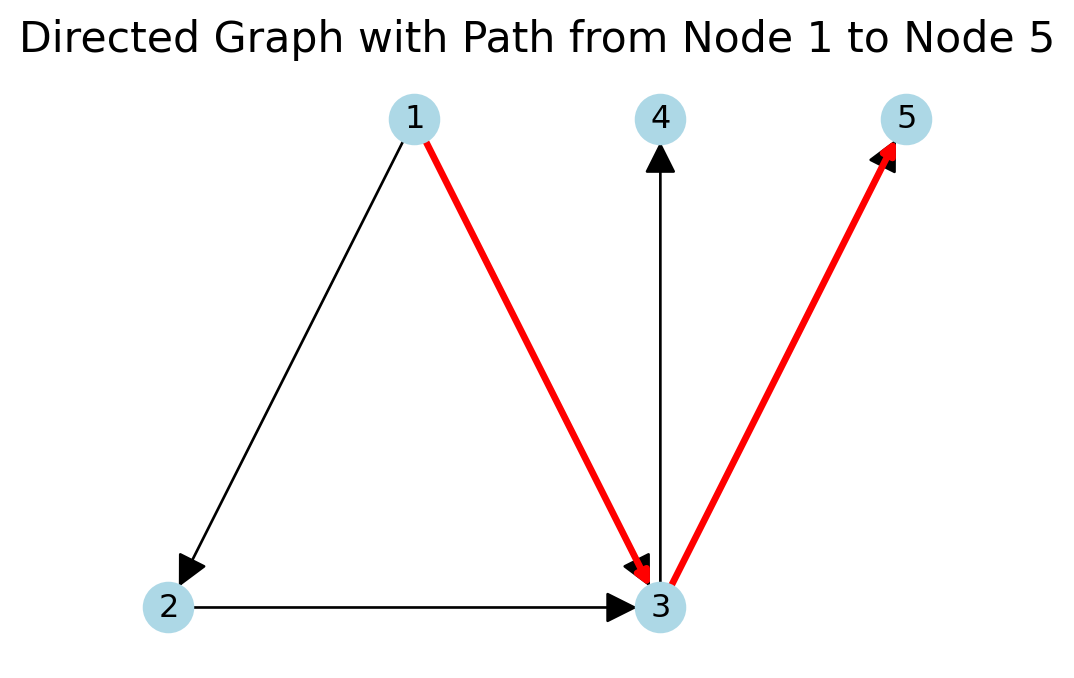
A path in a graph from node \(u\) to node \(v\) is a sequence of edges that starts at \(u\) and ends at \(v\). Paths exist in both undirected and directed graphs.
In a directed graph, all of the edges in a path need to be oriented head-to-tail.
If there is a path from \(u\) to \(v\), we say that \(v\) is reachable from \(u\).
A path from node 1 to node 5 is illustrated in red.
Code
# Create a directed graphDG = nx.DiGraph()DG.add_edges_from([(1, 2), (1, 3), (2, 3), (3, 4), (3, 5)])# Define positions for the nodespos = {1: [0, 0],2: [-1, -1],3: [1, -1],4: [1, 0],5: [2, 0]}# Define the path from node 1 to node 5path_edges = [(1, 3), (3, 5)]# Plot the directed graphplt.figure(figsize=(6, 4))nx.draw_networkx(DG, node_size=300, edge_color='k', node_color='lightblue', pos=pos, with_labels=True, arrowsize=25, alpha=1, linewidths=2)# Highlight the path from node 1 to node 5nx.draw_networkx_edges(DG, pos, edgelist=path_edges, edge_color='r', width=2.5)plt.title('Directed Graph with Path from Node 1 to Node 5', size=16)plt.axis('off')plt.show()
Degree
The degree of a node is the number of edges that connect to it.
In our example undirected graph, node \(3\) has degree 4.
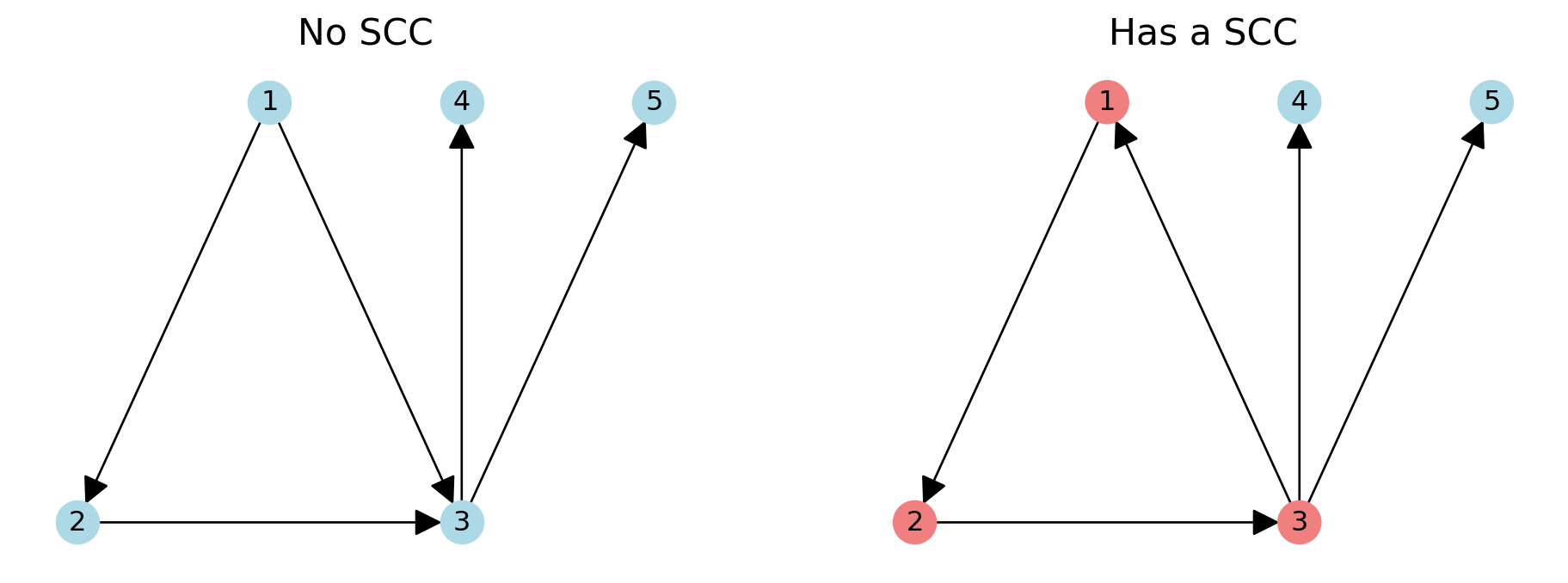
In a directed graph, we distinguish between:
in-degree: the number of incoming edges to the node,
out-degree: the number of outgoing edges to the node.
In our directed graph example, the in-degree of node \(3\) is 2 and the out-degree is \(2\). For node \(1\), the in-degree is \(0\), and the out-degree is \(2\).
In an undirected graph with \(n\) nodes and \(e\) edges, the average node degree is \(2e/n\). Why?
If you sum the degrees of all nodes, you count each edge twice (once for each endpoint). The total degree of all nodes is then \(2e\). The average is then \(2e/n\).
In our previous undirected graph example, the total degree is \[
\text{Total Degree} = 2 + 2 + 4 + 1 + 1 = 10.
\]
The number of edges is \(5\) and \(2\cdot 5 = 10\).
Neighbors
The neighbors of a node are the nodes to which it is connected.
In an undirected graph, the degree of a node is the number of neighbors it has.
A directed graph has both outgoing and incoming neighbors.
Connectivity
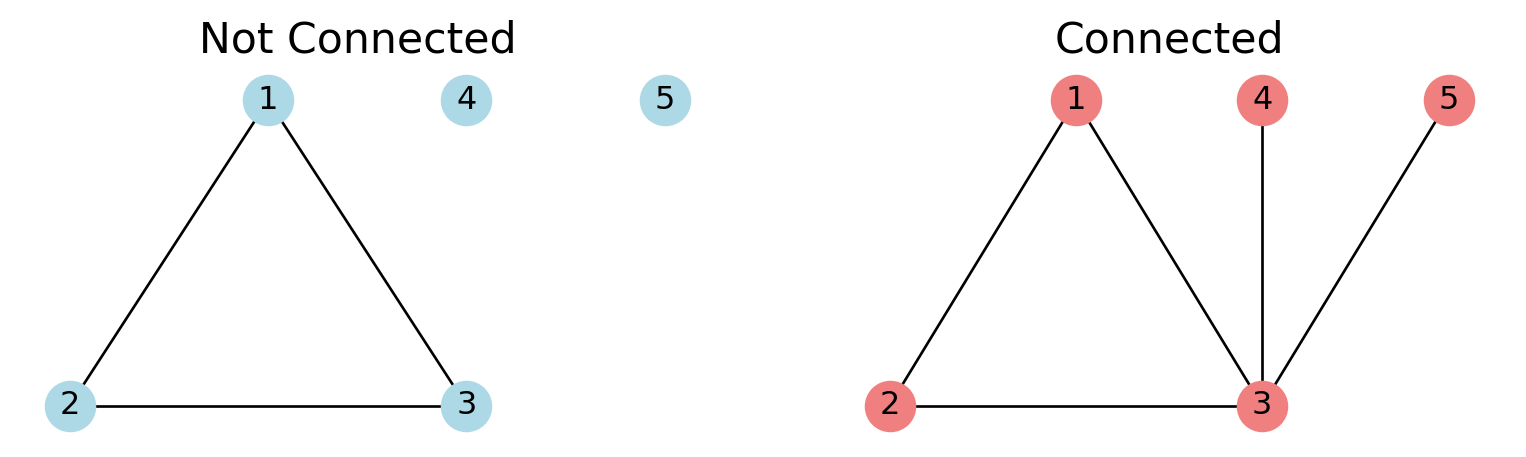
The first question to ask about a graph is: is it connected?
