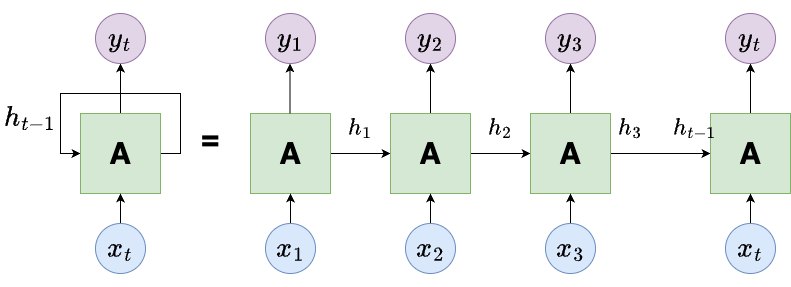
We introduce recurrent neural networks (RNNs) which is a neural network architecture used for machine learning on sequential data.
What are RNNs?
A type of artificial neural network designed for processing sequences of data.
Unlike traditional neural networks, RNNs have connections that form directed cycles, allowing information to persist.
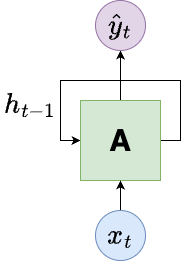
The above figure shows an RNN architecture. The block \(A\) can be viewed as one stage of the RNN. \(A\) accepts as input \(x_t\) and outputs a value \(\hat{y}_t\). The loop with the hidden state \(h_{t-1}\) illustrates how information passes from one step of the network to the next.
Why Use RNNs?
Sequential Data: Ideal for tasks where data points are dependent on previous ones.
Memory: Capable of retaining information from previous inputs, making them powerful for tasks involving context. This is achieved from hidden states and feedback loops.
RNN Applications
Natural Language Processing (NLP): Language translation, sentiment analysis, and text generation.
Speech Recognition: Converting spoken language into text.
Time Series Prediction: Forecasting stock prices, weather, and other temporal data.
Music Generation: Creating a sequence of musical notes.
Outline
Basic RNN Architecture
LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Units)
Examples
RNN Architecture
Forward Propagation
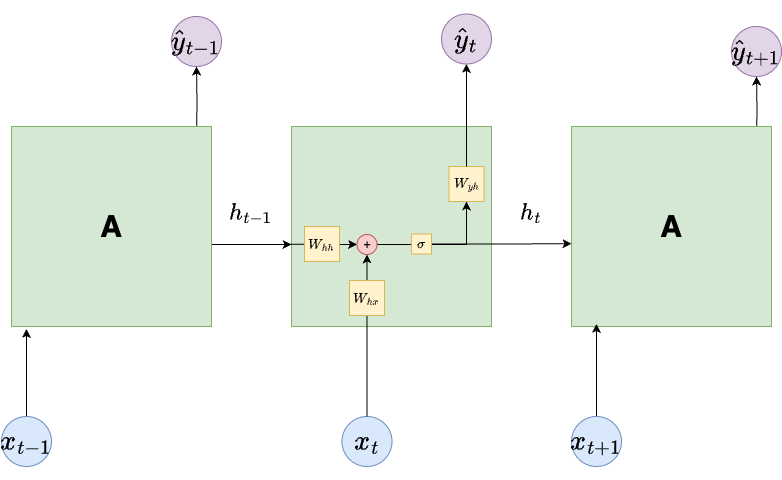
The forward pass in the RNN architecture is given by the following operations
\(h_t = g_h(W_{hh} h_{t-1} + W_{hx} x_t + b_h)\)
\(\hat{y}_t = g_y(W_{yh} h_t + b_y)\)
The vector \(x_t\) is the \(t\)-th element of the input sequence. The vector \(h_t\) is the hidden state at the \(t\)-th point of the sequence. The dimension of \(h_t\) is a hyperparameter of the RNN.
The vector \(\hat{y}_t\) is the \(t\)-th output of the sequence. The functions \(g_h\) and \(g_y\) are nonlinear activation functions.
The weight matrices \(W_{hh}\), \(W_{hx}\), \(W_{yh}\), and biases \(b_h\), \(b_y\) are trainable parameters that are reused in each time step. Note that we must define the vector \(h_0\). A common choice is \(h_0 = 0\).
