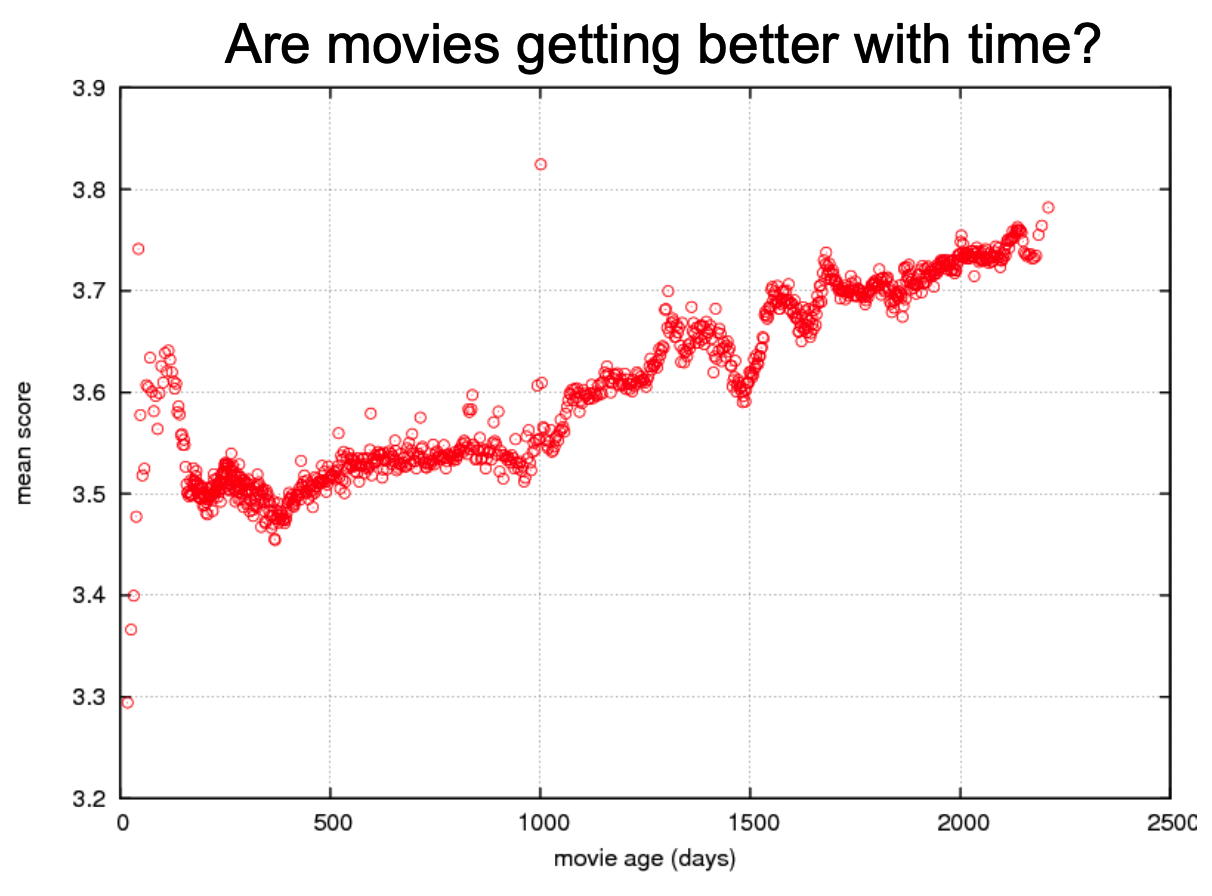
Collaborative Filtering with Temporal Dynamics, (Koren 2009)
Deep Learning Recommender Model for Personalization and Recommendation Systems, (Naumov et al. 2019)
What are Recommender Systems?
The concept of recommender systems emerged in the late 1990s / early 2000s as social life moved online:
online purchasing and commerce
online discussions and ratings
social information sharing
In these systems the amount of content was exploding and users were having a hard time finding things they were interested in.
Users wanted recommendations.
Over time, the problem has only gotten worse:
An enormous need has emerged for systems to help sort through products, services, and content items.
This often goes by the term personalization.
Some examples:
Movie recommendation (Netflix ~6.5K movies and shows, YouTube ~14B videos)
Related product recommendation (Amazon ~600M products)
Web page ranking (Google >>100B pages)
Social content filtering (Facebook, Twitter)
Services (Airbnb, Uber, TripAdvisor)
News content recommendation (Apple News)
Priority inbox & spam filtering (Gmail)
Online dating (Match.com)
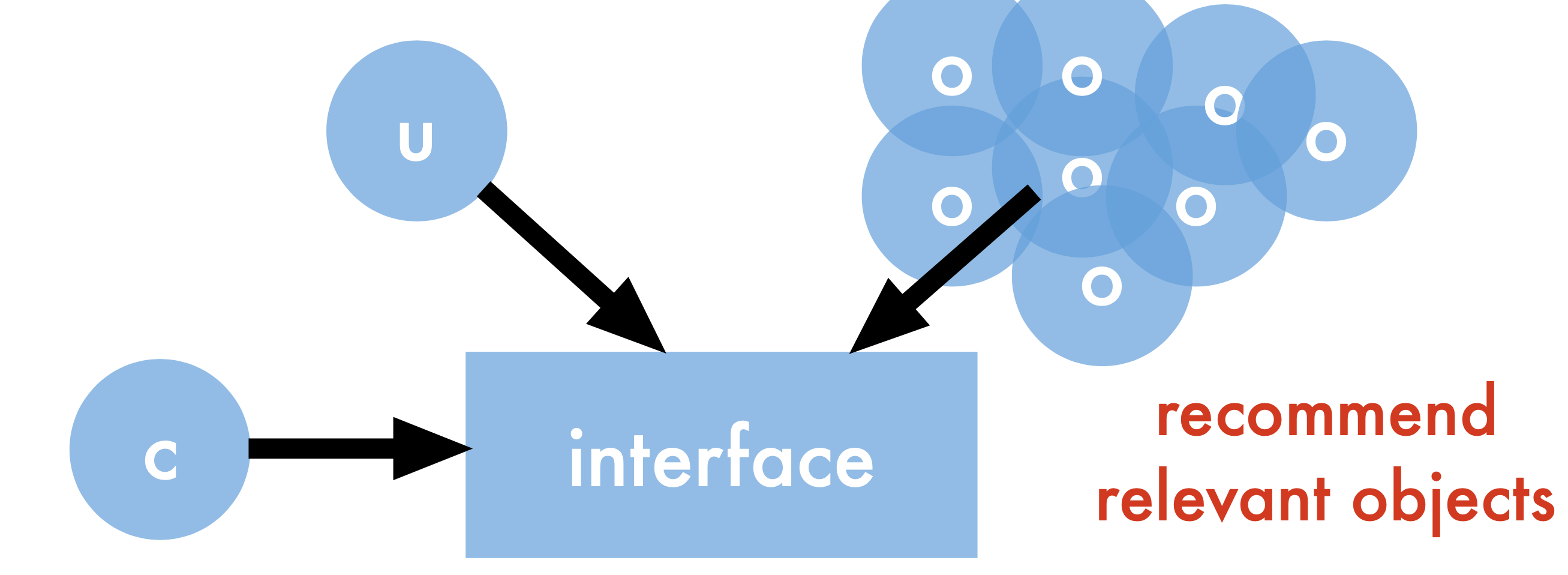
A more formal view:
User - requests content
Objects - instances of content
Context - device, location, time, history
Interface - browser, mobile
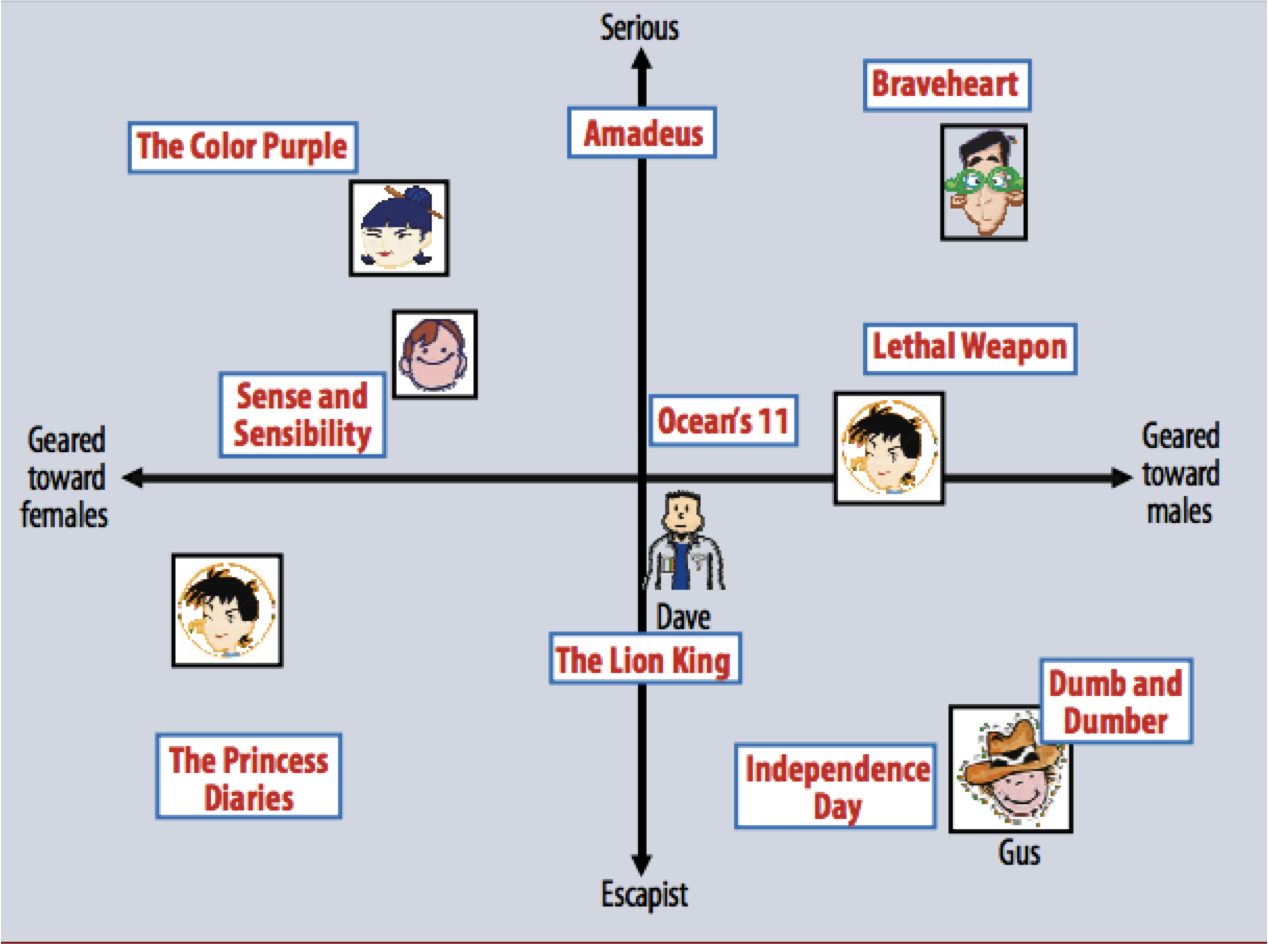
Inferring Preferences
Unfortunately, users generally have a hard time explaining what types of content they prefer.
Some early systems worked by interviewing users to ask what they liked. Those systems did not work very well.
A very interesting article about the earliest personalization systems is User Modeling via Stereotypes by Elaine Rich, dating from 1979.
Instead, modern systems work by capturing user’s opinions about specific items.
This can be done actively:
When a user is asked to rate a movie, product, or experience,
or it can be done passively:
By noting which items a user chooses to purchase (for example).
Challenges
The biggest issue is scalability: typical data for this problem is huge.