An undirected graph is connected, if for each pair of nodes \((u, v)\), \(u\) is reachable from \(v\). A directed graph is connected when its undirected version is connected.
Given a graph, it is helpful to characterize the degrees, components, and other structures in the graph.
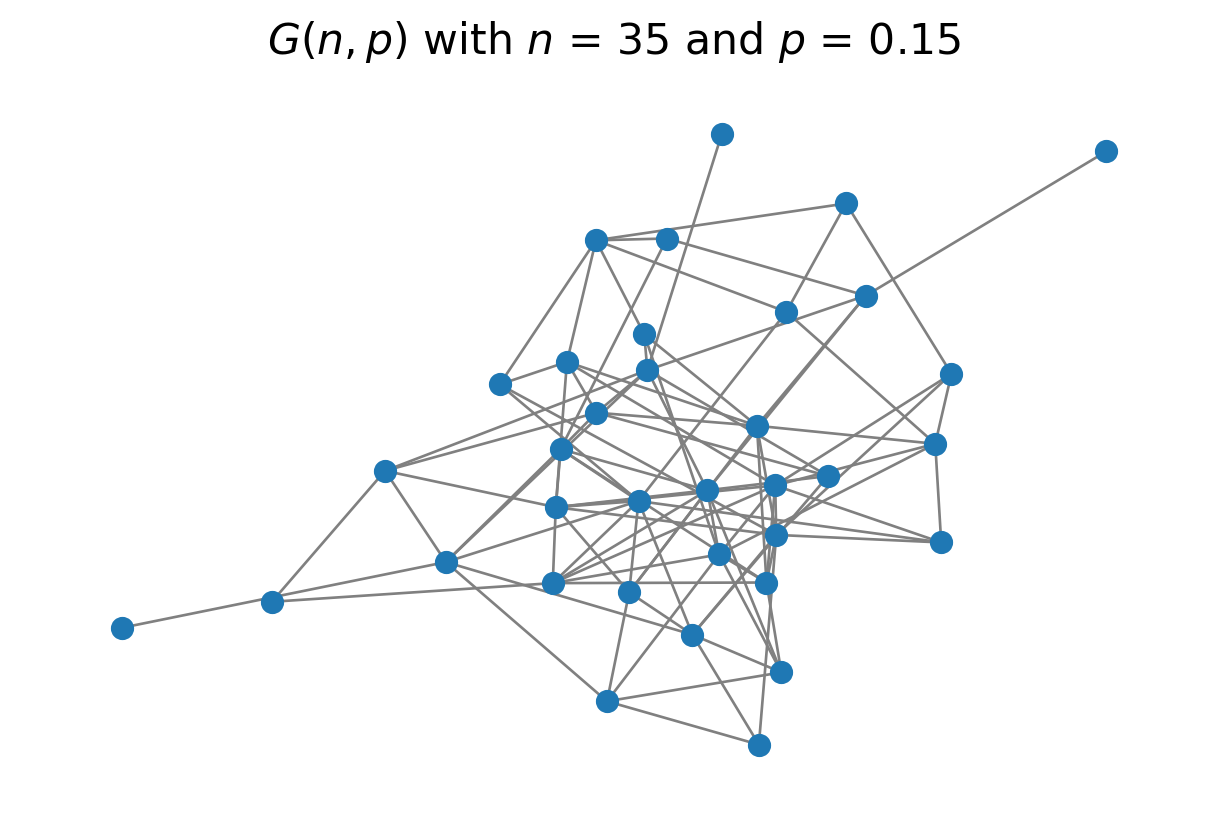
Comparison Case: the \(G(n, p)\) Random Graph
The most common comparison is the \(G(n, p)\) random graph. It is also called the Erdős–Rényi graph, after the two mathematicians who developed and studied it.
The \(G(n, p)\) random graph model is very simple
we start with a set of \(n\) nodes,
for each pair of nodes, we connect them with probability \(p\).
Average Node Degree of a Random Graph
Every node is potentially connected to \(n-1\) other nodes.
Therefore, the expected degree, call it \(\langle k \rangle\), of a node is given by:
\[
\langle k \rangle = p \cdot (n - 1)
\]
For large \(n\), this can be approximated as:
\[
\langle k \rangle \approx np
\]
So for random graphs, the average node degree is \(np\).
In this graph, the average degree is \(np = 35 \cdot 0.15 = 5.25\)
Most real-world graphs do not match the properties of \(G(n, p)\) graphs, however it is useful to have a comparison to a random graph.
Degree Distributions
Understanding connectivity starts with determining the observed degrees in the graph.
This is captured in the degree distribution
\[
P(X > x) = \text{probability that a node has degree at least } x.
\]
We typically focus our attention on large values of \(x\) – nodes that are highly connected.
This is technically a complementary cumulative distribution function (CCDF) or sometimes called the survival function of the distribution.
\[
P(X > x) = 1 - P(X \leq x).
\]
where \(P(X \leq x)\) is the cumulative distribution function (CDF).
Power Law Degree Distributions
It’s common for a degree distribution to approximately follow a power-law.
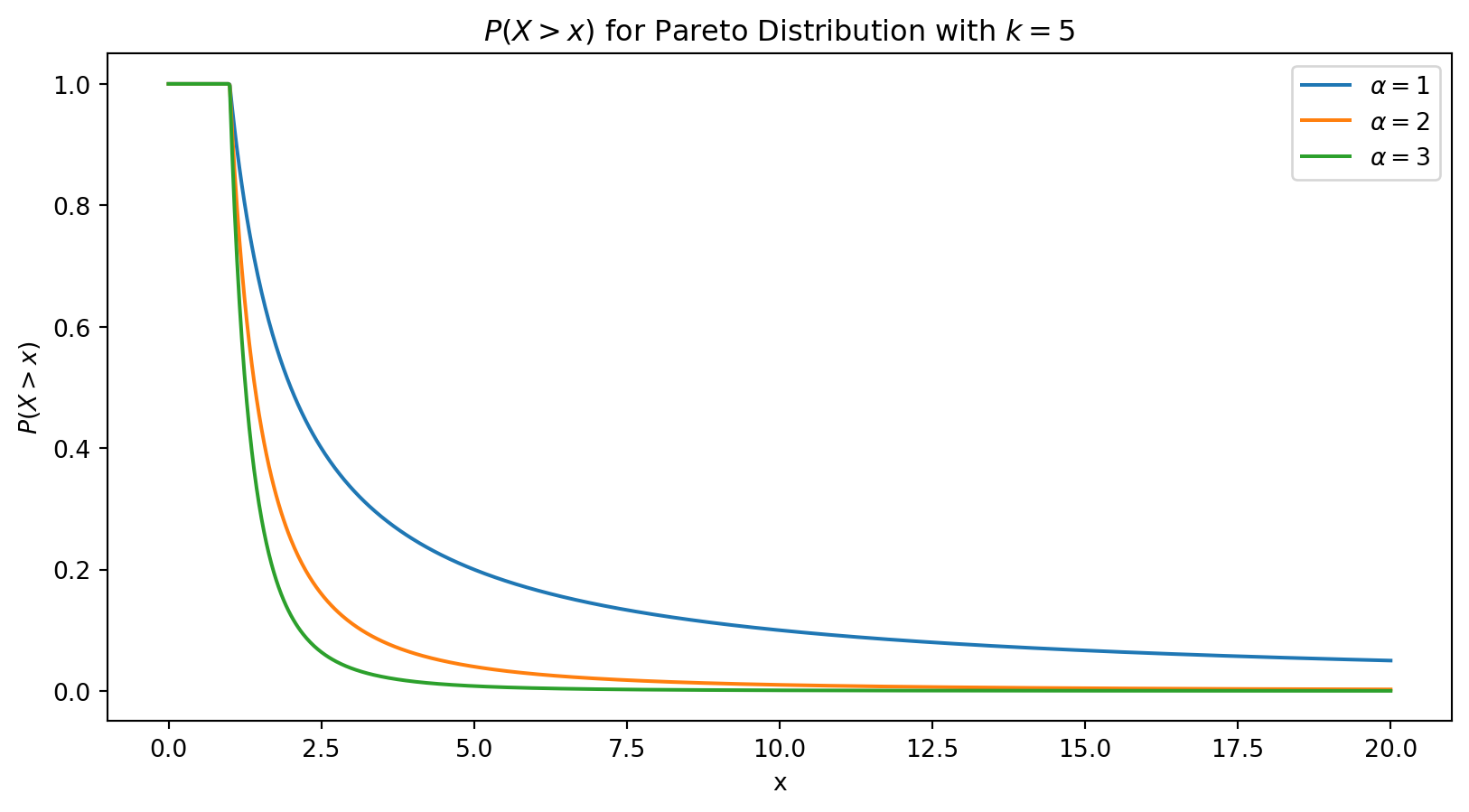
The simplest power-law distribution is called the Pareto distribution. If X is a random variable with a Pareto distribution, then the probability that X is greater than some number \(x\) is given by:
\[ P(X > x) =
\begin{cases}
\left(\frac{k}{x}\right)^{\alpha} & x \geq k, \\
1 & x < k
\end{cases}
\]
where \(k\) is the minimum value of \(X\), sometimes called the scale parameter, meaning we can specify the minimum number of neighbors a node can have.
And \(\alpha\) is the exponent, sometimes called the shape parameter.
Distribution Plot
Here is a plot for different values of \(\alpha\) and \(k=1\).