RNN Cell
Model Types
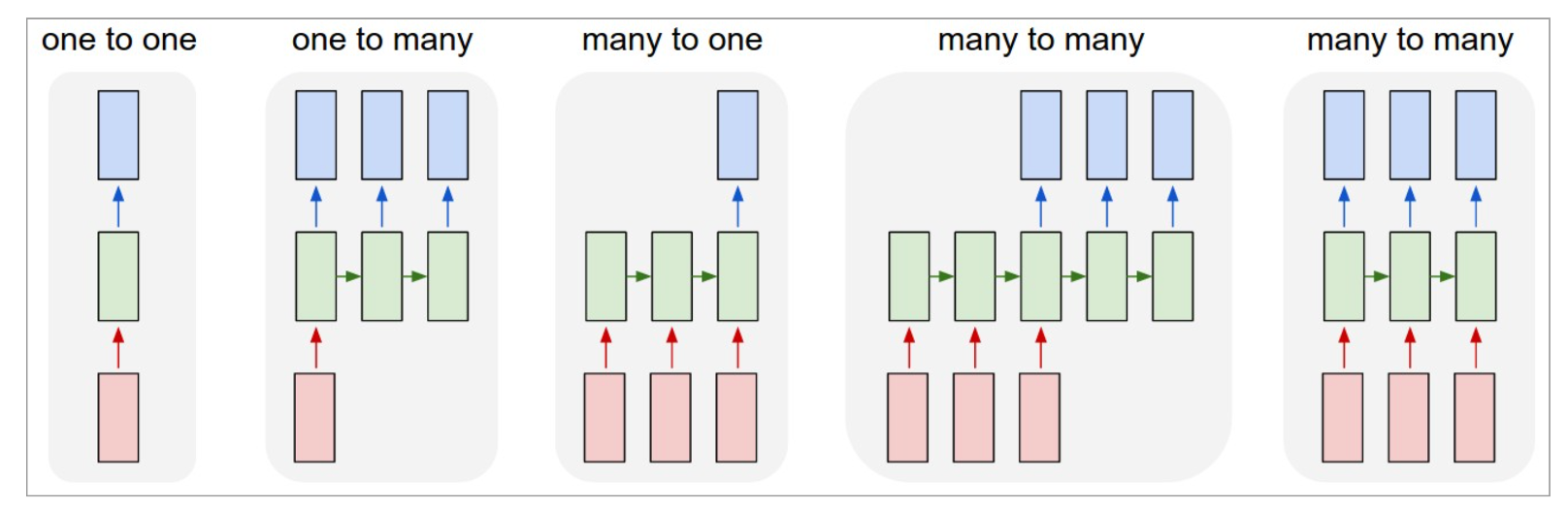
Depending on the application there many be varying number of outputs \(\hat{y}_t\). The figure below illustrates how the architecture can change.
One-to-one, is a regular feed forward neural network.
One-to-many, e.g., image captioning (1 image and output a sequence of words).
Many-to-one, e.g., sentiment analysis from a sequence of words or stock price prediction.
Many-to-many, e.g., machine translation or video frame-by-frame action classification.
Our subsequent illustrations of RNNs all display many-to-many architectures.
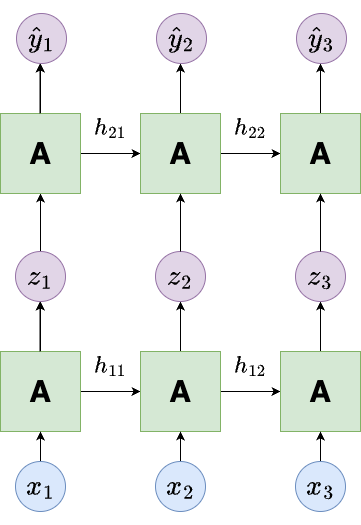
Stacked RNNs
It is also possible to stack multiple RNNs on top of each other. This is illustrated in the figure below.
Each layer has its own set of weights and biases.