Millions of objects
100s of millions of users
Changing user base
Changing inventory (movies, stories, goods)
Available features
Imbalanced dataset
User activity / item reviews are power law distributed
This data is a subset of the data presented in: “From amateurs to connoisseurs: modeling the evolution of user expertise through online reviews,” by J. McAuley and J. Leskovec. WWW, 2013
Example
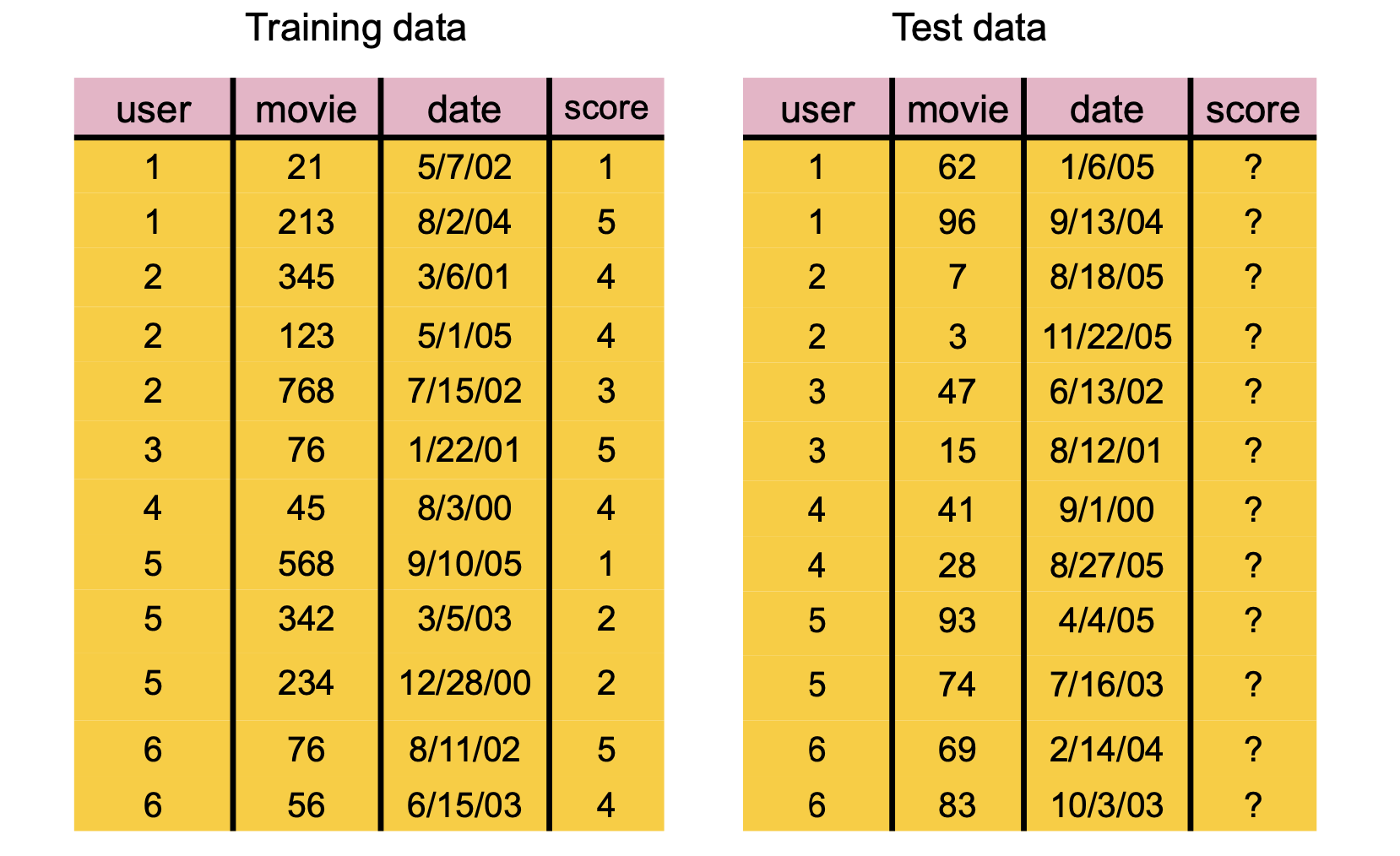
Let’s look at a dataset for testing recommender systems consisting of Amazon movie reviews:
We’ll download a compressed pickle file containing the data if it is not already present.
Code
# This is a 647 MB file, delete it after useimport gdownurl ="https://drive.google.com/uc?id=14GakA7oOjbQp7nxcGApI86WlP3GrYTZI"pickle_output ="train.pkl.gz"import os.pathifnot os.path.exists(pickle_output): gdown.download(url, pickle_output)
from IPython.display import display, Markdownn_users = df["UserId"].unique().shape[0]n_movies = df["ProductId"].unique().shape[0]n_reviews =len(df)display(Markdown(f'There are:\n'))display(Markdown(f'* {n_reviews:,} reviews\n* {n_movies:,} movies\n* {n_users:,} users'))display(Markdown(f'There are {n_users * n_movies:,} potential reviews, meaning sparsity of {(n_reviews/(n_users * n_movies)):0.4%}'))
There are:
1,697,533 reviews
50,052 movies
123,960 users
There are 6,204,445,920 potential reviews, meaning sparsity of 0.0274%
where
\[
\text{sparsity}
= \frac{\text{\# of reviews}}{\text{\# of users} \times \text{\# of movies}}
= \frac{\text{\# of reviews}}{\text{\# of potential reviews}}
\]
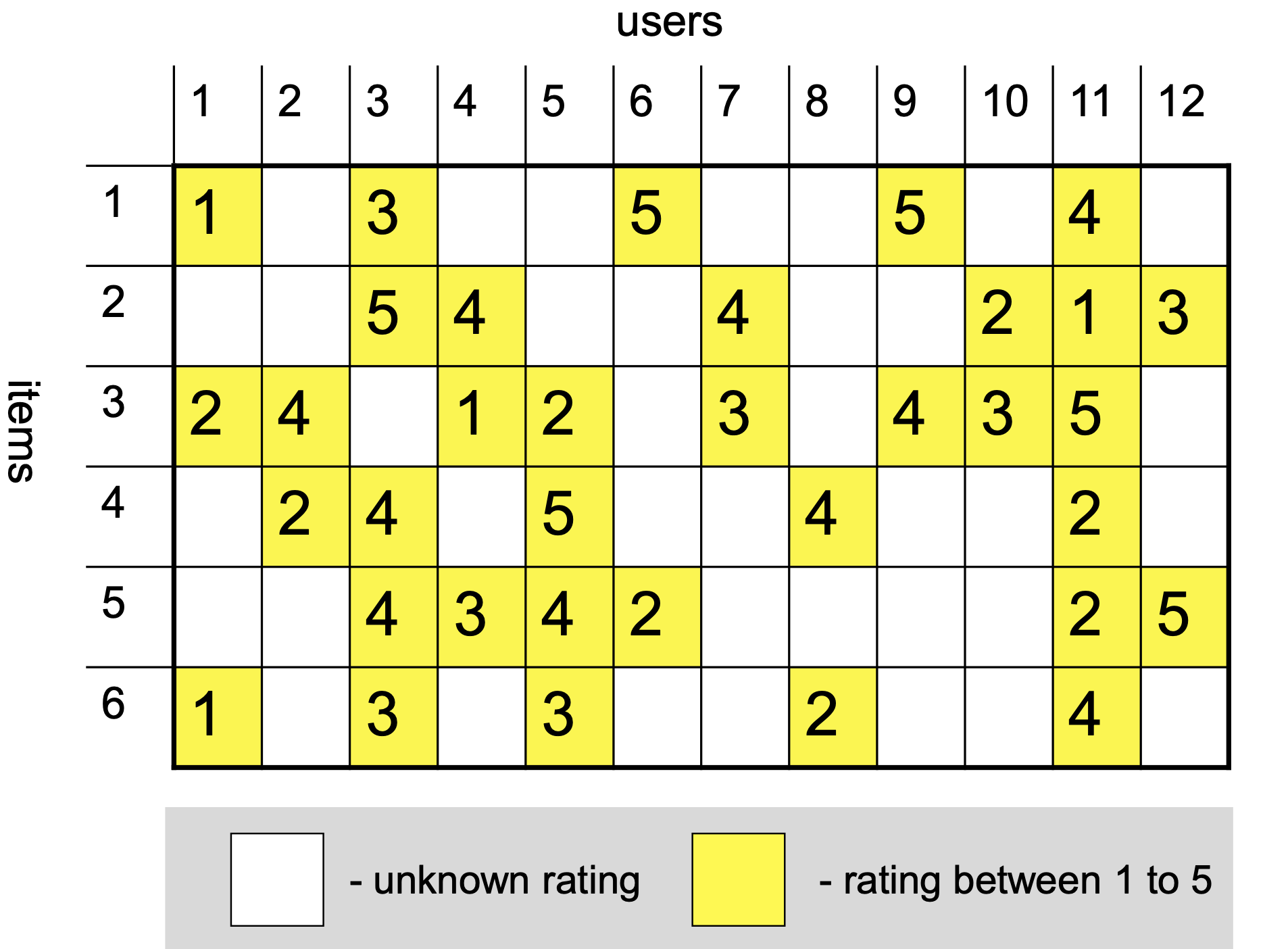
Reviews are Sparse
Only 0.02% of the reviews are available – 99.98% of the reviews are missing.
Code
display(Markdown(f'There are on average {n_reviews/n_movies:0.1f} reviews per movie'+f' and {n_reviews/n_users:0.1f} reviews per user'))
There are on average 33.9 reviews per movie and 13.7 reviews per user
Sparseness is Skewed
Although on average a movie receives 34 reviews, almost all movies have even fewer reviews.