Code
# Define the range of x valuesx = np.linspace(0, 20, 1000)# Define the Pareto distribution function for P(X > x)def pareto_cdf_complement(x, alpha, k=1):return np.where(x >= k, (k / x)**alpha, 1)# Plot the Pareto distribution for alpha values 1, 2, and 3alphas = [1, 2, 3]for alpha in alphas: plt.plot(x, pareto_cdf_complement(x, alpha), label=f'$\\alpha={alpha}$')# Add title and labelsplt.title('$P(X > x)$ for Pareto Distribution with $k=5$')plt.xlabel('x')plt.ylabel('$P(X > x)$')# Add legendplt.legend()# Show the plotplt.show()
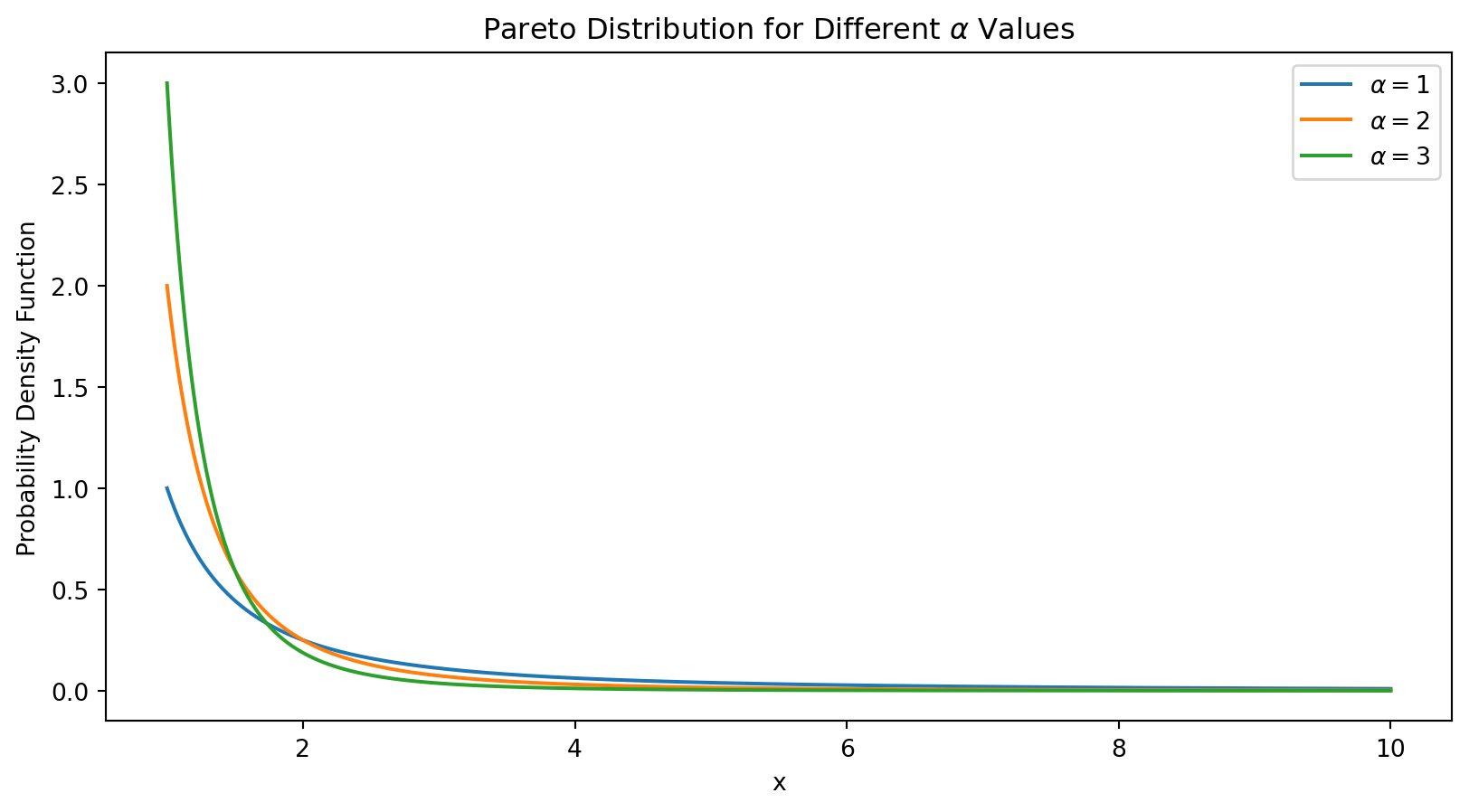
\[
p(x) =
\begin{cases}
\frac{\alpha k^{\alpha}}{x^{\alpha + 1}} & x \geq k, \\
0 & x < k.
\end{cases}
\]
Here is a plot of the Pareto probability density function for different values of \(\alpha\) and \(k=1\).
Code
import numpy as npimport matplotlib.pyplot as plt# Define the range of x valuesx = np.linspace(1, 10, 1000)# Define the Pareto distribution functiondef pareto_pdf(x, alpha, xm=1):return (alpha * xm**alpha) / (x**(alpha +1))# Set figure sizeplt.figure(figsize=(10, 4))# Plot the Pareto distribution for alpha values from 1 to 3alphas = [1, 2, 3]for alpha in alphas: plt.plot(x, pareto_pdf(x, alpha), label=f'$\\alpha={alpha}$')# Add title and labelsplt.title('Pareto Distribution for Different $\\alpha$ Values')plt.xlabel('x')plt.ylabel('Probability Density Function')# Add legendplt.legend()# Show the plotplt.show()
In a distribution like this, almost all values are very small. However, there is a non-negligible fraction of values that are very large.
Vilfredo Pareto originally used this distribution to describe the allocation of wealth among individuals. The size of sand particles are also seen as approximately Pareto-distributed.
What does this mean for node degree?
It means that
most nodes have few neighbors, but
an important small subset of nodes have many, many neighbors.
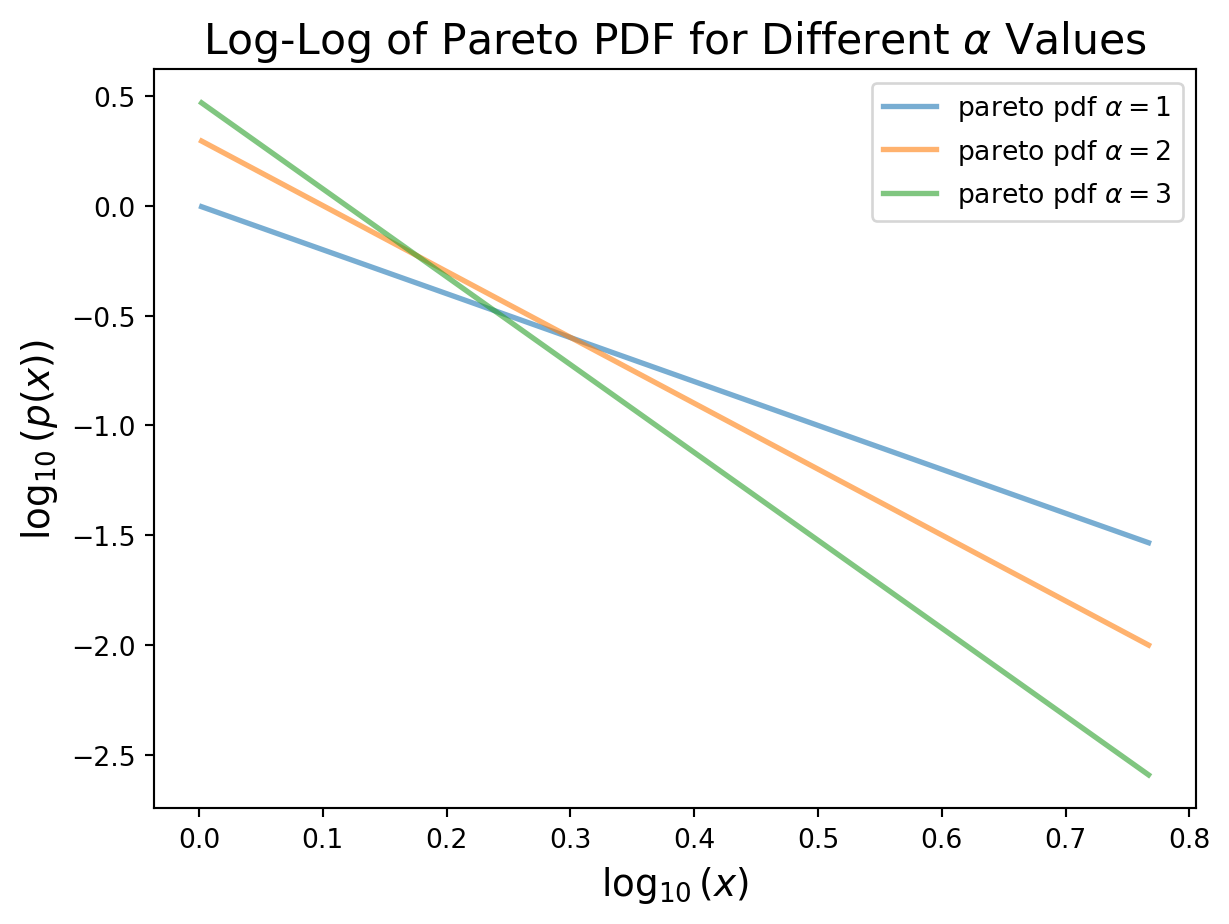
To capture such high-variable degree distributions, a common strategy is to plot them on log-log axes.