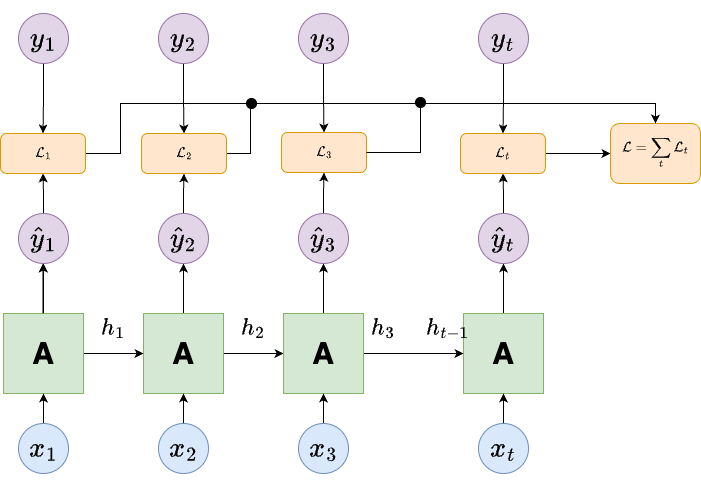
Loss Calculation for Sequential Data
For each prediction in the sequence \(\hat{y}_t\) and corresponding true value \(y_t\) we calculate the loss \(\mathcal{L}_t(y_t, \hat{y}_t)\).
The total loss is the sum of all the individual losses, \(\mathcal{L} = \sum_t \mathcal{L}_t\). This is illustrated in the figure above.
For categorical data we use cross-entropy loss \(\mathcal{L}_t(y_t, \hat{y}_t) = -y_t\log(\hat{y}_t)\).
For continuous data we would use a mean-square error loss.
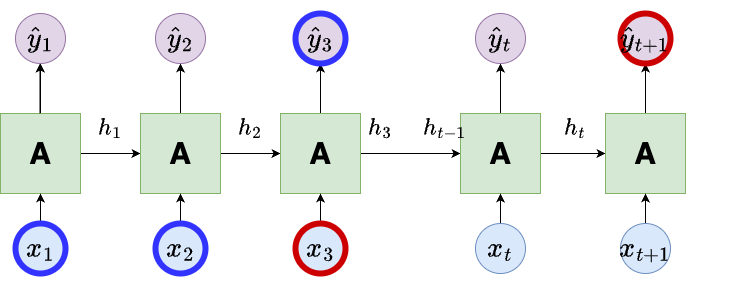
Vanishing Gradients
The key idea of RNNs is that earlier items in the sequence influence the more recent outputs. This is highlighted in blue in the figure below.
However, for longer sequences the influence can be significantly reduced. This is illustrated in red in the figure below.
Due to the potential for long sequences of data, during training you are likely to encounter small gradients. As a result, RNNs are prone to vanishing gradients.
RNN Limitations
Vanishing Gradients:
During training, gradients can become very small (vanish), making it difficult for the network to learn long-term dependencies.
Long-Term Dependencies:
RNNs struggle to capture dependencies that are far apart in the sequence, leading to poor performance on tasks requiring long-term memory.
Difficulty in Parallelization:
The sequential processing of data in RNNs makes it challenging to parallelize training, leading to slower training times.
Limited Context:
Standard RNNs have a limited ability to remember context over long sequences, which can affect their performance on complex tasks.
Bottleneck Problem:
The hidden state is all that carries forward history and it can be a bottleneck in how expressive it can be.
Addressing RNN Limitations
Some proposed solutions for mitigating the previous issues are
LSTM (Long Short-Term Memory)
GRU (Gated Recurrent Units)
These are more advanced variants of RNNs designed to address some of these limitations by improving the ability to capture long-term dependencies and addressing gradient issues.