Code
reviews_per_movie = df.groupby('ProductId').count()['Id'].valuesfrac_below_mean = np.sum(reviews_per_movie < (n_reviews/n_movies))/len(reviews_per_movie)plt.plot(sorted(reviews_per_movie, reverse=True), '.-')xmin, xmax, ymin, ymax = plt.axis()plt.hlines(n_reviews/n_movies, xmin, xmax, 'r', lw =3)plt.ylabel('Number of Ratings', fontsize =14)plt.xlabel('Movie', fontsize =14)plt.legend(['Number of Ratings', 'Average Number of Ratings'], fontsize =14)plt.title(f'Amazon Movie Reviews\nNumber of Ratings Per Movie\n'+f'{frac_below_mean:0.0%} of Movies Below Average', fontsize =16);
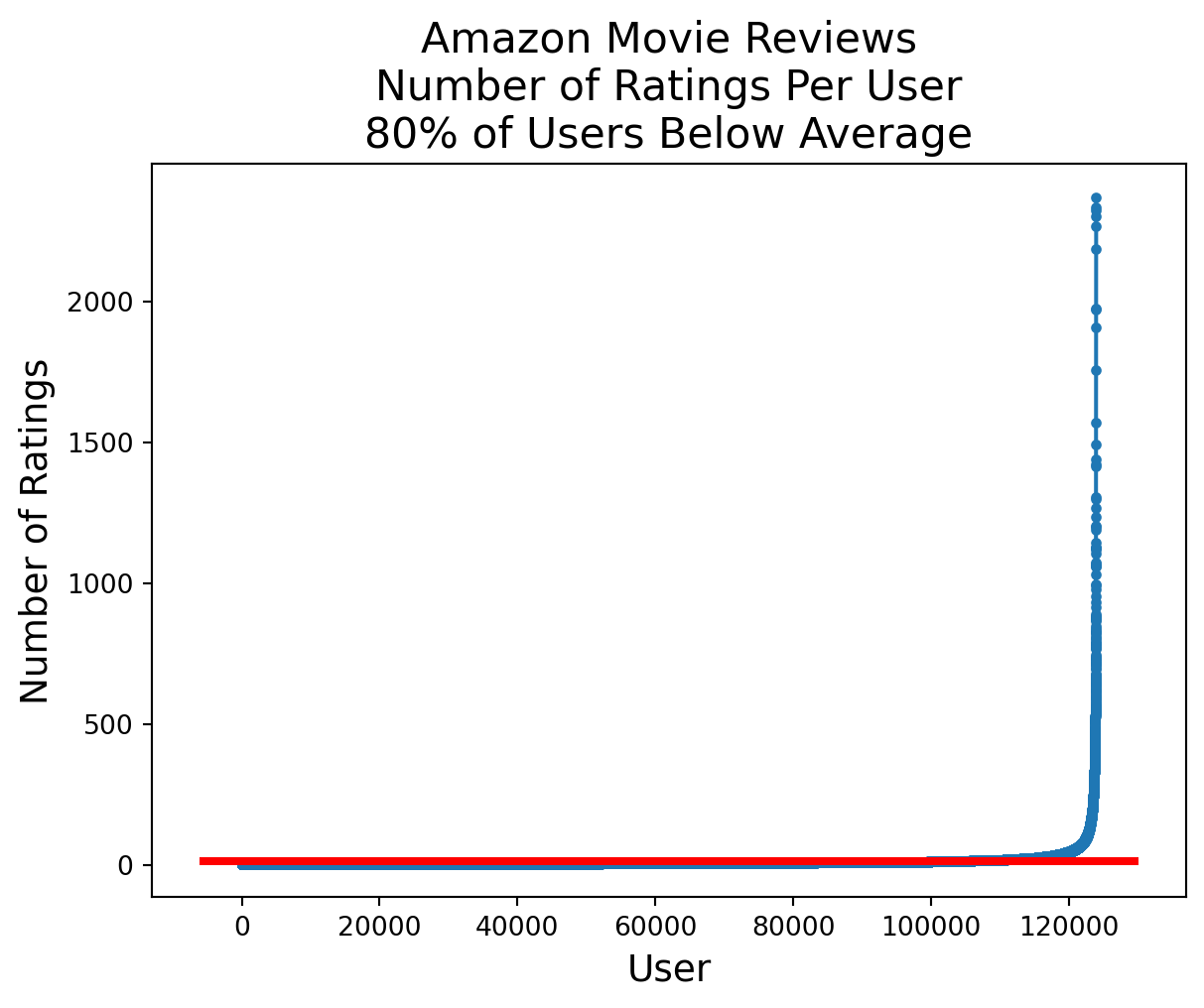
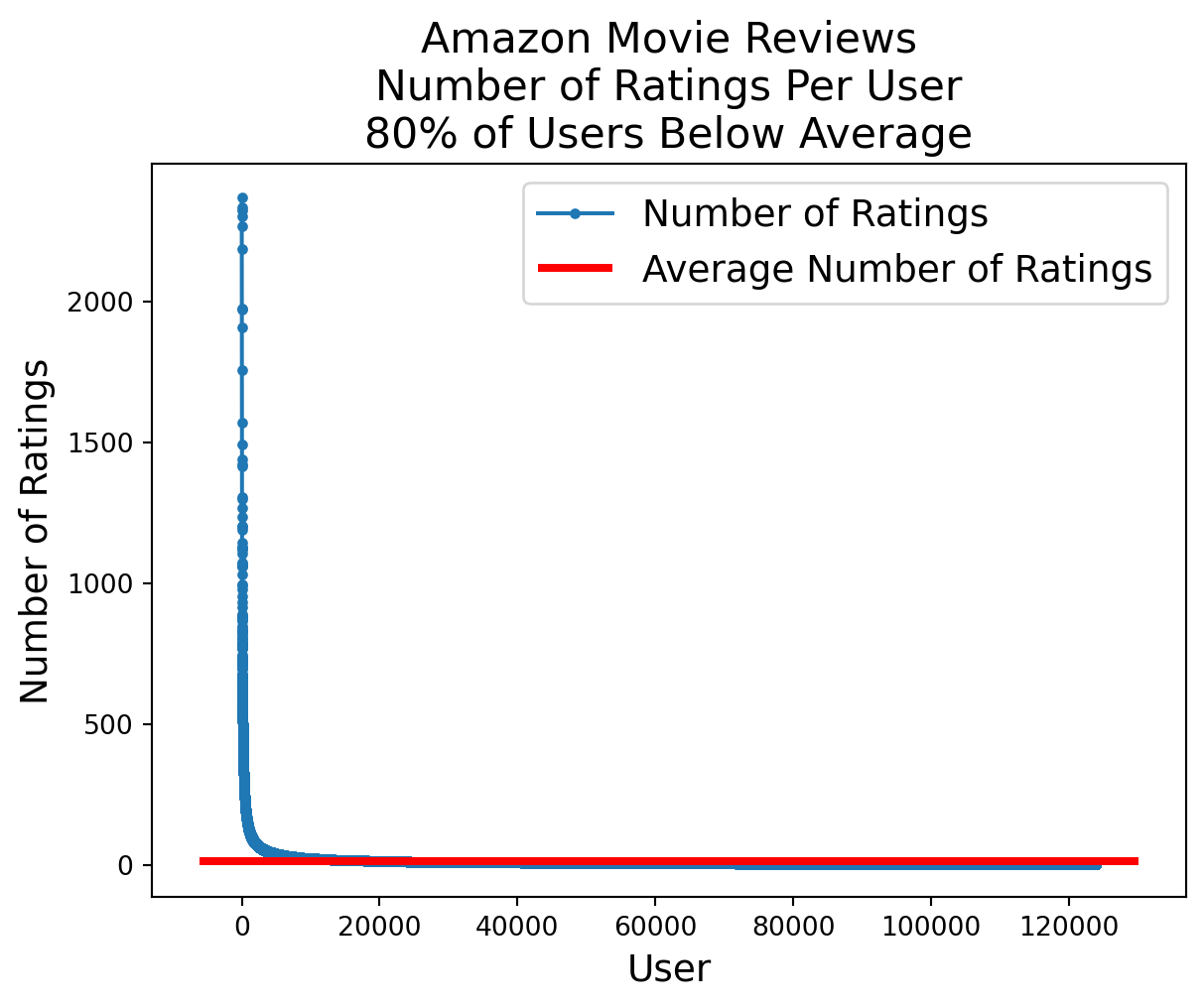
Likewise, although the average user writes 14 reviews, almost all users write even fewer reviews.
Code
reviews_per_user = df.groupby('UserId').count()['Id'].valuesfrac_below_mean = np.sum(reviews_per_user < (n_reviews/n_users))/len(reviews_per_user)plt.plot(sorted(reviews_per_user, reverse=True), '.-')xmin, xmax, ymin, ymax = plt.axis()plt.hlines(n_reviews/n_users, xmin, xmax, 'r', lw =3)plt.ylabel('Number of Ratings', fontsize =14)plt.xlabel('User', fontsize =14)plt.legend(['Number of Ratings', 'Average Number of Ratings'], fontsize =14)plt.title(f'Amazon Movie Reviews\nNumber of Ratings Per User\n'+f'{frac_below_mean:0.0%} of Users Below Average', fontsize =16);
Objective Function
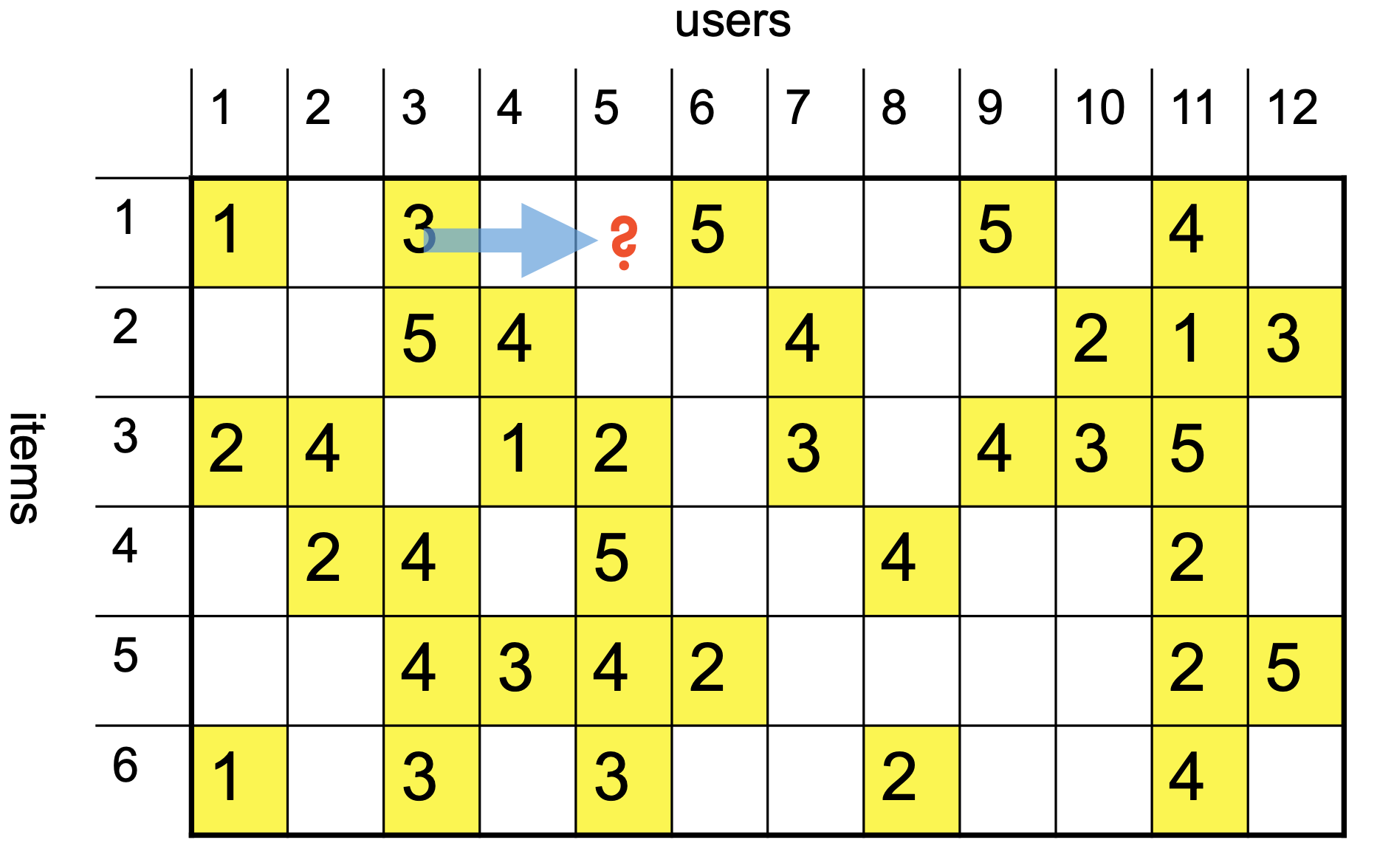
Ultimately, our goal is to predict the rating that a user would give to an item.
For that, we need to define a loss or objective function.