On log-log axes, a Pareto distribution appears as a straight line. You can verify this yourselves by computing
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import pareto# Define the range of x valuesx = np.linspace(pareto.ppf(0.005, 1), pareto.ppf(0.995, 3), 100)# Plot the log of the Pareto distribution for alpha values 1, 2, and 3alphas = [1, 2, 3]plt.figure(figsize=(8, 3.5))for alpha in alphas: plt.plot(np.log10(x), np.log10(pareto.pdf(x, alpha)), lw=2, alpha=0.6, label=f'pareto pdf $\\alpha={alpha}$')# Add title and labelsplt.title(r'Log-Log of Pareto PDF for Different $\alpha$ Values', size=16)plt.xlabel(r'$\log_{10}(x)$', size=14)plt.ylabel(r'$\log_{10}(p(x))$', size=14)# Add legendplt.legend()# Show the plotplt.show()
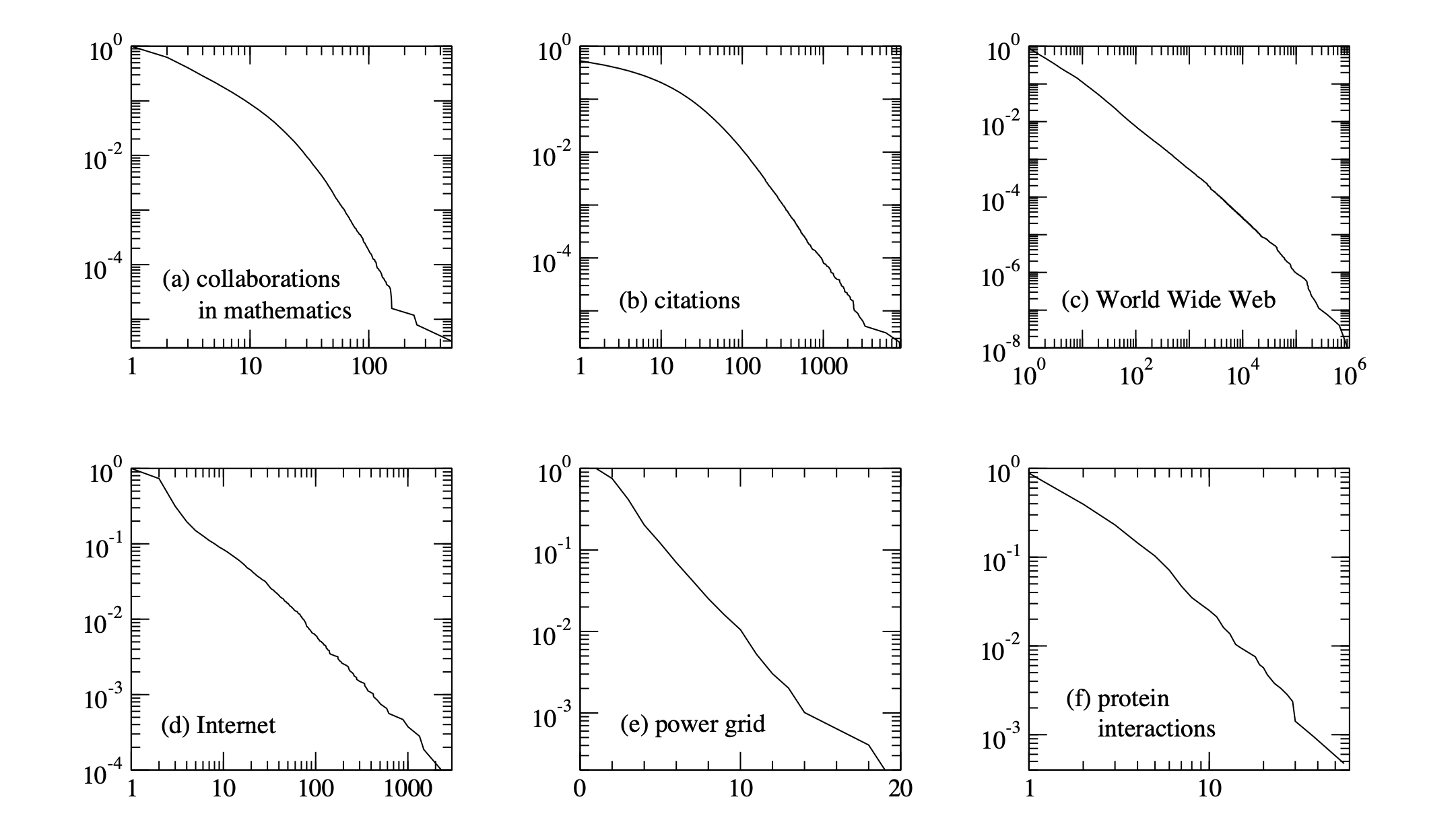
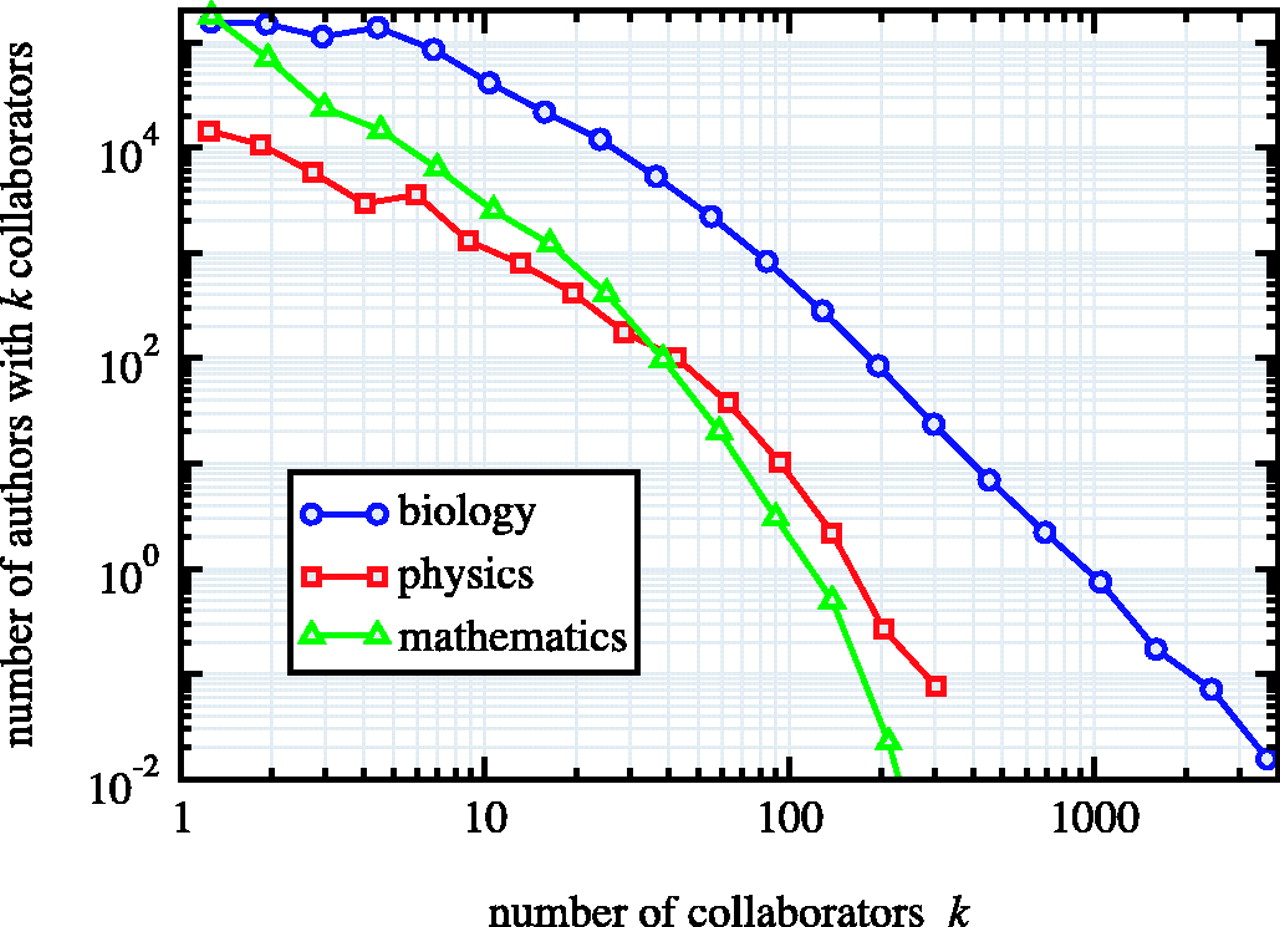
Power Law Degree Distributions are Ubiquitous
The networks shown are: (a) the collaboration network of mathematicians [182]; (b) citations between 1981 and 1997 to all papers cataloged by the Institute for Scientific Information [351]; (c) a 300 million vertex subset of the World Wide Web, circa 1999 [74]; (d) the Internet at the level of autonomous systems, April 1999 [86]; (e) the power grid of the western United States [416]; (f) the interaction network of proteins in the metabolism of the yeast S. Cerevisiae [212].
The structure and function of complex networks, M. E. J. Newman
https://arxiv.org/abs/cond-mat/0303516
Note that the \(x\)-axis of the power grid example is a linear scale but the \(y\)-axis is a log scale. This means that the degree distributions of the power grid example does not follow a power-law degree distribution. It has an exponential tail.
Clustering
The next important property of a network to understand is clustering.
In the context of networks, clustering refers to the tendency for groups of nodes to have higher connectivity within the group than the network-wide average.
The simplest measure of local clustering is clustering coefficient.
The clustering coefficient tells you if the neighbors of a node tend to be neighbors.
Specifically, the clustering coefficient measures the probability that two of your neighbors are connected.