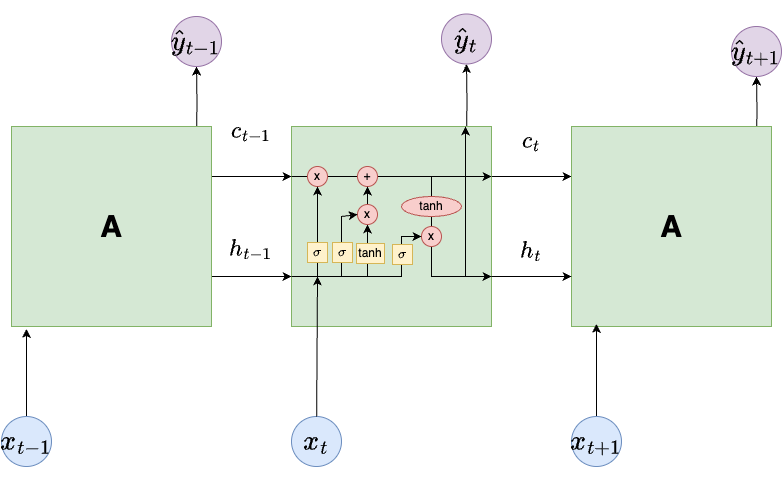
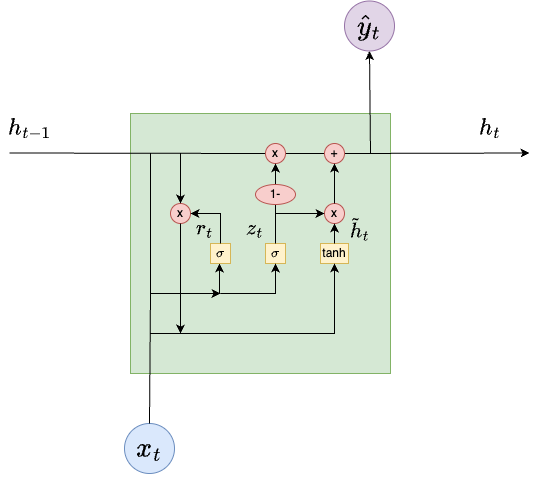
LSTM
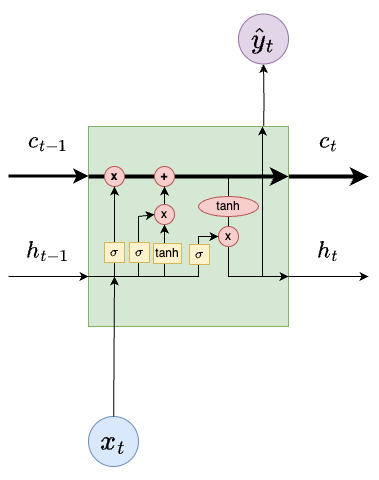
Below is an illustration of the LSTM architecture.
The new components are:
The input cell state \(c_{t-1}\) and output cell state \(c_{t}\).
Yellow blocks consisting of neural network layers with sigmoid \(\sigma\) or tanh activation functions.
Red circles indicating point-wise operations.
Cell State
The cell state \(c_{t-1}\) is the input to the LSTM block.
This value then moves through the LSTM block.
It is modified by either a multiplication or addition interaction.
After these operations, the modified cell state is \(c_{t}\) is sent to the next LSTM block. In addition, \(c_t\) is added to the hidden state after tanh activation.
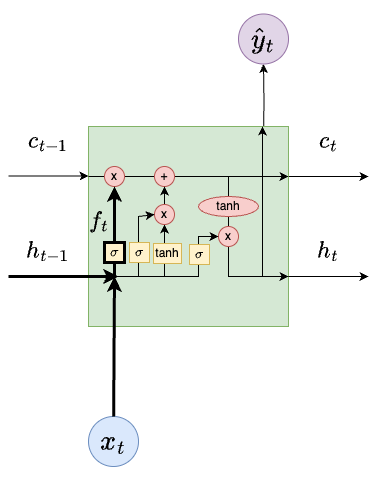
Forget Gate Layer
The forget layer computes a value
\[
f_t = \sigma(W_f[h_{t-1}, x_t] + b_f),
\]
where \(\sigma(x) = \frac{1}{1 + e^{-x}}\) is the sigmoid function.
The output \(f_t\) is a vector of numbers between 0 and 1. These values multiply the corresponding vector values in \(c_{t-1}\).
A value of 0 says throw that component of \(c_{t-1}\) away. A value of 1 says keep that component of \(c_{t-1}\).
This operation tells us which old information in the cell state we should keep or remove.
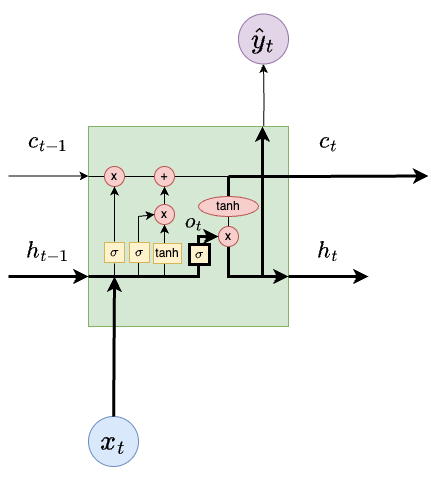
The vector \(o_t\) from the sigmoid layer tells us what parts of the cell state we use for output. The output is a filtered version of the hyperbolic tangent of cell state \(c_t\).
The output of the block is \(\hat{y}_t\). It is the same as the hidden state \(h_t\) that is sent to the \(t+1\) LSTM block.