A typical objective function is root mean square error (RMSE)
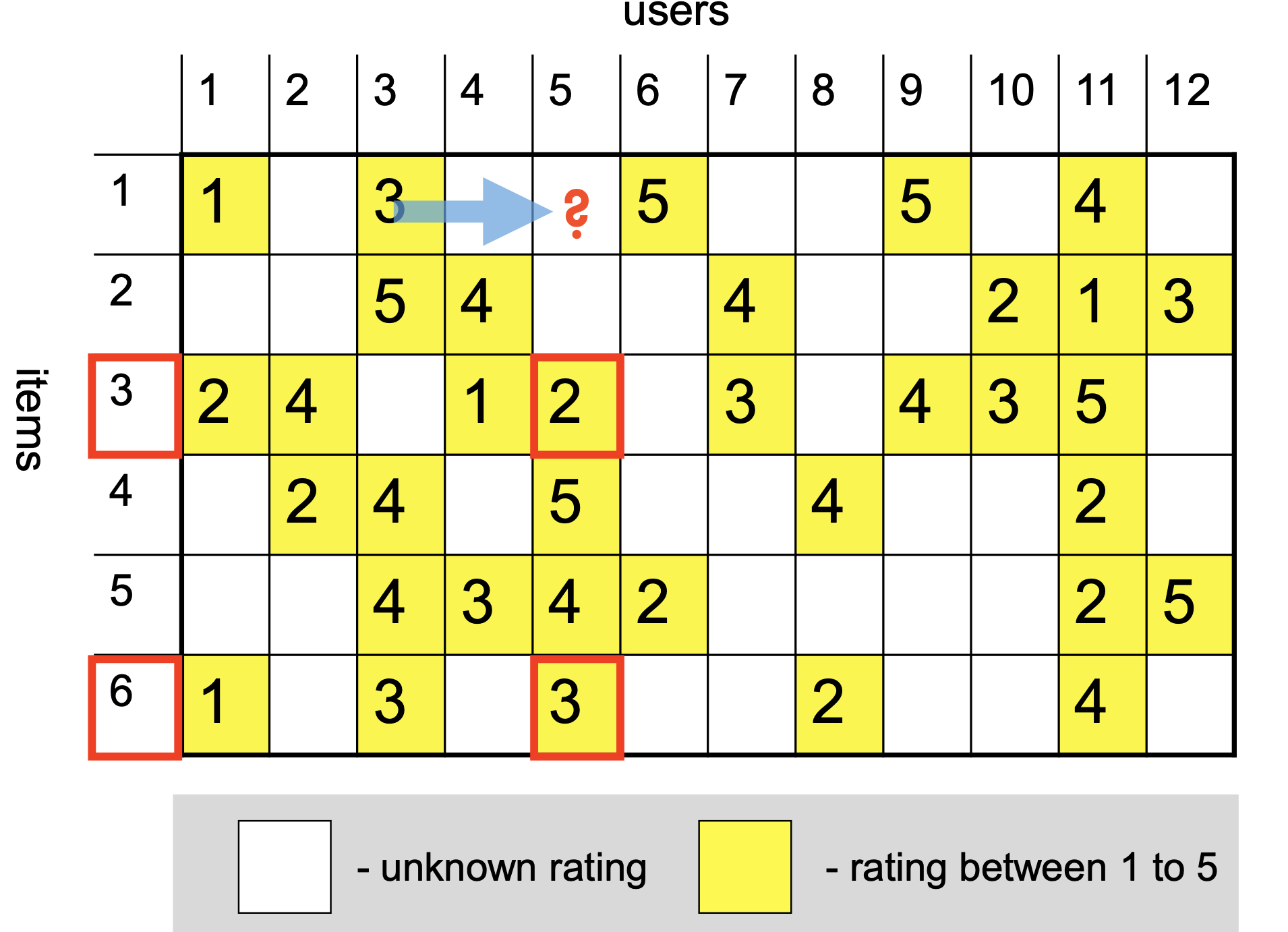
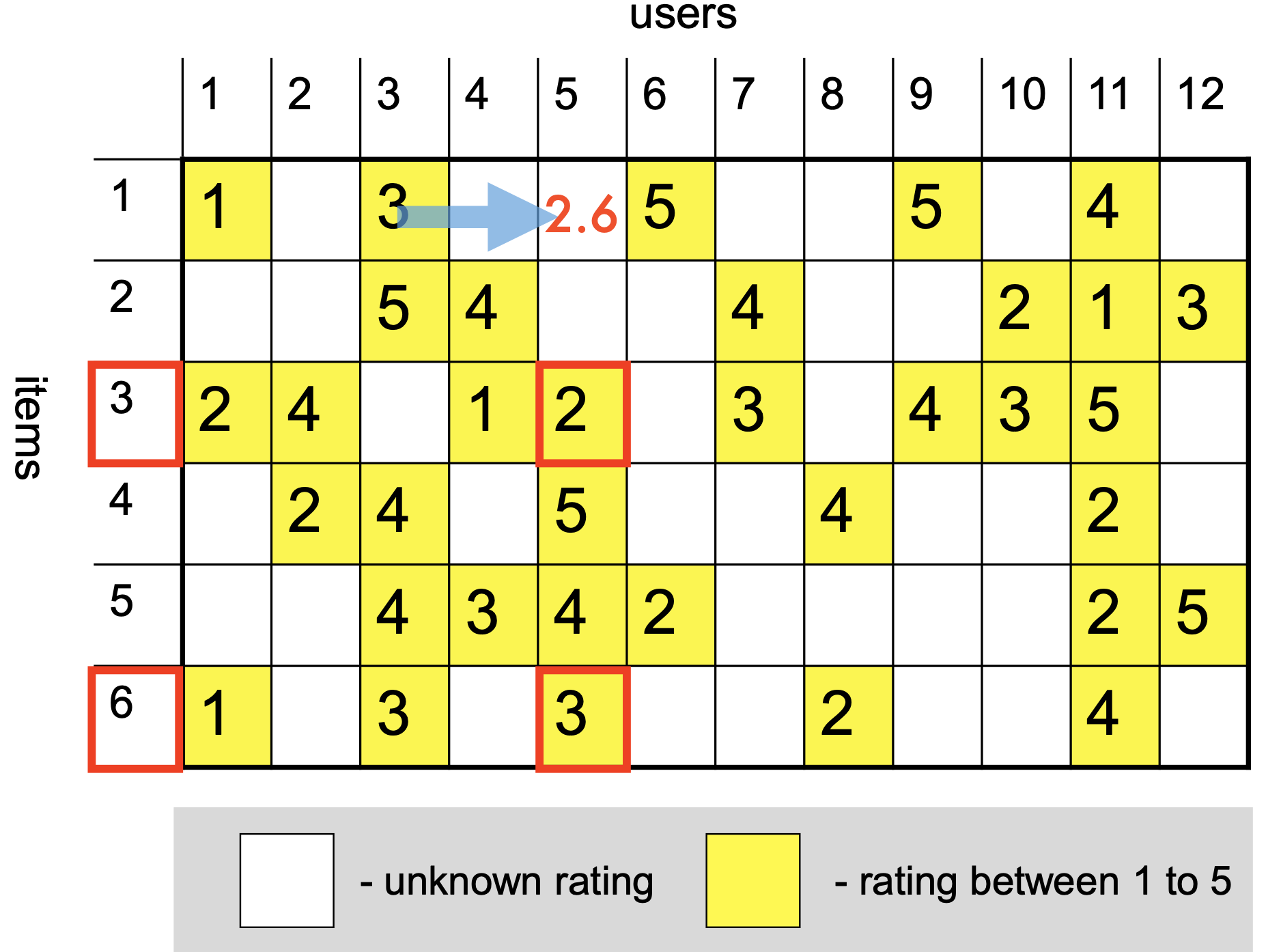
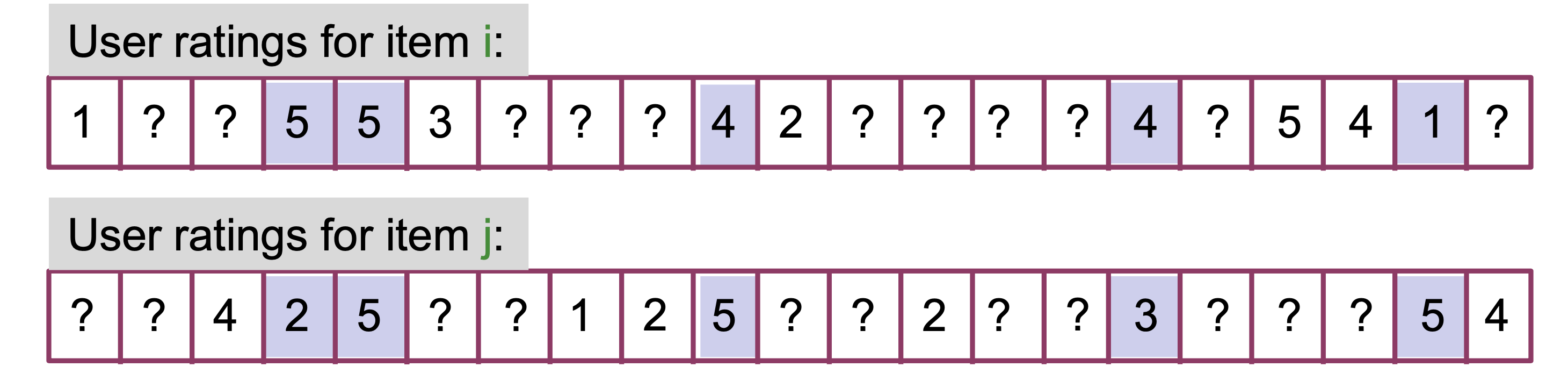
# Create new lists where only numbers are kept that are not np.nan in both listsfiltered_ratings_item_i = [rating_i for rating_i, rating_j inzip(ratings_item_i, ratings_item_j) ifnot np.isnan(rating_i) andnot np.isnan(rating_j)]filtered_ratings_item_j = [rating_j for rating_i, rating_j inzip(ratings_item_i, ratings_item_j) ifnot np.isnan(rating_i) andnot np.isnan(rating_j)]display(Markdown(f'Common ratings for item $i$: {filtered_ratings_item_i}'))display(Markdown(f'Common ratings for item $j$: {filtered_ratings_item_j}'))
Common ratings for item \(i\): [5, 5, 4, 4, 1]
Common ratings for item \(j\): [2, 5, 5, 3, 5]
Now we can compute the Pearson correlation coefficient:
The Pearson correlation coefficient, often denoted as \(r\), is a measure of the linear correlation between two variables \(X\) and \(Y\). It quantifies the degree to which a linear relationship exists between the variables. The value of \(r\) ranges from -1 to 1, where:
\(r = 1\) indicates a perfect positive linear relationship,
\(r = -1\) indicates a perfect negative linear relationship,
\(r = 0\) indicates no linear relationship.
The formula for the Pearson correlation coefficient is:
Where: - \(X_i\) and \(Y_i\) are the individual sample points, - \(\bar{X}\) and \(\bar{Y}\) are the means of the \(X\) and \(Y\) samples, respectively.
The Pearson correlation coefficient is sensitive to outliers and assumes that the relationship between the variables is linear and that the data is normally distributed.
Similarity for Binary Data
In some cases we will need to work with binary \(r_{ui}\).
For example, purchase histories on an e-commerce site, or clicks on an ad.
In this case, an appropriate replacement for Pearson \(r\) is the Jaccard similarity coefficient or Intersection over Union.
Here \(i \in R(u)\) means the set of items rated by user \(u\) and \(u \in R(i)\) means the set of users who have rated item \(i\) and \(|R(u)|\) is the number of ratings.