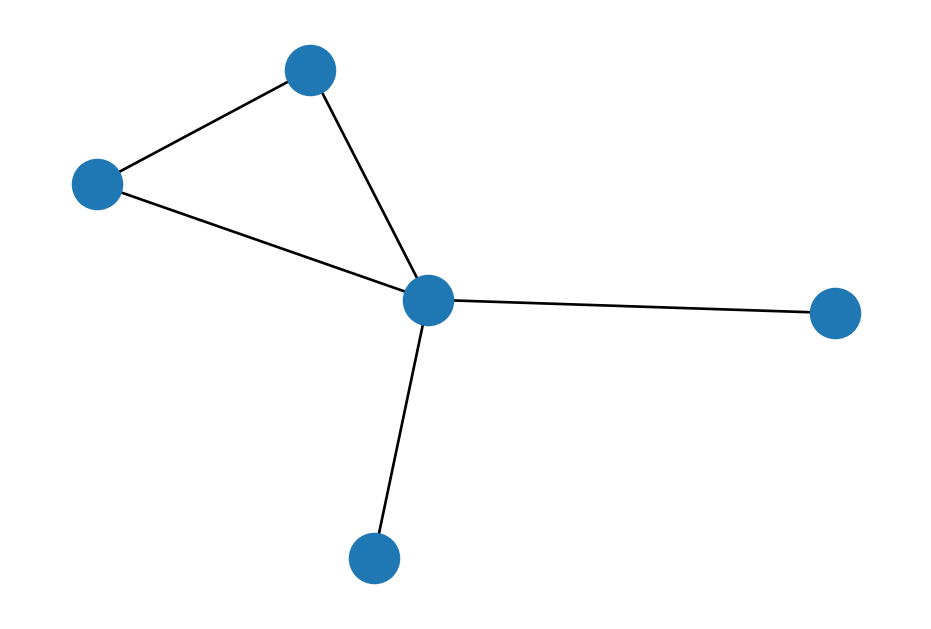
To define this measure, we introduce the notion of a triangle in a network. A triangle is a set of three nodes in the graph that are connected to each other.
There are two definitions of the clustering coefficient. The first is
\[
C^{(1)} = \frac{\sum_i \text{number of triangles that include node } i}{\sum_i \text{number of pairs of neighbors of node }i}.
\]
This is the ratio of the mean triangle count to mean neighbor pair count.
It is the probability that a random pair of neighbors are connected.
The second way to measure the clustering coefficient is the mean of the ratios, i.e.,
\[
C^{(2)} = \frac{1}{n} \sum_i \frac{\text{number of triangles that include node } i}{\text{number of pairs of neighbors of node }i},
\]
where \(n\) is the total number of nodes.
This is the probability that neighbors are connected for a random node.
In the previous example, \(C^{(2)} = \frac{1}{5} \left(1 + 1 + \frac{1}{6}\right) = \frac{13}{30} = 0.433.\)
What is the clustering coefficient in a \(G(n, p)\) random graph?
The probability that two of your neighbors are connected is the same as the probability that any two nodes are connected, i.e., \(C^{(1)} = C^{(2)} = p\).
Real World Graphs
In practice, real world graphs show strong clustering.
For example, consider a social network. Your friends are much more likely to be themselves friends than two randomly chosen people.
Clustering and Path Length: Small Worlds
The strong presence of clustering in networks leads to a question.
How long is a typical shortest path between nodes?
The average shortest path length between nodes is one way to measure a network’s diameter.
If \(d(i, j)\) represents the shortest path length between nodes (i) and (j), and \(N\) is the total number of nodes in the network, the average shortest path length \(L\) can be expressed as
\[
L = \frac{1}{\binom{N}{2}} \sum_{i \neq j} d_{\text{shortest}}(i, j).
\]
In this formula \(\binom{N}{2}\) is the number of unique pairs of nodes. The sum \(\sum_{i \neq j} d_{\text{shortest}}(i, j)\) is taken over all pairs of nodes (i) and (j).
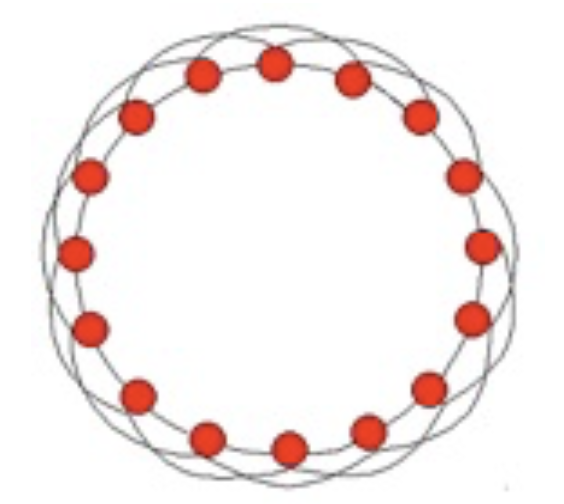
Let’s consider a highly clustered graph.
In this graph, each node has 4 neighbors. This means there are \(\binom{4}{2} = 6\) possible pairs of neighbors. Of these 6 neighbors, 3 are connected, yielding a clustering coefficient of 0.5. This is quite high.
This is an example of a ring lattice network with 4 vertices. The average shortest path between nodes in such graphs is approximately \(n/8\). On average you go 1/4 of the way around the circle, in hops of 2.
In this example, the path length grows linearly with \(n\) and if the number of nodes is large, the average path length is large.
Real-world social networks are highly clustered. Based on this model, we might assume that the average path length between two people in a large social network is going to be quite large. Is this really true?
If you choose two people at random from the population of the United States, is the shortest path length between them long?
In 1967 the social psychologist Stanley Milgram set out to empirically answer this question.
Milgram picked 160 people at random in Omaha, Nebraska. (It helped that there used to be phone books.)
He asked them to get a letter to a particular person, a stockbroker in Boston.
The rules that he set were that they could only pass the letter between friends that were known on a first-name basis.
Surprisingly, 62 of the letters made it to the stockbroker!
More surprising was the fact that the average path length was 6.2 people!
This statistic became famous when John Guare wrote a play called Six Degrees of Separation.
Given what we know about clustering in social networks, this is quite surprising. How can we explain it?
The first clue comes from another classic social science paper, called The Stength of Weak Ties, by Mark Granovetter.
This is sometimes referred to as the most famous paper in sociology (with over 60,000 citations).
Granovetter interviewed people about how they found their jobs. He found that most people did not get a job through someone that was a close friend, but rather through a distant acquaintance.
This suggests that an important way that information travels in a social network is via the rare connections that exist outside of the local clustering of friendships.
This was all put on an experimental basis in another classic paper, by the social scientist Duncan Watts and the mathematician Steve Strogatz.
In their paper Collective Dynamics of Small-World Networks, Watts and Strogatz perfomed an elegant experiment.
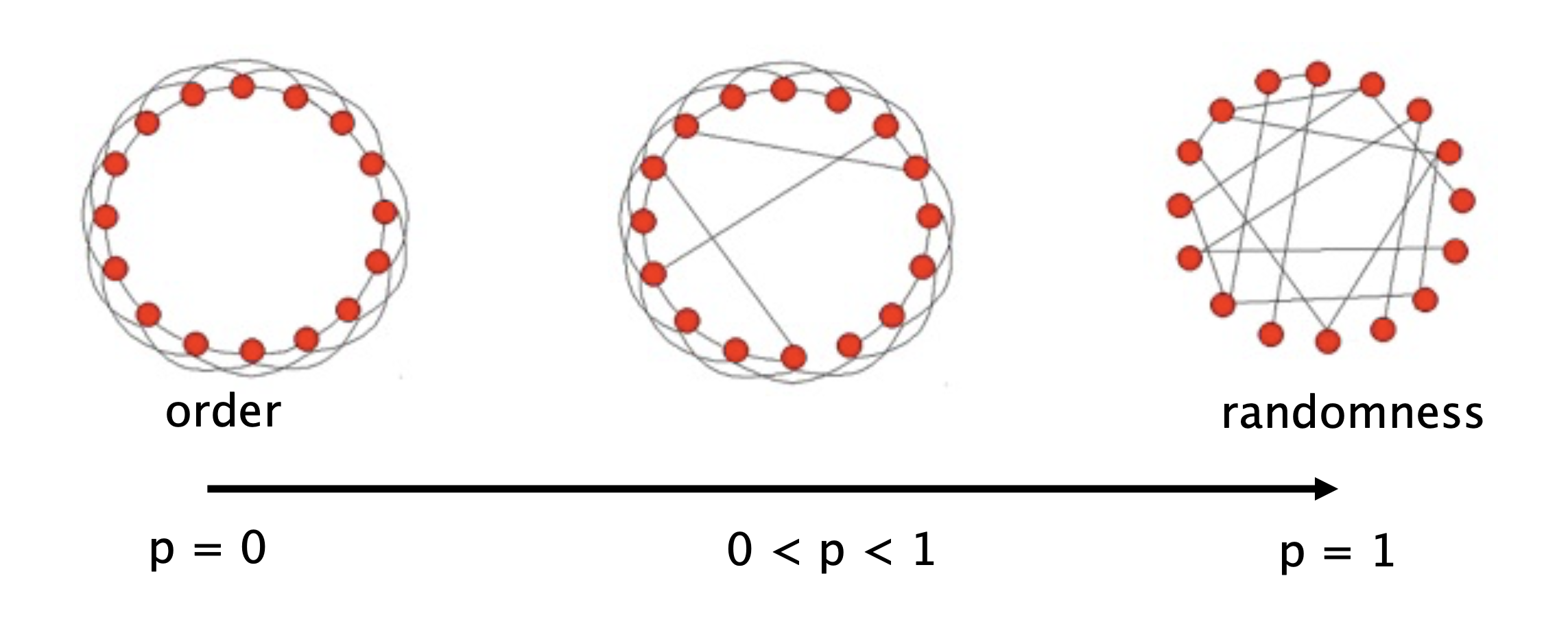
They asked, what if we take a highly clustered network, and slightly perturb it?
Specifically, they started with a network in which each node is connected to a fixed number of neighbors, and connections are made in a highly clustered way.
Then, with probability \(p\), rewire each edge: change it to connect to a random destination.