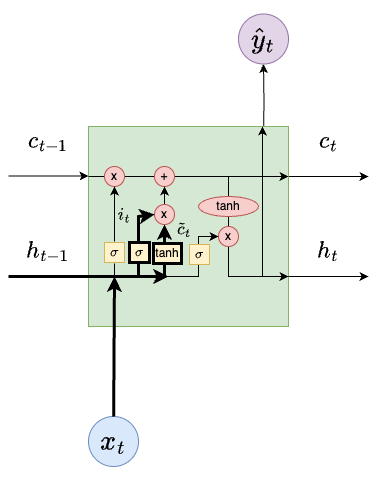
Weight Summary
For the LSTM architecture, we have the following sets of weights
\(W_f\) and \(b_f\) (forget layer),
\(W_i, W_c\) and \(b_i, b_c\) (input gate layer),
\(W_o\) and \(b_0\) (output layer).
Advantages of LSTMs
Long-term Dependencies: LSTMs can capture long-term dependencies in sequential data, making them effective for tasks like language modeling and time series prediction.
Avoiding Vanishing Gradient: The architecture of LSTMs helps mitigate the vanishing gradient problem, which is common in traditional RNNs.
Flexibility: LSTMs can handle variable-length sequences and are versatile for different types of sequential data.
Memory: They have a memory cell that can maintain information over long periods, which is crucial for tasks requiring context retention.
Disadvantages of LSTMs
Complexity: LSTMs are more complex than simpler models like traditional RNNs, leading to longer training times and higher computational costs.
Overfitting: Due to their complexity, LSTMs are prone to overfitting, especially with small datasets.
Resource Intensive: They require more computational resources and memory, which can be a limitation for large-scale applications.
Hyperparameter Tuning: LSTMs have many hyperparameters that need careful tuning, which can be time-consuming and challenging.
Bottleneck Problem: The hidden and cell states are all that carries forward history and they can be a bottleneck in how expressive it can be.
GRU
A variant of the LSTM architecture is the Gated Recurrence Unit.
It combines the forget and input gates into a single update gate. It also combines the cell-state and hidden state. The operations that are now performed are given below:
Simpler Architecture: GRUs have a simpler architecture compared to LSTMs, with fewer gates, making them easier to implement and train.
Faster Training: Due to their simpler structure, GRUs often train faster and require less computational power than LSTMs.
Effective Performance: GRUs can perform comparably to LSTMs on many tasks, especially when dealing with shorter sequences.
Less Prone to Overfitting: With fewer parameters, GRUs are generally less prone to overfitting compared to LSTMs.
Disadvantages of GRUs
Less Expressive Power: The simpler architecture of GRUs might not capture complex patterns in data as effectively as LSTMs.
Limited Long-term Dependencies: GRUs might struggle with very long-term dependencies in sequential data compared to LSTMs.
Less Flexibility: GRUs offer less flexibility in terms of controlling the flow of information through the network.
Bottleneck Problem: Like vanilaa RNNs, the hidden state is all that carries forward history and can be a bottleneck in how expressive it can be.
RNN Examples
Appliance Energy Prediction
In this example we will use a dataset containing the energy usage in Watt hours (Wh) of appliances in a low energy building.
Another example of Time Series Analysis.
In addition to the appliance energy information, the dataset includes the house temperature and humidity conditions. We will build an LSTM model that predicts the energy usage of the appliances.
Load the Data
The code cells below load the dataset.
import osfile_path ='energydata_complete.csv'url ="https://archive.ics.uci.edu/ml/machine-learning-databases/00374/energydata_complete.csv"if os.path.exists(file_path): data = pd.read_csv(file_path)else: data = pd.read_csv(url) data.to_csv(file_path, index=False)data.head()
date
Appliances
lights
T1
RH_1
T2
RH_2
T3
RH_3
T4
...
T9
RH_9
T_out
Press_mm_hg
RH_out
Windspeed
Visibility
Tdewpoint
rv1
rv2
0
2016-01-11 17:00:00
60
30
19.89
47.596667
19.2
44.790000
19.79
44.730000
19.000000
...
17.033333
45.53
6.600000
733.5
92.0
7.000000
63.000000
5.3
13.275433
13.275433
1
2016-01-11 17:10:00
60
30
19.89
46.693333
19.2
44.722500
19.79
44.790000
19.000000
...