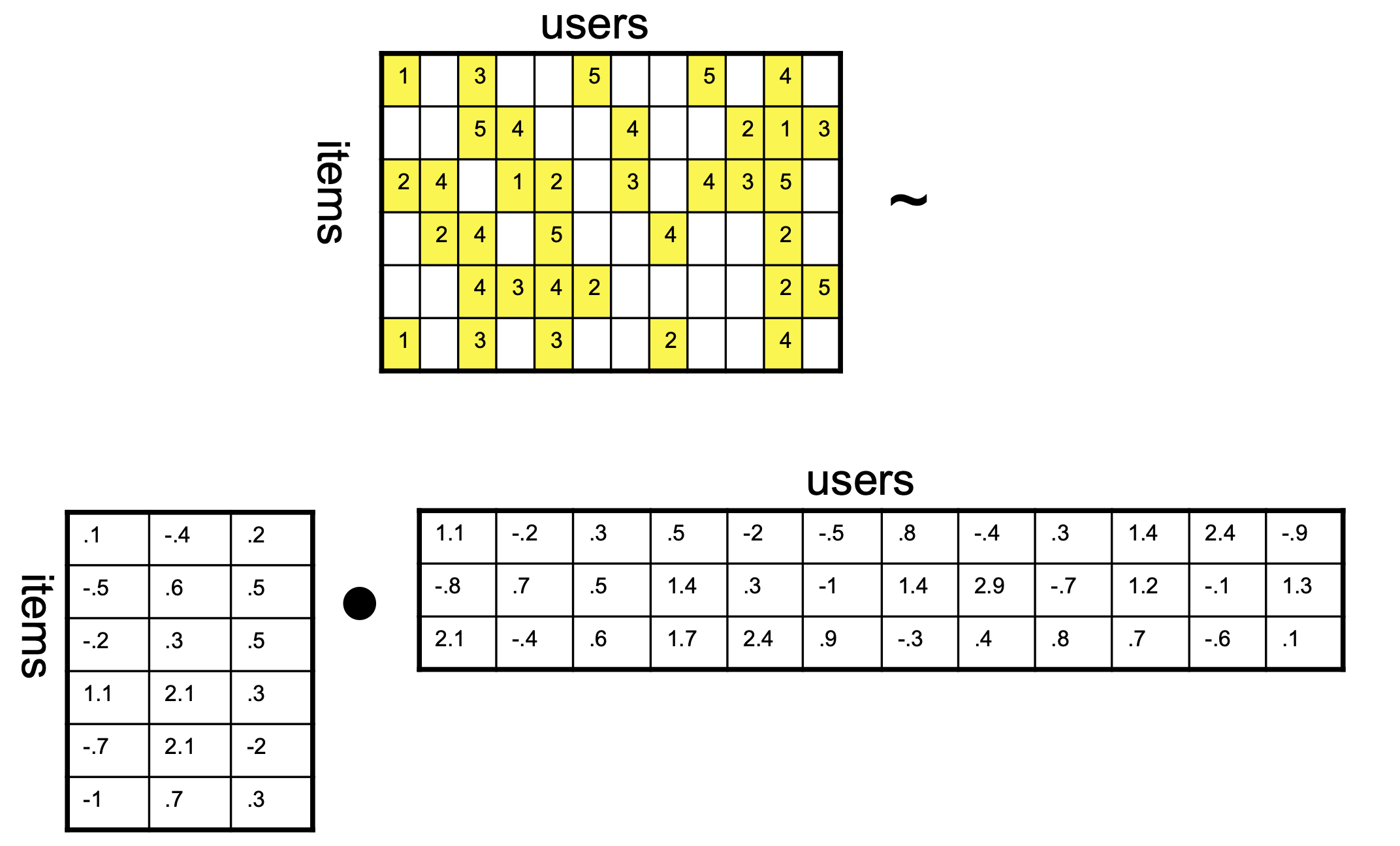
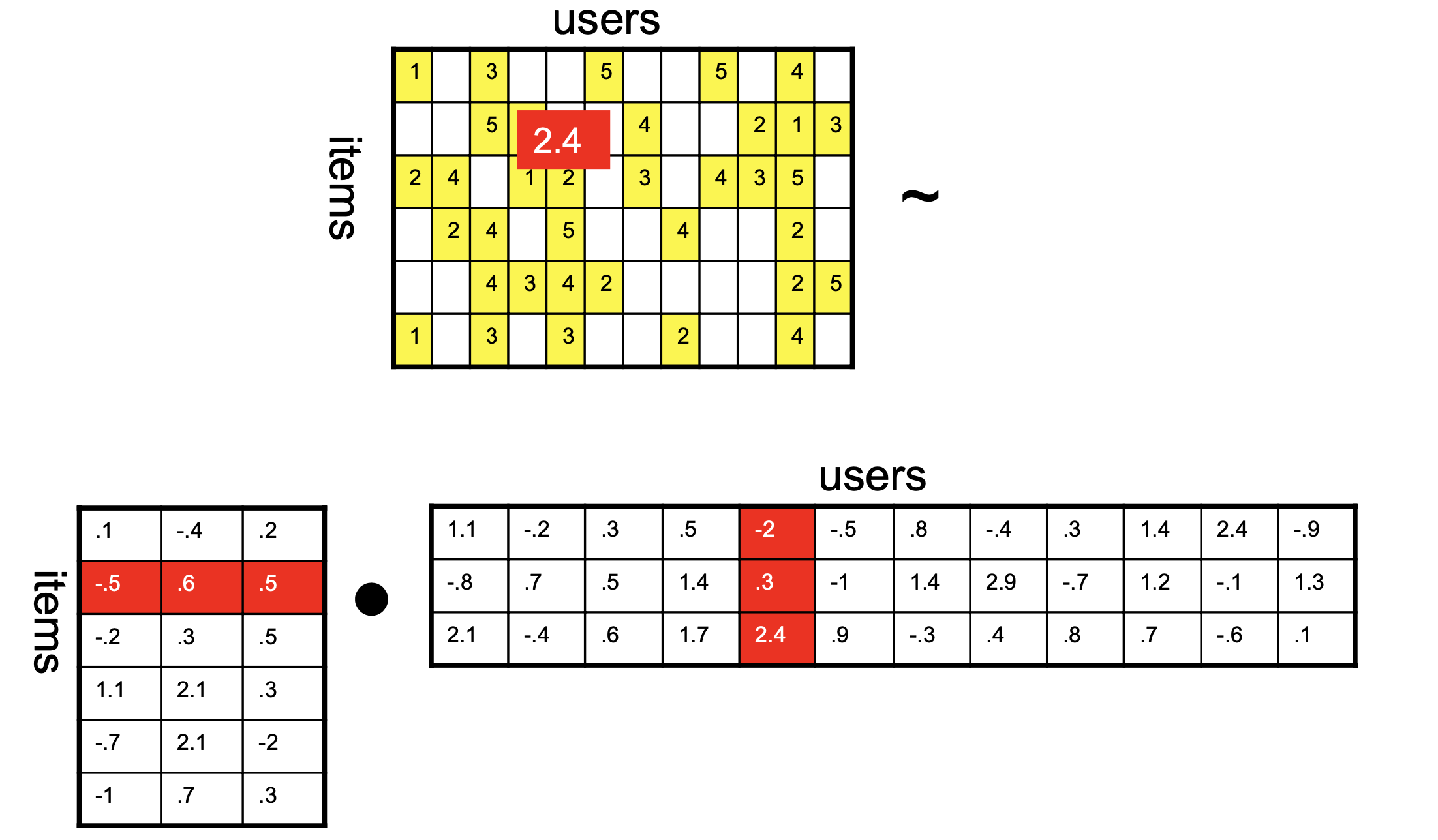
Now that we have learned the biases, we can do a better job of estimating correlation:
\(k\) is the rank of the factorization and dimensionality of the latent space.
The \((\cdot)_S\) notation means that we are only considering the subset of matrix entries that correspond to known reviews (the set \(S\)).
Note that as usual, we add \(\ell_2\) penalization to avoid overfitting (Ridge regression).
Once again, this problem is jointly convex in that it is convex in each of the variables \(U\) and \(V\).
In particular, if we hold either \(U\) or \(V\) constant, then the result is a simple ridge regression.
So one commonly used algorithm for this problem is called alternating least squares (ALS):
Hold \(U\) constant, and solve for \(V\)
Hold \(V\) constant, and solve for \(U\)
If not converged, go to Step 1.
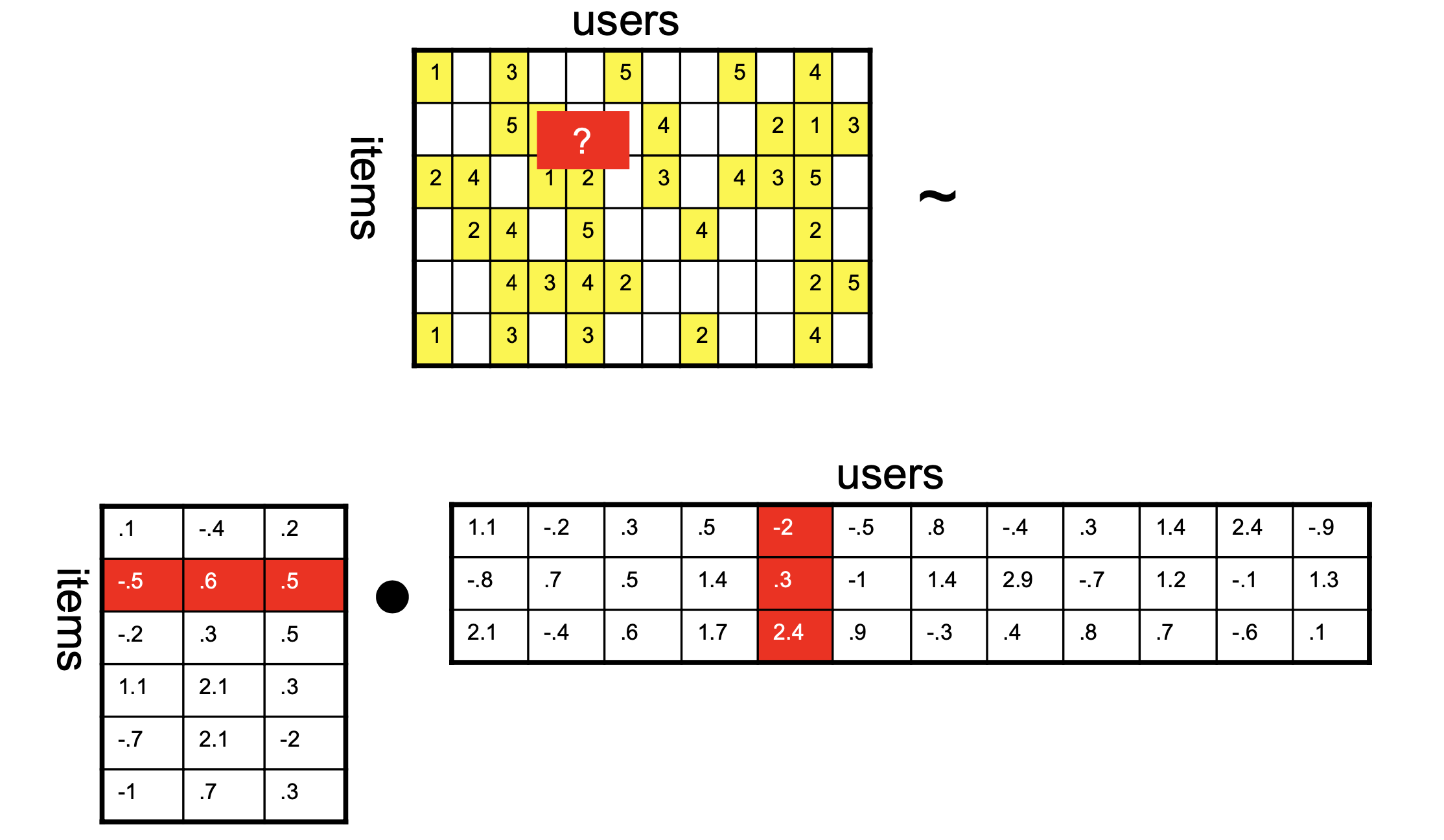
The only thing we’ve left out at this point is how to deal with the missing entries of \(R\).
It’s not hard, but the details aren’t that interesting, so we’ll give you code instead!
ALS in Practice
The entire Amazon reviews dataset is too large to work with easily, and it is too sparse.
Hence, we will take the densest rows and columns of the matrix.
Code
# The densest columns: products with more than 50 reviewspids = df.groupby('ProductId').count()['Id']hi_pids = pids[pids >50].index# reviews that are for these productshi_pid_rec = [r in hi_pids for r in df['ProductId']]# the densest rows: users with more than 50 reviewsuids = df.groupby('UserId').count()['Id']hi_uids = uids[uids >50].index# reviews that are from these usershi_uid_rec = [r in hi_uids for r in df['UserId']]# The result is a list of booleans equal to the number of rewviews# that are from those dense users and moviesgoodrec = [a and b for a, b inzip(hi_uid_rec, hi_pid_rec)]
Now we create a \(\textnormal{UserID} \times \textnormal{ProductID}\) matrix from these reviews.