As \(p\) varies, what happens to
the average path length \(L(p)\) and
the clustering coefficient \(C(p)\)?
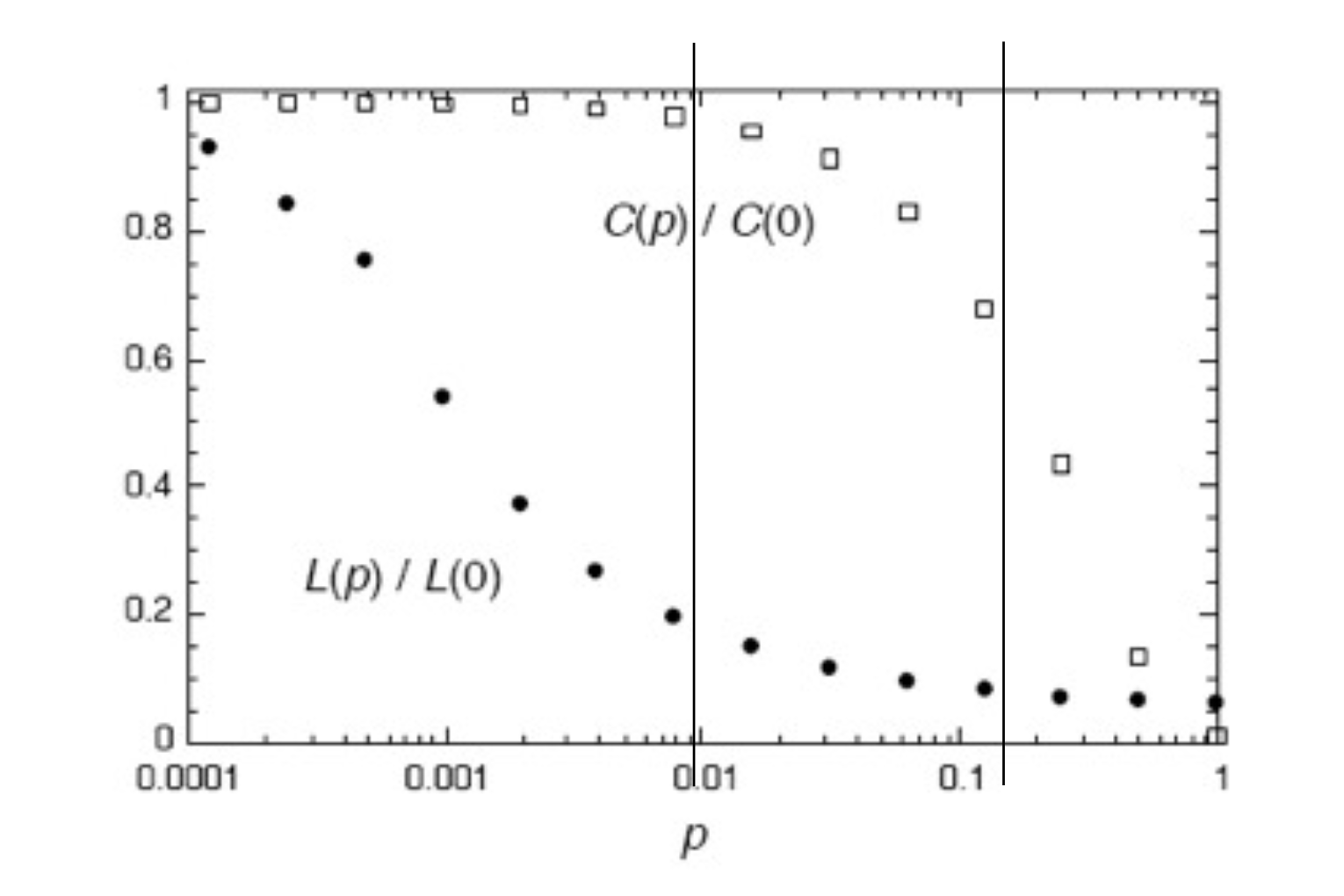
Here is the famous figure from that paper. Observe the log scale on the \(p\) axis. The values of both the average path length and the clustering coefficient are plotted, normalized by their values when \(p=0\).
What Watts and Strogatz showed is that it only takes a small amount of long-range connections to dramatically shrink the average path length between nodes.
They showed that high clustering and short path lengths can coexist. They called networks with high clustering and short path lengths small world networks.
This phenomenon expresses itself repeatedly.
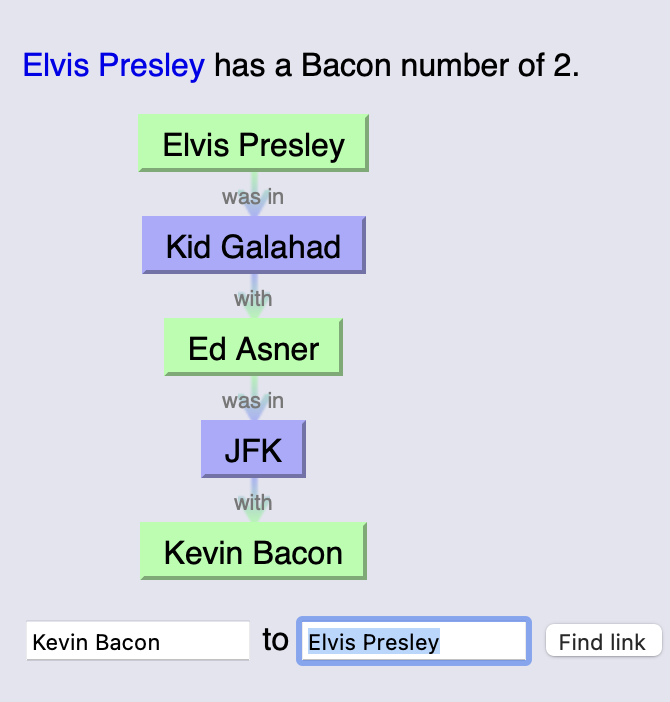
For example, consider the network of movie actors: two actors are connected if they appear in the same movie.
Thus we have the phenomenon of the six degrees of Kevin Bacon.
Because movie co-appearance forms a small world network, most any path between two actors is a short one.
Implications of Small Worlds
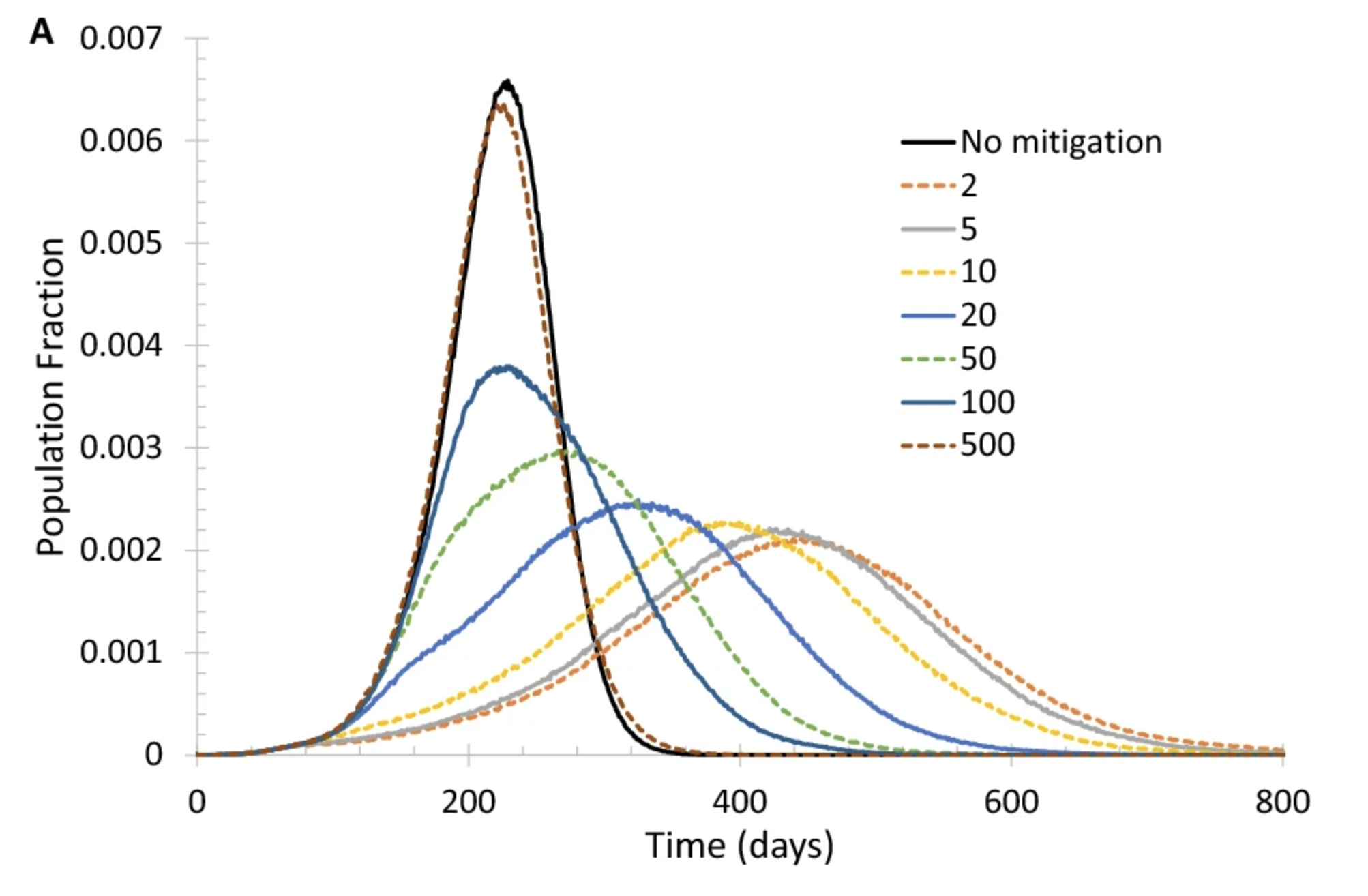
Viruses spread rapidly in small worlds.