17.066667
45.56
6.483333
733.6
92.0
6.666667
59.166667
5.2
18.606195
18.606195
2
2016-01-11 17:20:00
50
30
19.89
46.300000
19.2
44.626667
19.79
44.933333
18.926667
...
17.000000
45.50
6.366667
733.7
92.0
6.333333
55.333333
5.1
28.642668
28.642668
3
2016-01-11 17:30:00
50
40
19.89
46.066667
19.2
44.590000
19.79
45.000000
18.890000
...
17.000000
45.40
6.250000
733.8
92.0
6.000000
51.500000
5.0
45.410389
45.410389
4
2016-01-11 17:40:00
60
40
19.89
46.333333
19.2
44.530000
19.79
45.000000
18.890000
...
17.000000
45.40
6.133333
733.9
92.0
5.666667
47.666667
4.9
10.084097
10.084097
5 rows × 29 columns
Resample Data
We’re interested in the Appliances column, which is the energy use of the appliances in Wh.
First, we’ll resample the data to hourly resolution and fill missing values using the forward fill method.
Code
data['date'] = pd.to_datetime(data['date'])data.set_index('date', inplace=True)data = data['Appliances'].resample('h').mean().ffill() # Resample and fill missingdata.head()
We create train-test splits and scale the data accordingly.
In addition, we create our own dataset class. In this class we create lagged sequences of the energy usage data. The amount of lag, or look-back sequence length, is set to 24.
We define our LSTM architecture in the code cell below.
# Define the LSTM modelclass LSTMModel(nn.Module):def__init__(self, input_size=1, hidden_size=16, output_size=1):super(LSTMModel, self).__init__()self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x): x, _ =self.lstm(x) x =self.fc(x[:, -1, :]) # Use the output of the last time stepreturn xmodel = LSTMModel()print(model)
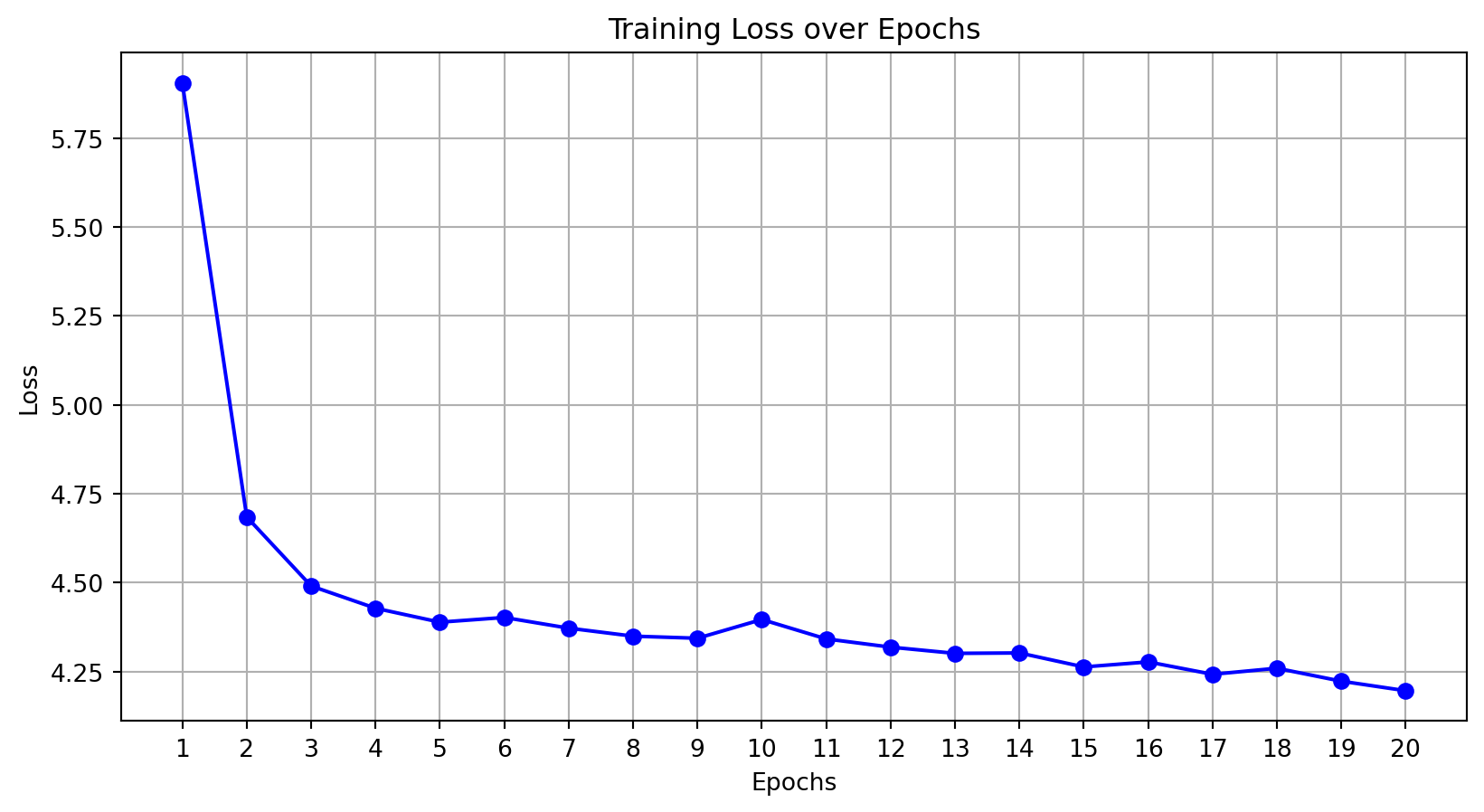
We use a mean-square error loss function and the Adams optimizer. We train the model for 20 epochs. We display the decrease in the loss during training. Based on the plot, did the optimizer converge?
Code