# Import local python package MF.pyimport recommender_MF as MF# Instantiate the model# We are pulling these hyperparameters out of the air -- that's not the right way to do it!RS = MF.als_MF(rank =20, lambda_ =1)
Code
%time pred, error = RS.fit_model(R)
CPU times: user 31.3 s, sys: 1.58 s, total: 32.9 s
Wall time: 32.8 s
Code
print(f'RMSE on visible entries (training data): {np.sqrt(error/R.count().sum()):0.3f}')
RMSE on visible entries (training data): 0.343
And we can look at the predicted ratings matrix and see that it is a dense matrix:
Code
pred
ProductId
0005019281
0005119367
0307142485
0307142493
0307514161
0310263662
0310274281
0718000315
0764001035
0764003828
...
B00IKM5OCO
B00IWULQQ2
B00J4LMHMK
B00J5JSV1W
B00JA3RPAG
B00JAQJMJ0
B00JBBJJ24
B00JKPHUE0
B00K2CHVJ4
B00L4IDS4W
UserId
A02755422E9NI29TCQ5W3
4.901128
5.101293
5.124230
5.167632
5.264014
5.509682
5.019623
4.630935
4.324269
5.410814
...
3.931071
5.075952
5.371094
2.029338
4.793952
5.751275
5.055573
4.245653
3.910609
5.015350
A100JCBNALJFAW
4.031142
4.462234
3.075861
3.804829
4.471864
3.809544
4.381435
2.979852
3.261133
3.253135
...
3.127049
4.169933
1.678929
2.055047
2.772564
3.706830
3.107731
3.654849
1.916827
2.760760
A10175AMUHOQC4
4.647358
4.640926
4.548000
5.478397
5.087498
4.276774
4.729792
4.577080
5.469803
5.659700
...
4.183990
5.158620
5.547430
2.022941
3.922144
5.513525
4.721612
4.606729
3.861235
3.855086
A103KNDW8GN92L
4.601196
4.808000
4.028050
4.047650
3.320891
3.779980
4.328358
3.558697
3.458177
6.051367
...
3.377724
4.782034
4.561805
1.705925
4.585235
3.074747
3.597283
2.487920
3.741830
5.180065
A106016KSI0YQ
3.940547
3.758841
4.443953
4.960247
3.905060
3.533902
3.875516
3.851135
3.154589
4.576446
...
3.684078
4.510247
3.135226
1.913635
3.372981
3.755371
3.776432
3.224742
2.587647
2.744543
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
AZUBX0AYYNTFF
3.623108
4.195799
3.259184
4.362600
4.275729
3.316542
3.962883
3.308387
3.276024
4.812006
...
3.394854
3.926255
2.921070
1.338711
2.495747
4.264773
3.650783
2.810611
2.131493
3.223099
AZXGPM8EKSHE9
2.801357
3.712006
2.946317
3.989053
3.037111
4.899051
3.366558
3.124647
3.368960
4.354287
...
2.191798
3.152695
4.557602
0.832827
4.441145
3.403507
3.395606
3.397682
2.572013
3.865427
AZXHK8IO25FL6
3.206185
3.427266
3.533580
3.978738
3.569193
1.279516
3.312234
2.314085
3.451623
3.280554
...
2.218830
3.583831
1.944980
0.815382
3.028860
3.740974
1.404925
2.415937
-0.518910
1.556146
AZXR5HB99P936
4.110834
4.150344
3.031901
3.782407
4.470900
3.631913
4.119725
3.534826
3.758144
3.211057
...
3.240027
4.153761
2.854006
2.568058
2.882833
3.732649
3.244162
3.111499
2.400912
2.676788
AZZ4GD20C58ND
4.674770
4.905721
3.781878
3.892328
4.420746
4.790422
4.576695
3.470988
4.198702
3.515578
...
3.000951
4.495355
3.190370
2.837386
4.104762
3.374785
3.384070
4.392084
2.654402
3.320654
3677 rows × 7244 columns
Code
## todo: hold out test data, compute oos error# We create a mask of the known entries, then calculate the indices of the known# entries, then split that data into training and test sets.# Create a mask for the known entriesRN =~R.isnull()# Get the indices of the known entriesvisible = np.where(RN)# Split the data into training and test setsimport sklearn.model_selection as model_selectionX_train, X_test, Y_train, Y_test = model_selection.train_test_split(visible[0], visible[1], test_size =0.1)
Just for comparison’s sake, let’s check the performance of \(k\)-NN on this dataset.
Again, this is only on the training data – so overly optimistic for sure.
And note that this is a subset of the full dataset – the subset that is “easiest” to predict due to density.
Code
from sklearn.neighbors import KNeighborsClassifierfrom sklearn.metrics import mean_squared_error# Drop the columns that are not featuresX_train = good_df.drop(columns=['Id', 'ProductId', 'UserId', 'Text', 'Summary'])# The target is the scorey_train = good_df['Score']# Using k-NN on features HelpfulnessNumerator, HelpfulnessDenominator, Score, Timemodel = KNeighborsClassifier(n_neighbors=3).fit(X_train, y_train)%time y_hat = model.predict(X_train)
CPU times: user 2.4 s, sys: 44.9 ms, total: 2.45 s
Wall time: 2.42 s
Code
print(f'RMSE on visible entries (test set): {np.sqrt(mean_squared_error(y_train, y_hat)):.3f}')
RMSE on visible entries (test set): 0.649
Assessing Matrix Factorization
Matrix Factorization per se is a good idea.
However, many of the improvements we’ve discussed for CF apply to MF as well.
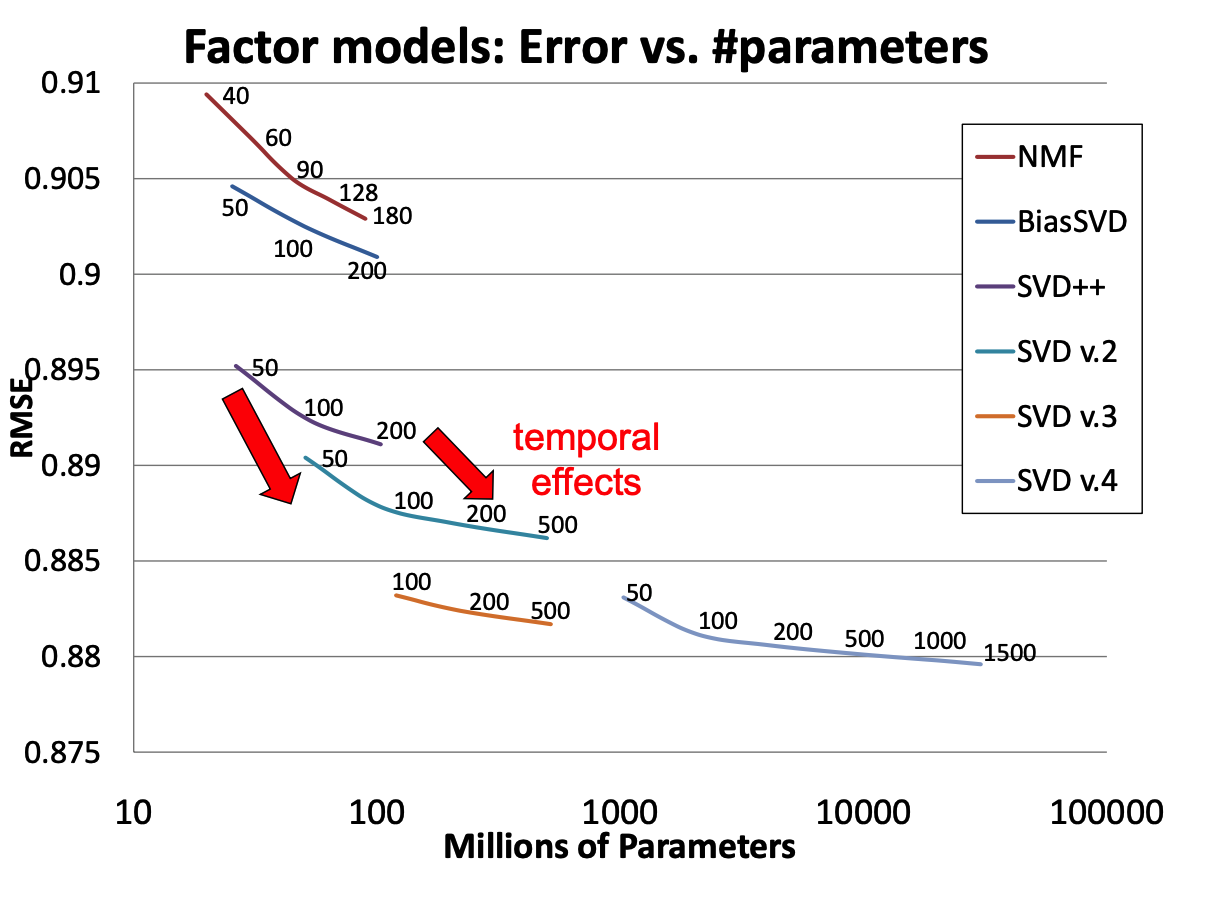
To illustrate, we’ll look at some of the successive improvements used by the team that won the Netflix prize (“BellKor’s Pragmatic Chaos”).
When the prize was announced, the Netflix supplied solution achieved an RMSE of 0.951.
By the end of the competition (about 3 years), the winning team’s solution achieved RMSE of 0.856.