One of the goals of pandemic lock-downs is to prevent people circulating outside of their local social groups. This is an attempt to eliminate the effect of long-range (weak-tie) connections.
This is the idea behind travel bans and mandatory quarantining after travel.
Here is a figure showing the effect on virus propagation of deleting most of the long-range edges from a small-world network. Different curves correspond to when the lock-down is deployed.
Another question concerns how shortcuts arise. Recall that node degree distributions typically follow a power-law.
Despite most people have small acquaintance sets, a small subset of people are very highly connected.
These high social capital individuals play a big role in creating long-range, path-shortening connections in social networks.
Analyzing Graphs
We have seen different strategies to characterize a graph. To perform further analysis we will employ the following strategies:
visualize the network in a way that communicates as much insight as possible, and
compute important metrics of the network.
Visualizing Networks
As an example, we’ll consider the following network, which records American football games between NCAA Division IA colleges in the Fall of 2000 (available here).
Each vertex represents a football team, which belongs to a specific conference (Big Ten, Conference USA, Pac-10, etc.).
An edge between two vertices \(v_1\) and \(v_2\) means that the two teams played each other. The weight of the edge (\(v_1\), \(v_2\)) is equal to the number of times they played each other.
This data comes from M. Girvan and M. E. J. Newman, Community structure in social and biological networks, Proc. Natl. Acad. Sci. USA 99, 7821-7826 (2002).
football = nx.readwrite.gml.read_gml('data/football.gml')print(f'The football network has {len(football.nodes())} nodes and {len(football.edges())} edges')
The football network has 115 nodes and 613 edges
To get a sense of what is unusual here, we can compare this network to a \(G(n, p)\) random network with the same number of nodes and edges.
n =len(football.nodes())e =len(football.edges())p = e / ((n * (n-1))/2)F_random = nx.erdos_renyi_graph(n, p, seed =0)
One way to visualize is to use a circular layout, which keeps all the edges in the interior.
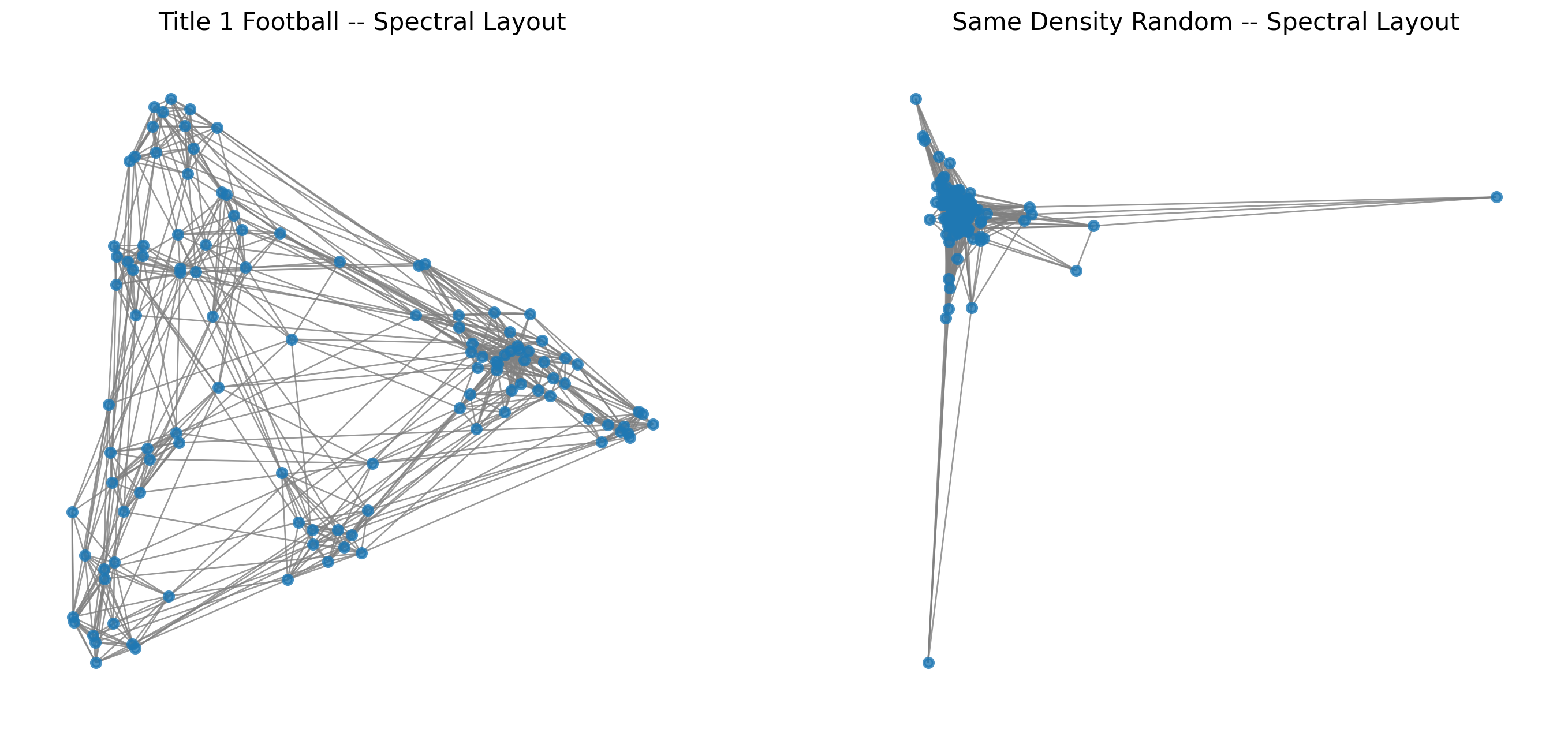
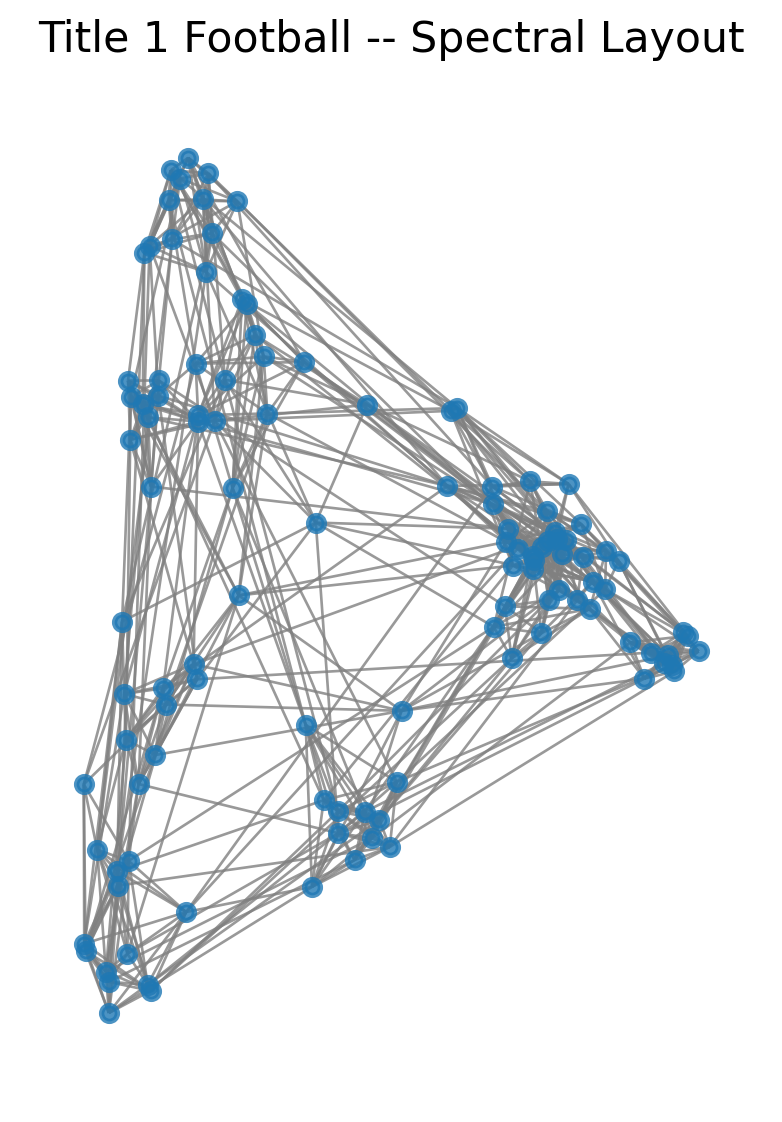
There is some non-random structure here, but it’s not clear exactly what it is. To better investigate this network we will use a more informative layout.
The standard networkx routine uses what is called a spring layout.
Here is how the spring layout works.
Each edge has a weight parameter (could be 1 for all edges).
The layout routine fixes
a spring of length = 1/weight between the nodes,
a repulsive force between each pair of nodes,
and then lets the set of all forces reach its minimum energy state.
This is a kind of minimal distortion in a least-squares sense.
Spring Layout
Code
plt.figure(figsize = (12, 5.5))ax1 = plt.subplot(121)nx.draw_networkx(football, ax = ax1, node_size=35, edge_color='gray', pos = nx.spring_layout(football, seed =0), with_labels=False, alpha=.8, linewidths=2)plt.axis('off')plt.title('Title 1 Football -- Spring Layout', size =16)ax2 = plt.subplot(122)nx.draw_networkx(F_random, ax = ax2, node_size=35, edge_color='gray', pos = nx.spring_layout(F_random, seed =0), with_labels=False, alpha=.8, linewidths=2)plt.axis('off')plt.title('Same Density Random -- Spring Layout', size =16)plt.show()
Notice how the spring layout tends to bring clusters of densely connected nodes close to each other.