# Set criterion and optimizercriterion = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.001)epochs =20train_losses = []for epoch inrange(epochs): model.train() train_loss =0.0for X, y in train_loader: optimizer.zero_grad() outputs = model(X) loss = criterion(outputs, y) loss.backward() optimizer.step() train_loss += loss.item() train_losses.append(train_loss)# Plot the training losses over epochsplt.figure(figsize=(10, 5))plt.plot(range(1, epochs +1), train_losses, marker='o', linestyle='-', color='b')plt.title('Training Loss over Epochs')plt.xlabel('Epochs')plt.ylabel('Loss')plt.xticks(range(1, epochs +1)) # Set x-tick marks to be integersplt.grid(True)plt.show()
Evaluation
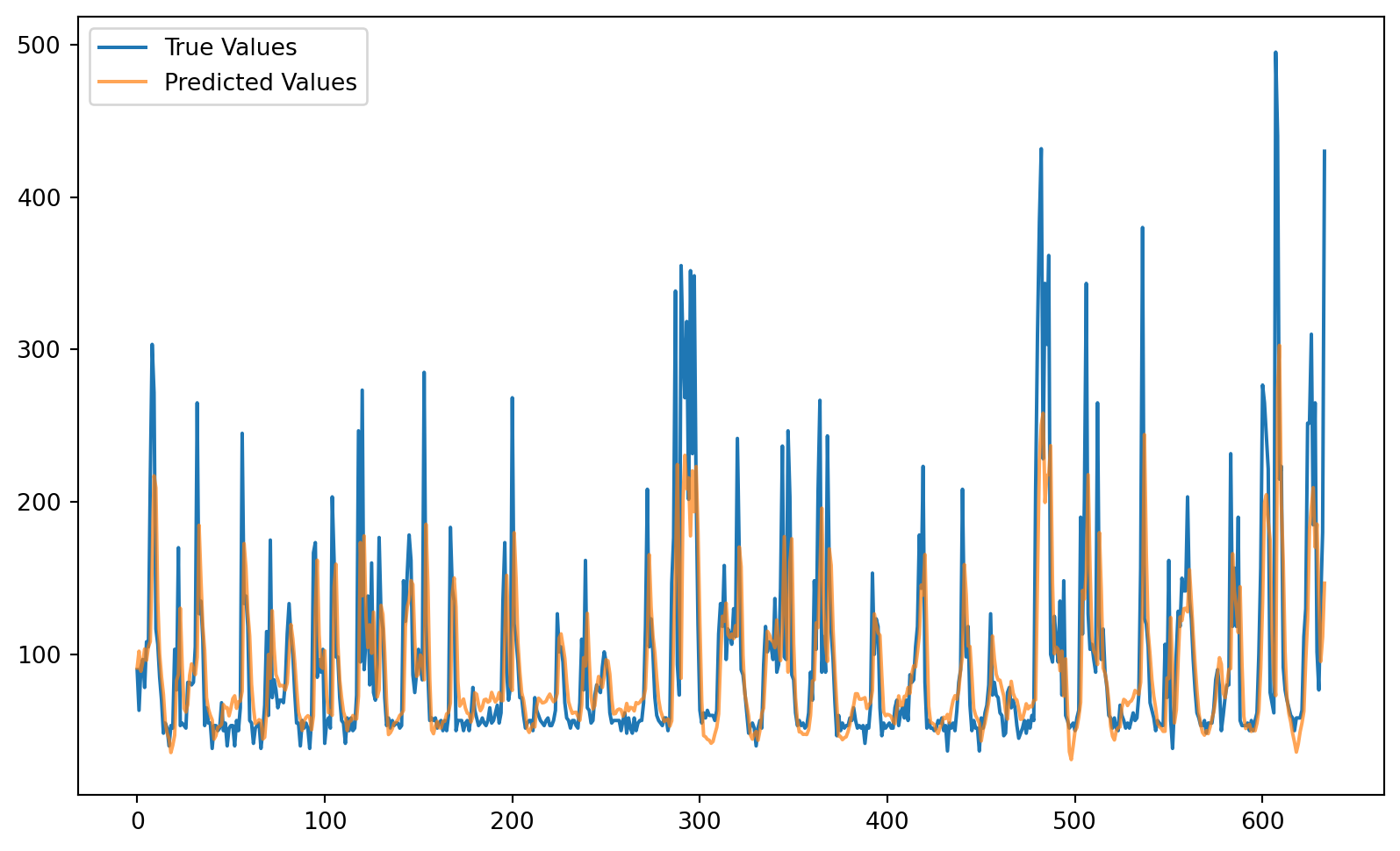
We’ll evaluate the model’s performance by plotting the predicted values from the test set on top of the actual test set values.
How did the model perform? Are there any obvious problems?
Code
# Evaluate the modelmodel.eval()predictions = []trues = []with torch.no_grad():for X, y in test_loader: preds = model(X) predictions.extend(preds.numpy()) trues.extend(y.numpy())# Rescale predictions and true to original scalepredictions_rescaled = scaler.inverse_transform(predictions)true_rescaled = scaler.inverse_transform(trues)# Plot resultsplt.figure(figsize=(10, 6))plt.plot(true_rescaled, label='True Values')plt.plot(predictions_rescaled, label='Predicted Values', alpha=0.7)plt.legend()plt.show()
Using the a 3-layer RNN with 512 hidden nodes on each layer, Karpathy trained a model on the complete works of Shakespeare. With this model he was able to generate texts similar to what is seen on the right.
Observe that there are some typos and the syntax is not perfect, but overall the style appears Shakespearean.
Wikipedia
Using a 100MB dataset of raw Wikipedia data, Karpathy trained RNNs which generated Wikipedia content. An example of the generated markdown is shown to the right.
The text is nonsense, but is structured like a Wikipedia post. Interestingly, the model hallucinated and fabricated a url that does not exist.
Baby Names