Let’s restate our MF objective in a way that will make things clearer:
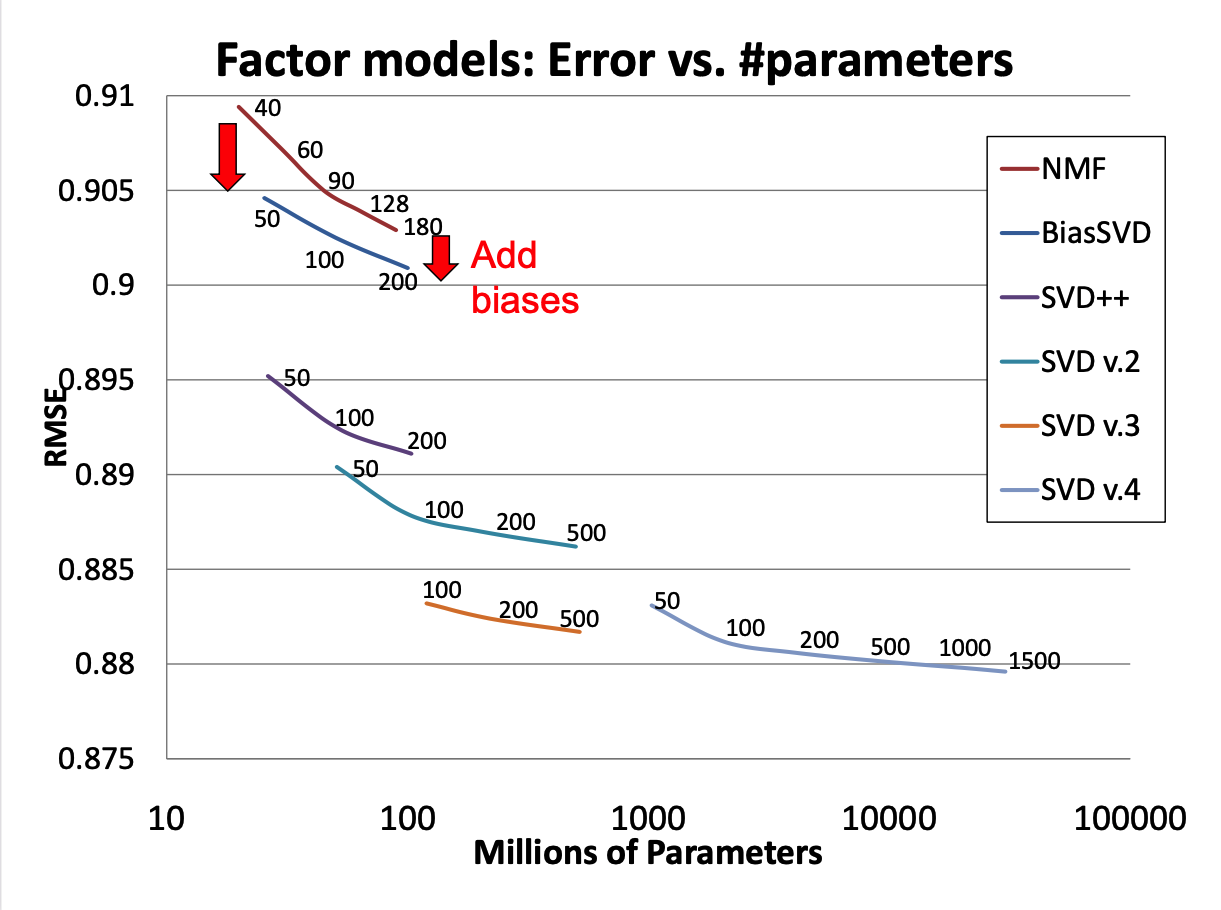
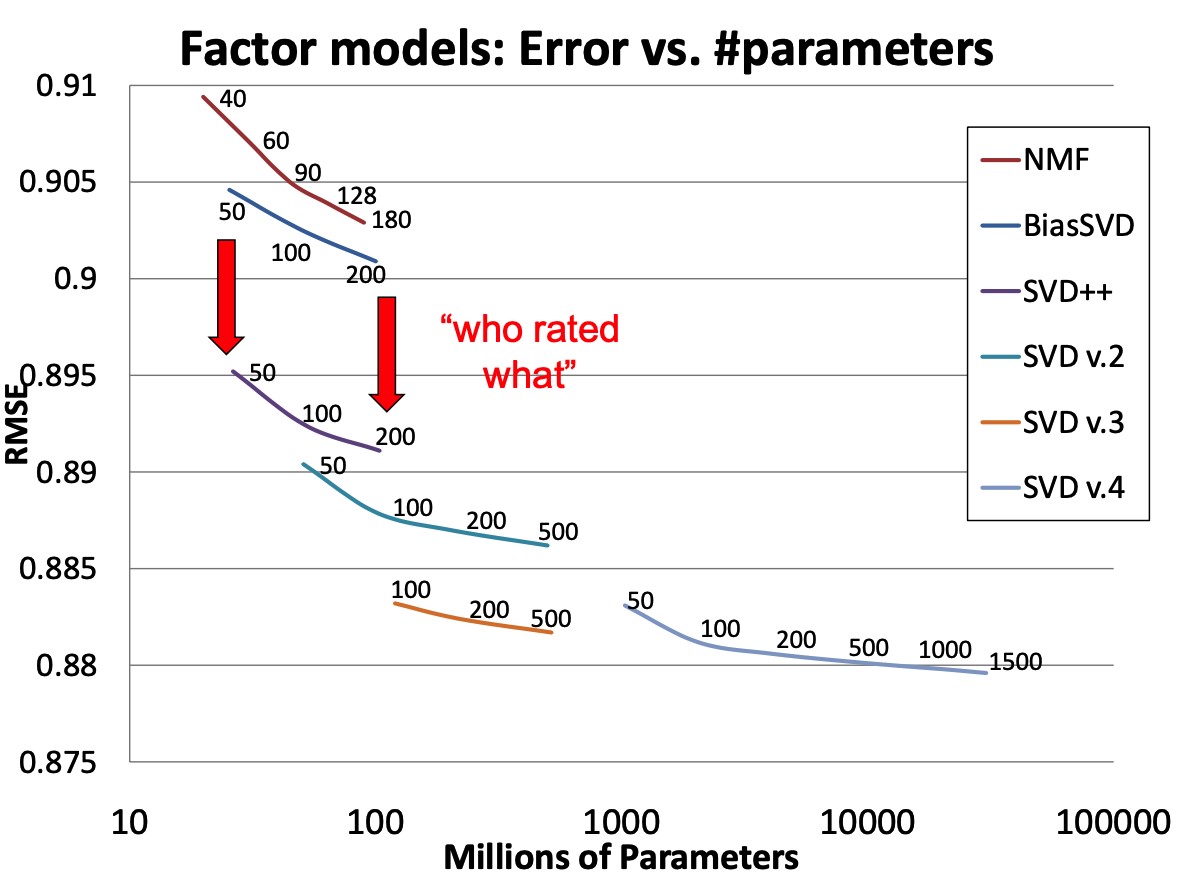
Figure 2: Matrix factorization models’ accuracy. The plots show the root-mean-square error of each of four individual factor models (lower is better). Accuracy improves when the factor model’s dimensionality (denoted by numbers on the charts) increases. In addition, the more refined factor models, whose descriptions involve more distinct sets of parameters, are more accurate.
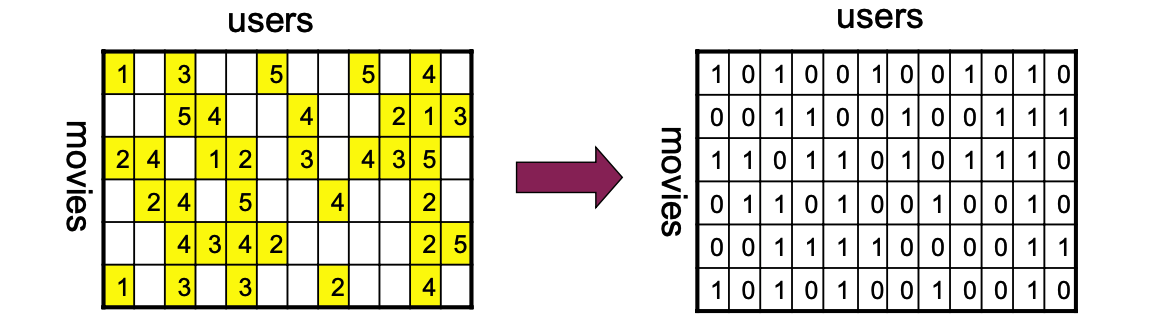
2. Who Rated What?
In reality, ratings are not provided at random.
Take note of which users rated the same movies (ala CF) and use this information.
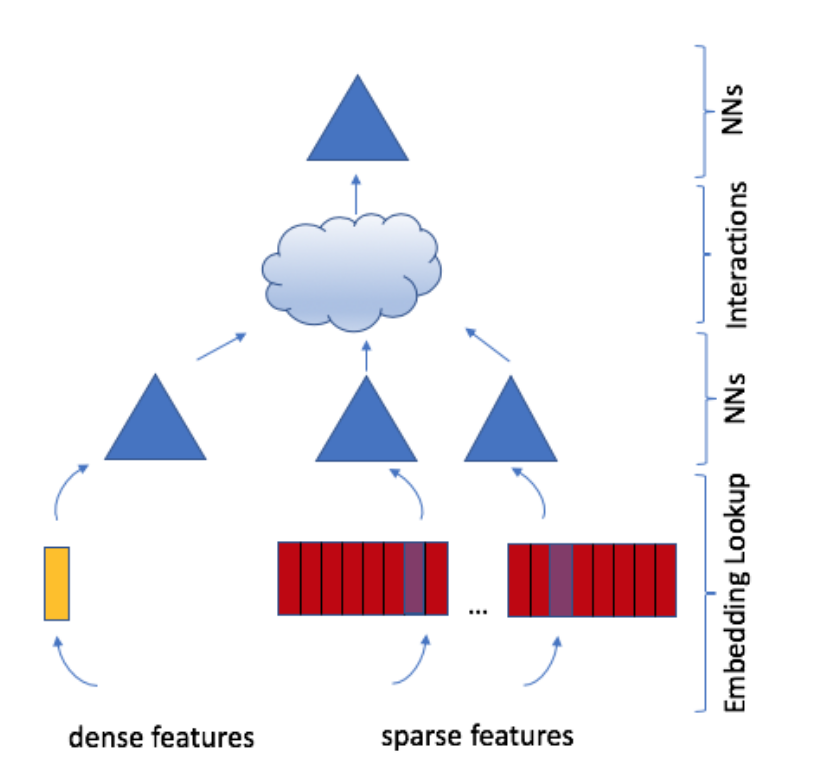
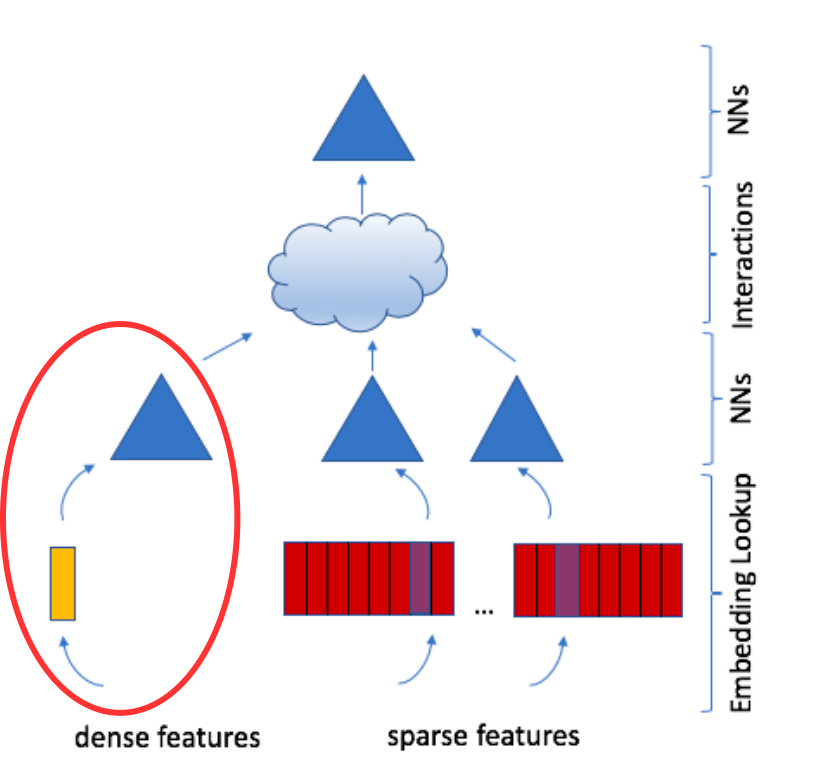
Embeddings: Dense representations for categorical data.
Bottom MLP: Transforms dense continuous features.