Spectral Layout
Finally, we can try the spectral layout. We will define the spectral layout in the next lecture.
Another way to understand network structured data is to look at important metrics.
For example, we can start with the clustering coefficient:
Code
clustering_coefficient = nx.average_clustering(football)print(f'The clustering coefficient of the Football network is {clustering_coefficient:0.3f}')cc_random = nx.average_clustering(F_random)print(f'The clustering coefficient for the equivalent random network is {cc_random:0.3f}')
The clustering coefficient of the Football network is 0.403
The clustering coefficient for the equivalent random network is 0.088
print(f'The diameter of the Football network is {nx.diameter(football)}'+f' and the average shortest path length is {nx.average_shortest_path_length(football):0.3f}')print(f'The diameter of the equivalent random network is {nx.diameter(F_random)}'+f' and the average shortest path length is {nx.average_shortest_path_length(F_random):0.3f}')
The diameter of the Football network is 4 and the average shortest path length is 2.508
The diameter of the equivalent random network is 4 and the average shortest path length is 2.215
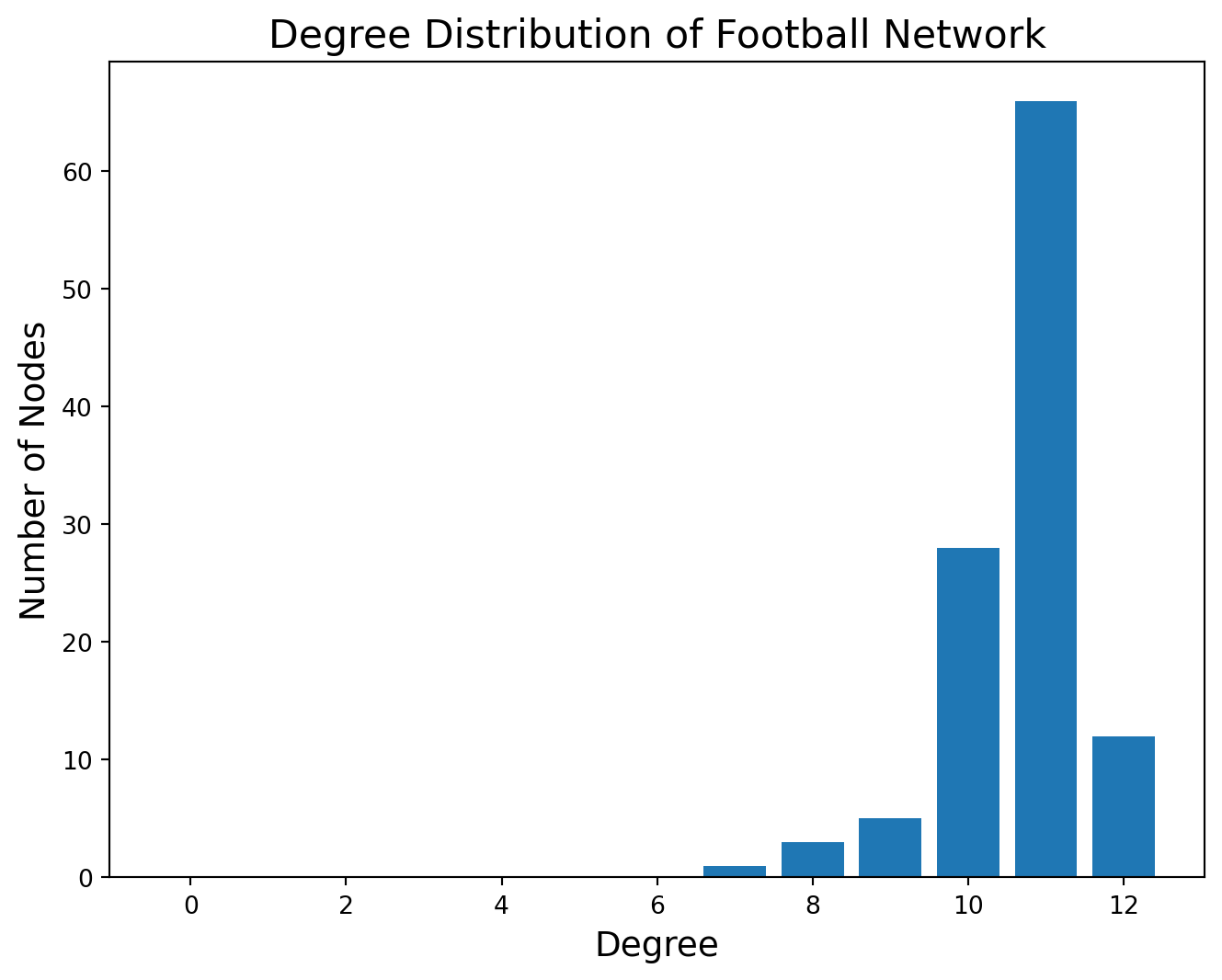
The next property we can look at is the degree distribution.
plt.figure(figsize = (8, 6))plt.bar(degrees, degree_freq)plt.xlabel('Degree', size =14)plt.ylabel('Number of Nodes', size =14)plt.title('Degree Distribution of Football Network', size =16)plt.show()
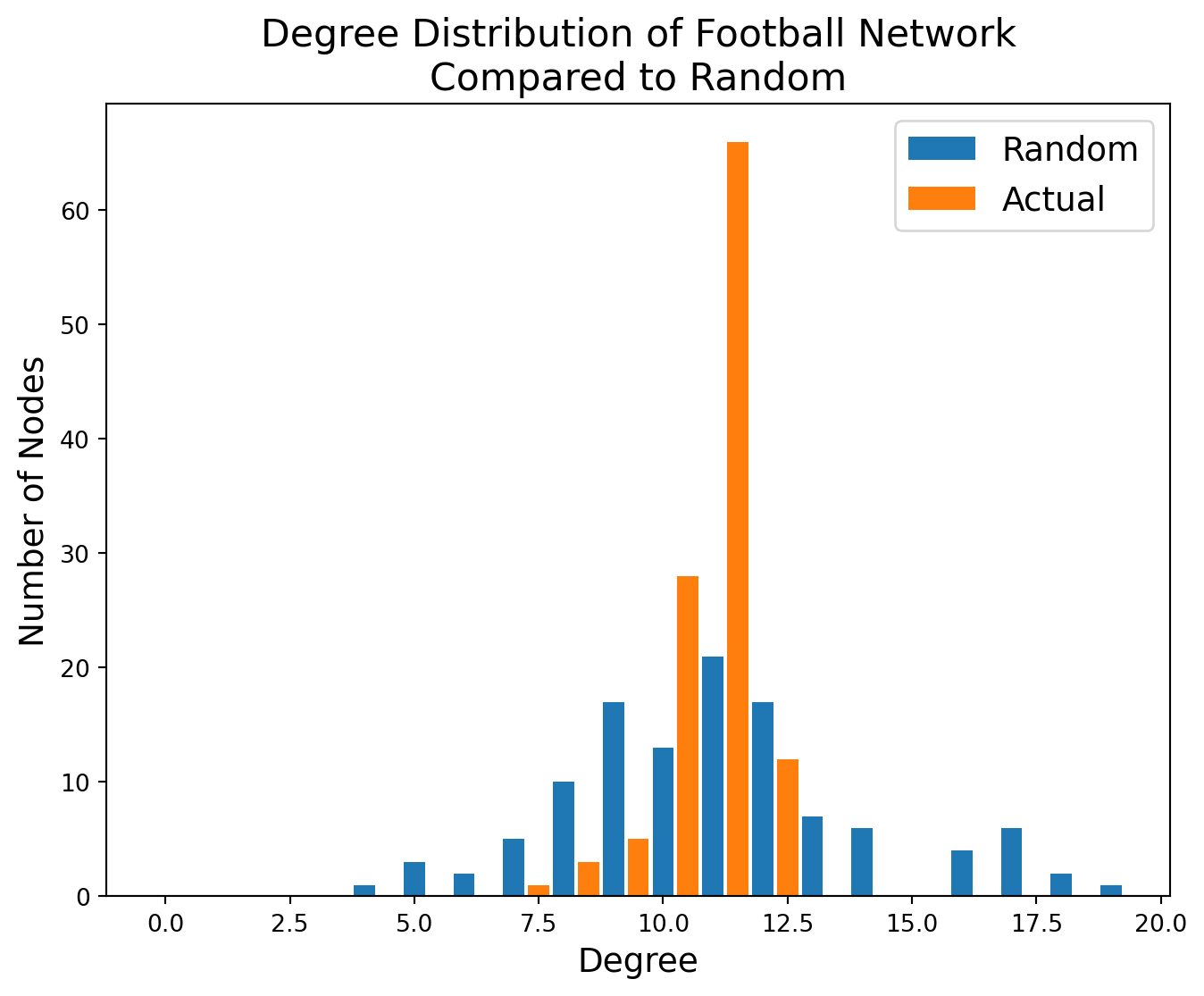
To get a sense of what is unusual here, we can again compare this to the equivalent random network.
Code
rand_degree_freq = nx.degree_histogram(F_random)rand_degrees =range(len(rand_degree_freq))plt.figure(figsize = (8, 6))plt.bar(rand_degrees, rand_degree_freq, 0.425, label ='Random')plt.bar(degrees+0.5, degree_freq, 0.425, label ='Actual')plt.xlabel('Degree', size =14)plt.ylabel('Number of Nodes', size =14)plt.legend(loc ='best', fontsize =14)plt.title('Degree Distribution of Football Network\nCompared to Random', size =16)plt.show()
We can see the evidence of scheduling of games in this distribution: a much larger number of teams plays 11 games than would occur by chance.