Using a list of 8000 baby names from this link, Karpathy trained an RNN to predict baby names.
To the right is a list of generated names not on the lists. More of the names can be found here.
Some interesting additional names the model generated were Baby, Char, Mars, Hi, and With.
Recap
We discussed the basic RNN architecture. We then discussed the LSTM and GRU modifications. These modifications allowed the RNNs to handle long-term dependencies.
We then considered an example application of energy consumption prediction.
We also discussed the unreasonable effectiveness of RNNs.
What’s Next?
As we saw, the RNN architecture has evolved to include LSTMs and GRUs. However, the RNN architecture also evolved to add attention. This was introduced by Bahdanau et al. (2014).
Attention in language models is a mechanism that allows the model to focus on relevant parts of the input sequence by assigning different weights to different words, enabling it to capture long-range dependencies and context more effectively.
In addition, recall that RNNs are only able to process data sequentially. For large scale natural language processing applications, this is a major computational bottleneck. This motivated the development of more advanced neural network architectures that could process sequential data in parallel and utilize attention.
The transformer architecture was introduced by Vaswani et al. (2017) and combines both of these desirable features.
Transformers form the basis for modern large language models (LLMs) and we will discuss them in our NLP lectures.
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. 2014. “Neural Machine Translation by Jointly Learning to Align and Translate.”arXiv Preprint arXiv:1409.0473. http://arxiv.org/abs/1409.0473.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, et al. 2017. “Attention Is All You Need.”Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017) (Long Beach, CA, USA), 11. https://arxiv.org/abs/1706.03762.