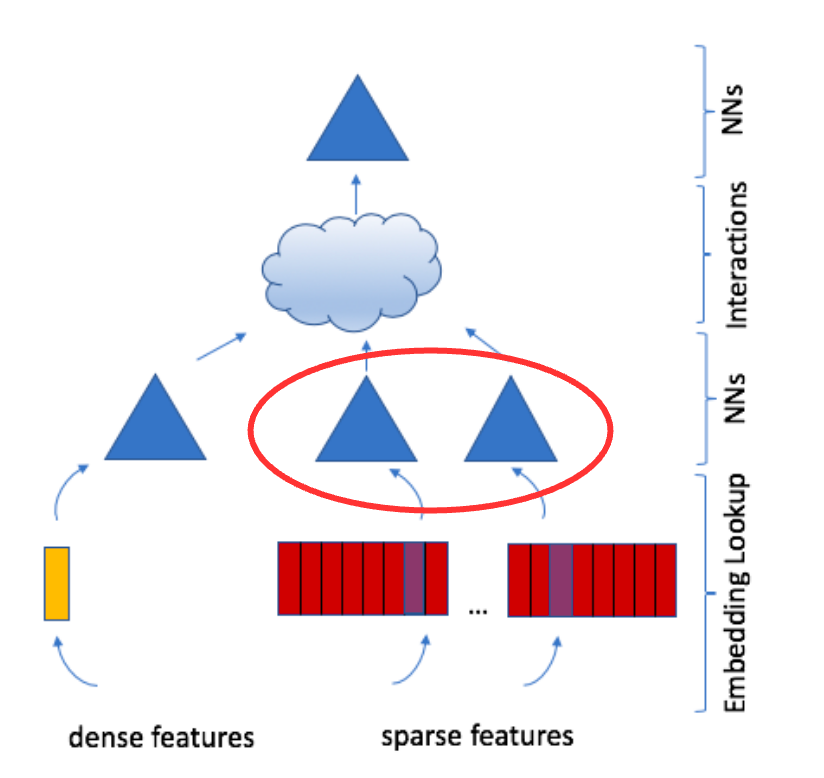
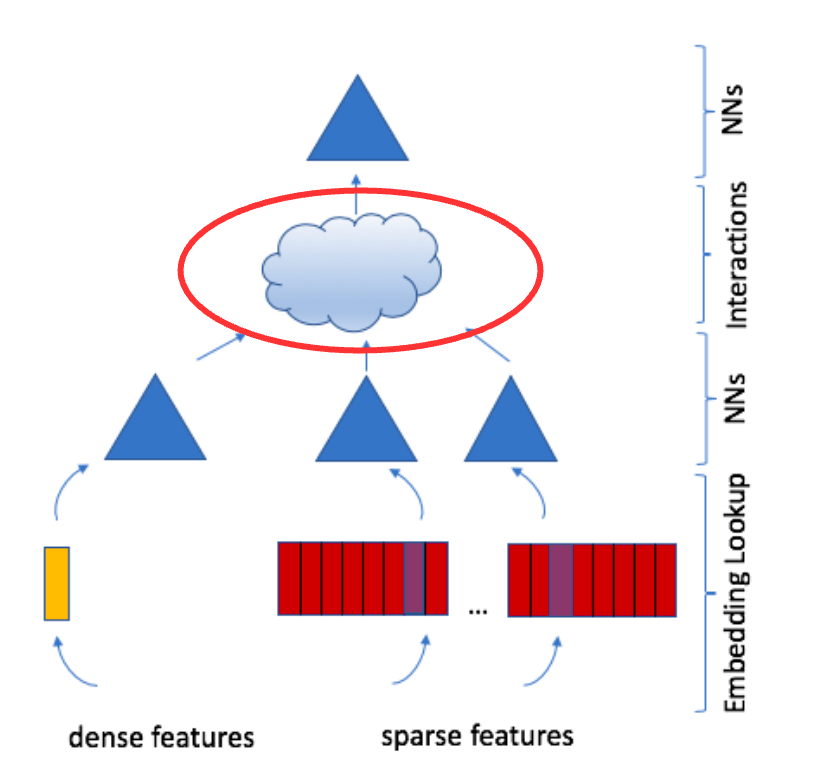
Feature Interaction: Dot-product of embeddings and dense features.
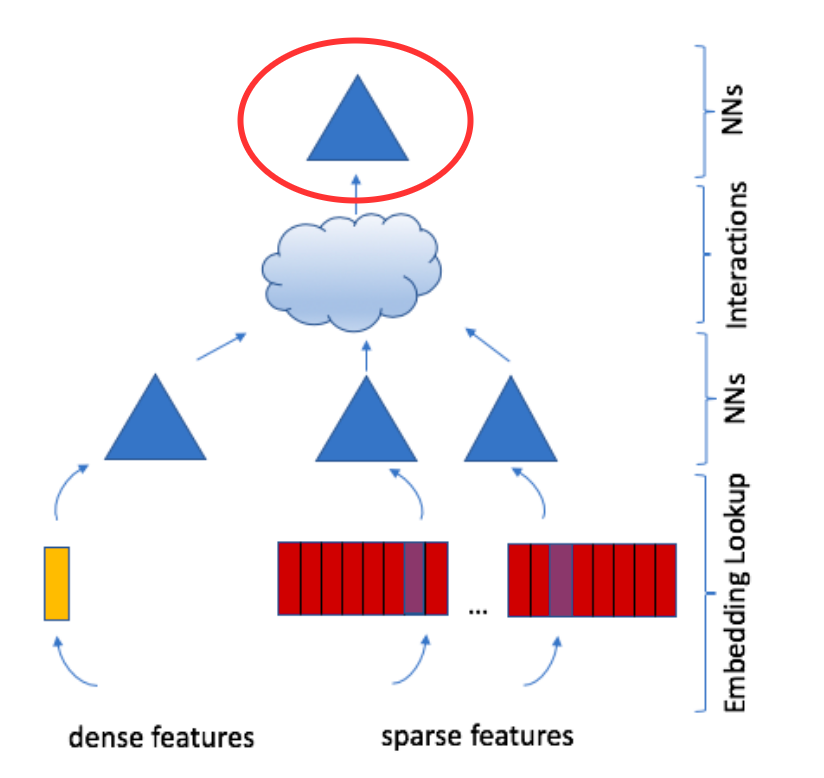
Top MLP: Processes interactions and outputs probabilities.
Figure 3: DLRM Architecture
Let’s look at each of these components in turn.
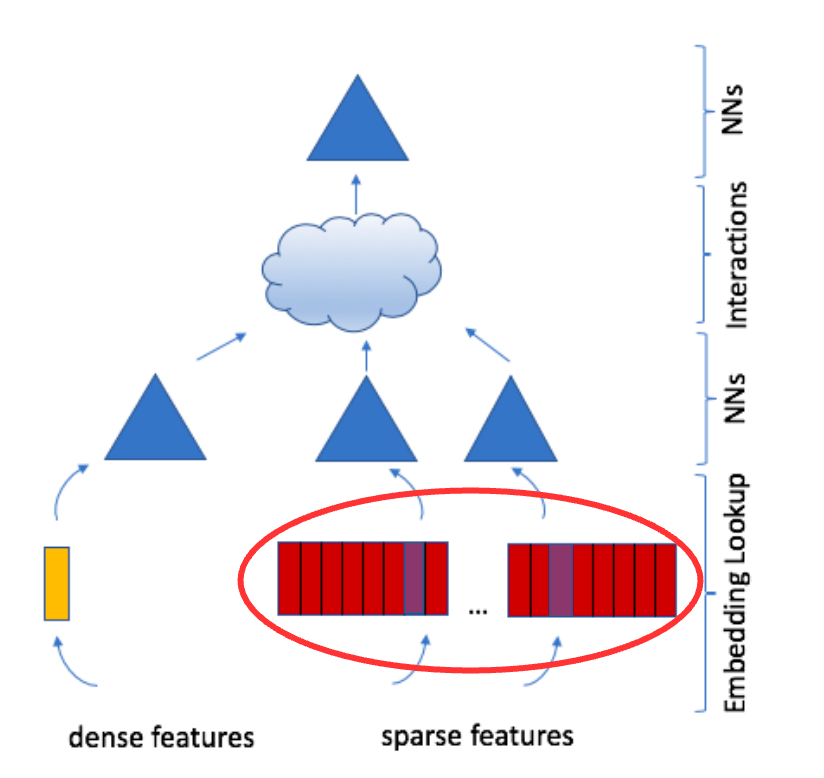
Embeddings
Embeddings: Map categorical inputs to latent factor space.
A learned embedding matrix \(W \in \mathbb{R}^{m \times d}\) for each category of input
One-hot vector \(e_i\) with \(i\text{-th}\) entry 1 and rest are 0s
Embedding of \(e_i\) is \(i\text{-th}\) row of \(W\), i.e., \(w_i^T = e_i^T W\)
We can also use weighted combination of multiple items with a multi-hot vector of weights \(a^T = [0, ..., a_{i_1}, ..., a_{i_k}, ..., 0]\).
The embedding of this multi-hot vector is then \(a^T W\).
DLRM Architecture
PyTorch has a convenient way to do this using EmbeddingBag, which besides summing can combine embeddings via mean or max pooling.
Here’s an example with 5 embeddings of dimension 3:
Code
import torchimport torch.nn as nn# Example embedding matrix: 5 embeddings, each of dimension 3embedding_matrix = nn.EmbeddingBag(num_embeddings=5, embedding_dim=3, mode='mean')# Input: Indices into the embedding matrixinput_indices = torch.tensor([1, 2, 3, 4]) # Flat list of indicesoffsets = torch.tensor([0, 2]) # Start new bag at position 0 and 2 in input_indices# Forward passoutput = embedding_matrix(input_indices, offsets)print("Embedding Matrix:\n", embedding_matrix.weight)print("Output:\n", output)
The advantage of the DLRM architecture is that it can take continuous features as input such as the user’s age, time of day, etc.
There is a bottom MLP that transforms these dense features into a latent space of the same dimension \(d\).
DLRM Architecture
Optional Sparse Feature MLPs
Optionally, one can add MLPs to transform the sparse features as well.
DLRM Architecture
Feature Interactions
The 2nd order interactions are modeled via dot-products of all pairs from the collections of embedding vectors and processed dense features.
The results of the dot-product interactions are concatenated with the processed dense vectors.
DLRM Architecture
Top MLP
The concatenated vector is then passed to a final MLP and then to a sigmoid function to produce the final prediction (e.g., probability score of recommendation)
This entire model is trained end-to-end using standard deep learning techniques.
There are a number of concerns with the widespread use of recommender systems and personalization in society.
First, recommender systems are accused of creating filter bubbles.
A filter bubble is the tendency for recommender systems to limit the variety of information presented to the user.
The concern is that a user’s past expression of interests will guide the algorithm in continuing to provide “more of the same.”
This is believed to increase polarization in society, and to reinforce confirmation bias.
Second, recommender systems in modern usage are often tuned to maximize engagement.
In other words, the objective function of the system is not to present the user’s most favored content, but rather the content that will be most likely to keep the user on the site.
The incentive to maximize engagement arises on sites that are supported by advertising revenue.
More engagement time means more revenue for the site.
However, many studies have shown that sites that strive to maximize engagement do so in large part by guiding users toward extreme content:
content that is shocking,
or feeds conspiracy theories,
or presents extreme views on popular topics.
Given this tendency of modern recommender systems, for a third party to create “clickbait” content such as this, one of the easiest ways is to present false claims.
Methods for addressing these issues are being very actively studied at present.
Ways of addressing these issues can be:
via technology
via public policy
Recap and References
BU CS/CDS Research
You can read about some of the work done in Professor Mark Crovella’s group on this topic:
Introduction to recommender systems and their importance in modern society.
Explanation of collaborative filtering (CF) and its two main approaches: user-user similarity and item-item similarity.
Discussion on the challenges of recommender systems, including scalability and data sparsity.
Introduction to matrix factorization (MF) as an improvement over CF, using latent vectors and alternating least squares (ALS) for optimization.
Practical implementation of ALS for matrix factorization on a subset of Amazon movie reviews.
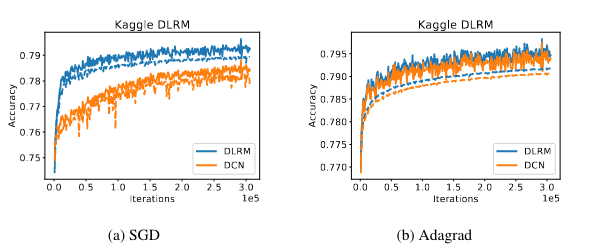
Review of Deep Learning Recommender Model (DLRM) architecture and its components.
Discussion on the societal impact of recommender systems, including filter bubbles and engagement maximization.
References
Koren, Yehuda. 2009. “Collaborative Filtering with Temporal Dynamics.” In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 42:447–56. 8. https://dl.acm.org/doi/10.1145/1557019.1557072.
Koren, Yehuda, Robert Bell, and Chris Volinsky. 2009. “Matrix Factorization Techniques for Recommender Systems.”Computer 42 (8): 30–37. https://ieeexplore.ieee.org/document/5197422.
Naumov, Maxim et al. 2019. “Deep Learning Recommendation Model for Personalization and Recommendation Systems.”arXiv Preprint arXiv:1906.00091, May. http://arxiv.org/abs/1906.00091.